作者:微信小助手
发布时间:2019-06-03T18:38:26
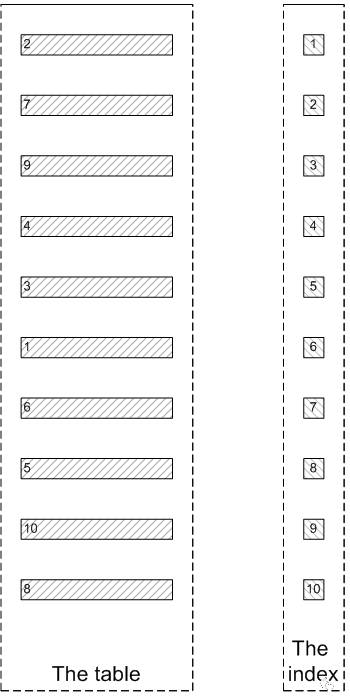
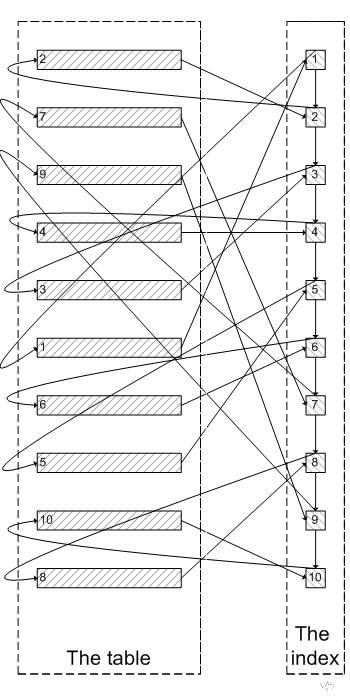
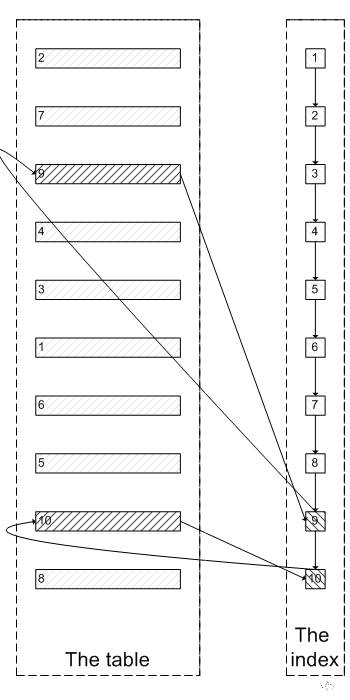
yangyidba | 作者 一 背景 大部分开发和DBA同行都对分页查询非常非常了解,看帖子翻页需要分页查询,搜索商品也需要分页查询。那么问题来了,遇到上千万或者上亿的数据量怎么快速的拉取全量,比如大商家拉取每月千万级别的订单数量到自己独立的ISV做财务统计;或者拥有百万千万粉丝的公众大号,给全部粉丝推送消息的场景。本文讲讲个人的优化分页查询的经验,抛砖引玉。 在讲如何优化之前我们先来看看一个比较常见错误的写法 该SQL是一个非常典型的排序+分页查询: order by col limit N,M MySQL 执行此类SQL时需要先扫描到N行,然后再去取M行。对于此类操作,获取前面少数几行数据会很快,但是随着扫描的记录数越多,SQL的性能就会越差,因为N的值越大,MySQL需要扫描越多的数据来定位到具体的N行,这样耗费大量的 IO 成本和时间成本。一图胜千言,我们使用简单的图来解释为什么 上面的sql 的写法扫描数据会慢。 t 表是一个索引组织表,key idxkidtype(kid,type) 。 符合kid=3 and type=1 的记录有很多行,我们取第 9,10行。 select * from t where kid =3 and type=1 order by id desc 8,2; MySQL 是如何执行上面的sql 的?对于Innodb表,系统是根据 idxkidtype 二级索引里面包含的主键去查找对应的行。对于百万千万级别的记录而言,索引大小可能和数据大小相差无几,cache在内存中的索引数量有限,而且二级索引和数据叶子节点不在同一个物理块儿上存储,二级索引与主键的相对无序映射关系,也会带来大量的随机IO请求,N值越大越需要遍历大量索引页和数据叶,需要耗费的时间就越久。 鉴于上面的大分页查询耗费时间长的原因,我们思考一个问题,是否需要完全遍历“无效的数据”?如果我们需要limit 8,2;我们跳过前面8行无关的数据页遍历,可以直接通过索引定位到第9,第10行,这样操作是不是更快了?依然是一图胜千言,通过这其实也是 延迟关联的 核心思思:通过使用覆盖索引查询返回需要的主键,再根据主键关联原表获得需要的数据,而不是通过二级索引获取主键再通过主键去遍历数据页。 通过上面的原理分析,我们知道通过常规方式进行大分页查询慢的原因,也知道了提高大分页查询的具体方法 ,下面我们讨论一下在线上业务系统中常用的解决方法。 针对limit 优化有很多种方式: 1 前端加缓存、搜索,减少落到库的查询操作。比如海量商品可以放到搜索里面,使用瀑布流的方式展现数据,很多电商网站采用了这种方式。2 优化SQL 访问数据的方式,直接快速定位到要访问的数据行。3 使用书签方式 ,记录上次查询最新/大的id值,向后追溯 M行记录。对于第二种方式 我们推荐使用"延迟关联"的方法来优化排序操作,何谓"延迟关联" :通过使用覆盖索引查询返回需要的主键,再根据主键关联原表获得需要的数据。 优化前 其执行时间: 优化后:
二 分析
SELECT * FROM tablewhere kid=1342 and type=1 order id asc limit 149420 ,20;
三 实践出真知
3.1 延迟关联
root@xxx 12:33:48>explain SELECT id, cu_id, name, info, biz_type, gmt_create, gmt_modified,start_time, end_time, market_type, back_leaf_category,item_status,picuture_url FROM relation where biz_type ='0' AND end_time >='2014-05-29' ORDER BY id asc LIMIT 149420 ,20;+----+-------------+-------------+-------+---------------+-------------+---------+------+--------+-----+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------------+-------+---------------+-------------+---------+------+--------+-----+| 1 | SIMPLE | relation | range | ind_endtime | ind_endtime | 9 | NULL | 349622 | Using where; Using filesort |+----+-------------+-------------+-------+---------------+-------------+---------+------+--------+-----+1 row in set (0.00 sec)
root@xxx 12:33:43>explain SELECT a.*