作者:微信小助手
发布时间:2025-04-16T14:15:50
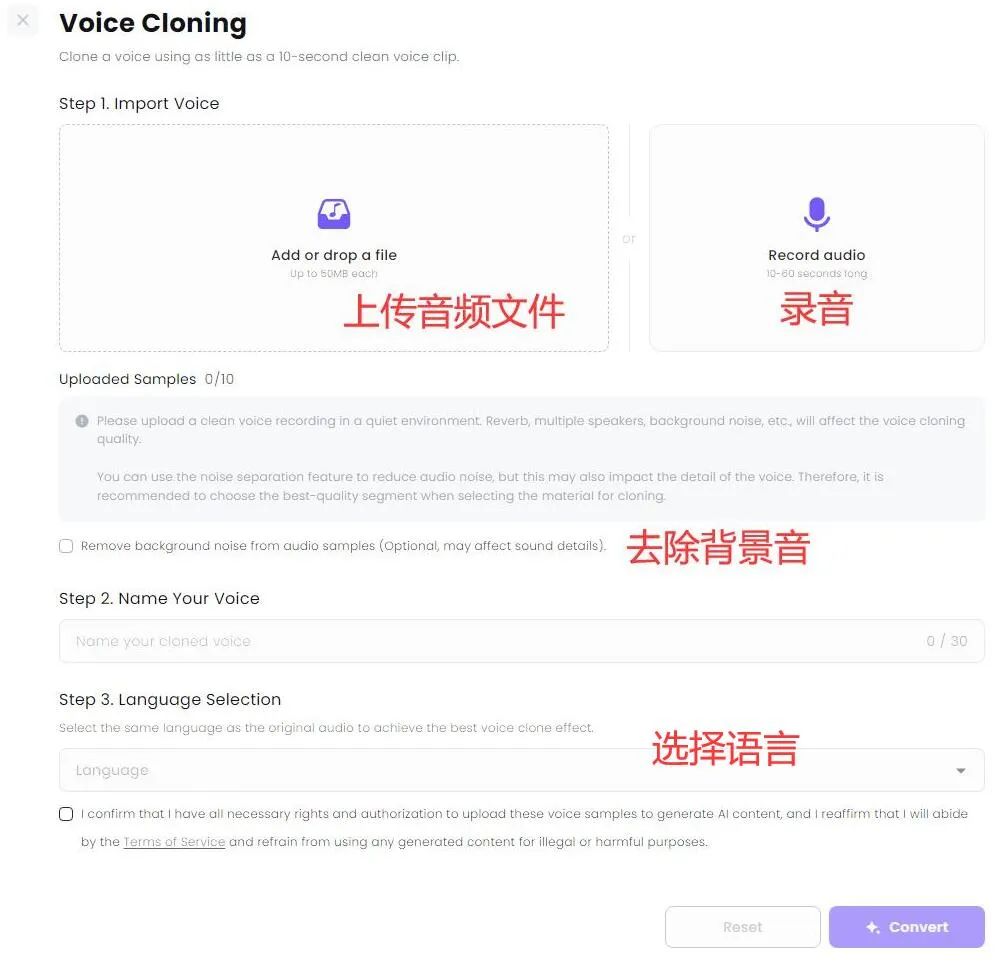
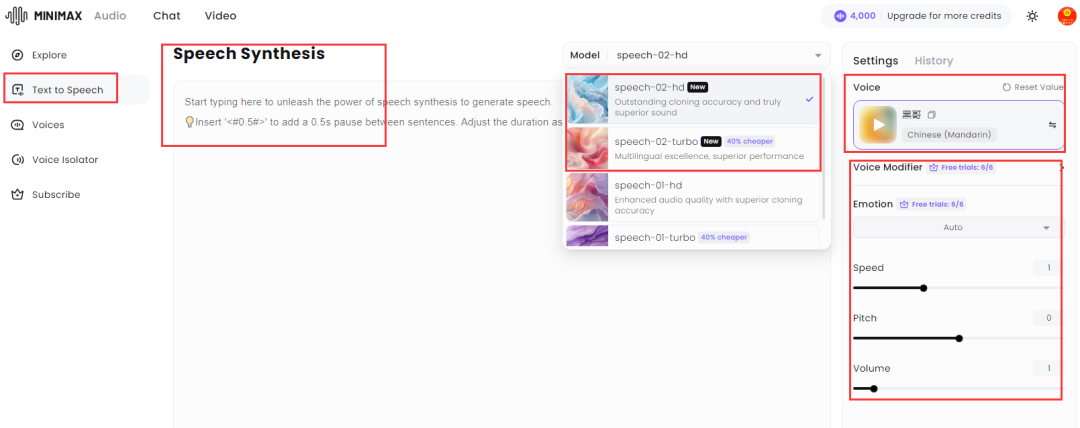
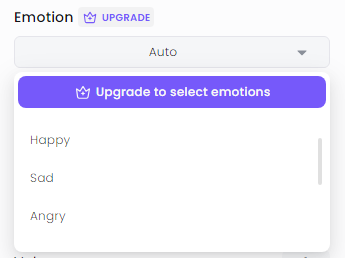
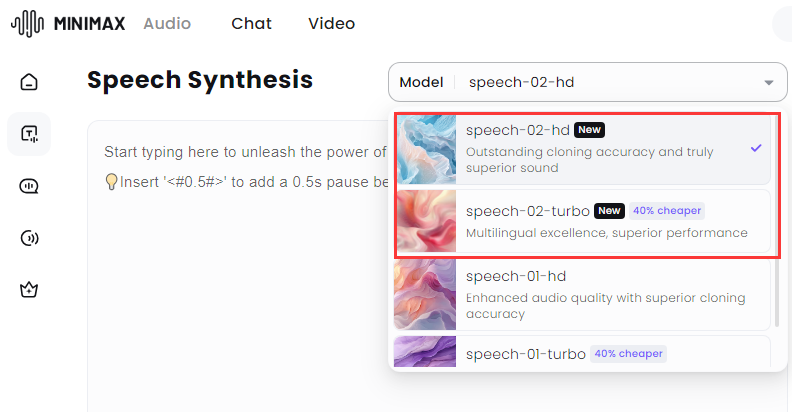
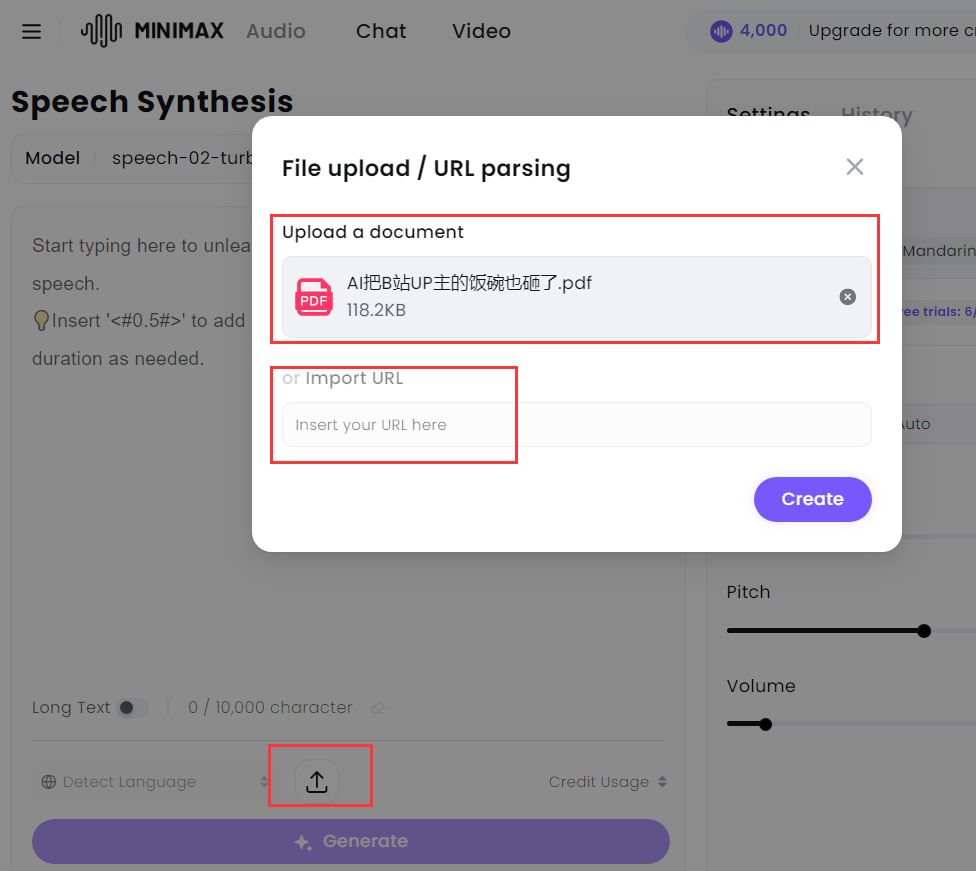
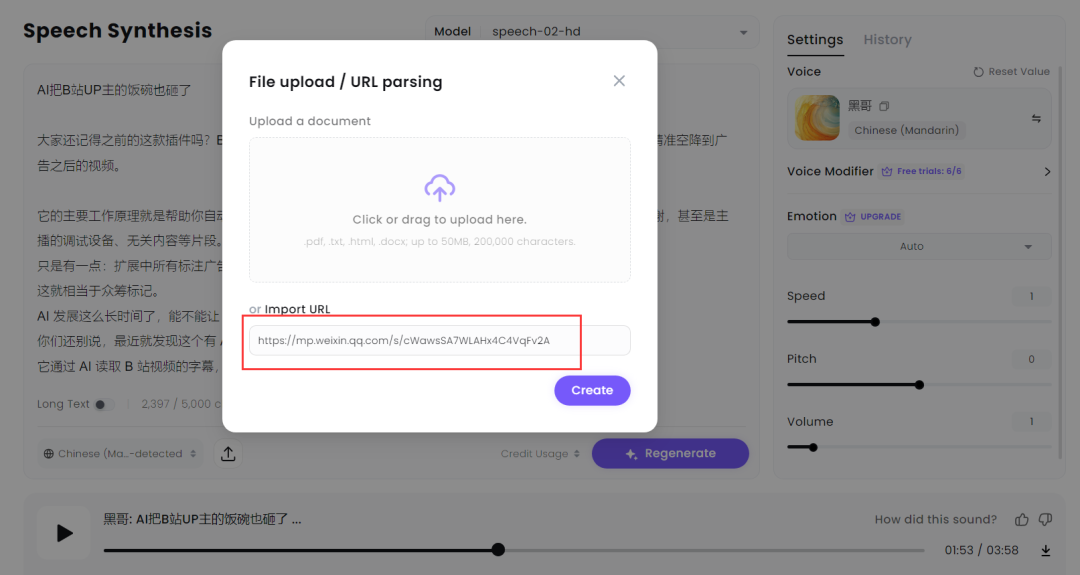
之前我不是做 B 站吗?录视频解说的时候真的挺麻烦,老是读错字,还费时间。 所以我一直对语音克隆工具关注有加,最近又发现一个新升级的克隆利器,让它帮我念台词,大家听听效果怎么样? 我去,我自己听了都愣住了。也太像了吧。。。 我让媳妇听了之后,一开始她还真没听出来,不仅音色一致,语调有抑扬顿挫,停顿也都非常自然。 再对比一下原视频解说声音,怎么样,这个 AI 帮忙念的解说词和原声相比,也许最大的差别就是没有背景音乐了吧。 AI 克隆了我的声音后,还能用来说粤语、英语。生成的其它方言和语言不仅完全保持了原有的音色,说的也非常自然、流畅。 比之前体验过的,包括目前市面不少声音克隆 AI 工具效果不要好太多。 好了,该引出正主了,我用的是 MiniMax Audio 刚上新的 Speech-02 模型克隆的。 说起来 MiniMax,也是国内 AI 六小龙之一的实力选手。海螺 AI 就是 MiniMax 公司的产品之一。 不过这次国内版的 Speech-02 模型还没有上线,也不支持声音克隆,所以大家只能先用海外版了,官网「需魔法」: https://www.minimax.io/audio 内置语音库、克隆声音快 MiniMax Audio 内置了丰富的语音库,差不多有 300 多种,各种语言和各种年龄、风格的都有,质量非常高,都可以直接拿来用。 这么多,都够给一部电视剧所有演员配音了吧。 英文咱就不听了,听几个中文的。 如果需要克隆新的声音,就要点击「Create your Voice Clone」,也就是创建克隆声音。 然后上传一段音频或者自己录音。至少 10 秒以上吧,也不需要太长,一二十 秒就差不多了。 如果上传的声音有背景音乐,这肯定会影响克隆声音效果的。 而 MiniMax Audio 还支持上传声音的同时去除背景音,勾选那个「去除背景音」就行。 这点真的很赞,不然还得另外找工具把背景音乐和人声分离。 最后选择需要生成的语音种类,再点击「Convert」就开始克隆了。 我从点击开始到生成克隆的声音真的快,大概也就 10 秒时间。 真的挺快!不禁感叹,语音克隆这个玩法现在是真的有手就会,完全是 0 门槛了。 支持生成 30多种语言,可调节音色 这还只是第一步,声音克隆之后,它会存到语音库。 如果想要克隆出的声音说出其他话,还得再输入文本,然后在语音库里选择刚才克隆的声音就可以了。 在文本生成声音的时候,还可以对生成的声音效果进行调节,比如速度、音量等等。 什么带情绪的也可以,比如高兴、悲伤、生气等等。 在左下角生成语言选项那里,可以看到,它除了可以生成中文普通话外,还能生成粤语方言以及英语、日语等 30 多种语言。 而且不管你克隆的声音说什么语言的,都能生成其它不同的语言。 所以在生成的时候有两个模型可供选择:Speech-02-hd、Speech-02-turbo。 这两个有什么区别呢? Speech-02-hd 主要是用在声音克隆方面,生成一些小语种声音的话,建议使用 Speech-02-turbo。 生成不同的语言时注意不要选错。 我用它克隆了几个大家都算比较熟悉的声音,然后再和原声对比,大家就更能体验到 MiniMax Audio 的声音克隆能力有多强了! 第一组:董卿声音
第二组:王明军朗读《三体》
第三组:步非烟声音
怎么样,这一番对比下来,有没有一种那根本不是 AI 克隆的声音,它就是原声的感觉? 因为实在是太像了,甚至都基本一模一样了。 PDF 、网页链接转语音 MiniMax 除了支持文字转语音之外,还可以支持 PDF 文档和网页链接直接转语音。 得,又给我们省了一步操作。。。 现在公众号不是支持听文章了嘛?是方便不少,你看也有小伙伴在用这个功能,但我老觉得它听起来比较生硬。 那我就把这篇文章的链接放进去。 大家再听下,是不是比公众号自带的朗读效果要好多了,虽然说情感缺乏一些起伏,但是音色是真的像,这是真的得服。 你要知道,这仅用了 10 秒的语料,仅花了 10 秒就能达到的效果。 同时我也发现,虽然它识别网页链接后的文字有空行,但它生成语音的时候会智能忽略掉,也就是中间不会因为有空行而停顿那么长时间。 另外,它还支持长文本模式,最高可输入 20 万字符。 这差不多是一本有声书的体量了,当然这么多的字符必须得另外「加钱」了。 目前的话,普通用户每天登录可免费领 4000 积分,可支持能够制作出 5 分钟的音频,如果只是浅玩体验一下,也差不多够了。 结语 体验了 MiniMax Audio 的 Speech-02 模型后,不得不说又把语音克隆又往前推上了新高度。 无论是声音克隆的精准度、多语言支持的广泛性,还是生成语音的自然流畅度,都远超市面上大多数同类产品。 最关键的是,0 门槛就能做出这种效果,要知道之前还都得用 GPT-SoVITS 这种开源工具手搓出来,现在直接全省了。。。 目前到这个阶段,在音色克隆这方面,大家基本上已经卷得差不多了。 再往下的新的突破点,那大概就是大模型根据文本包含的语义来自行调整语音情感和腔调了,到了那个时候,可能我们就真的无法再分辨真人和 AI 的语音了。