作者:微信小助手
发布时间:2025-04-04T06:58:31
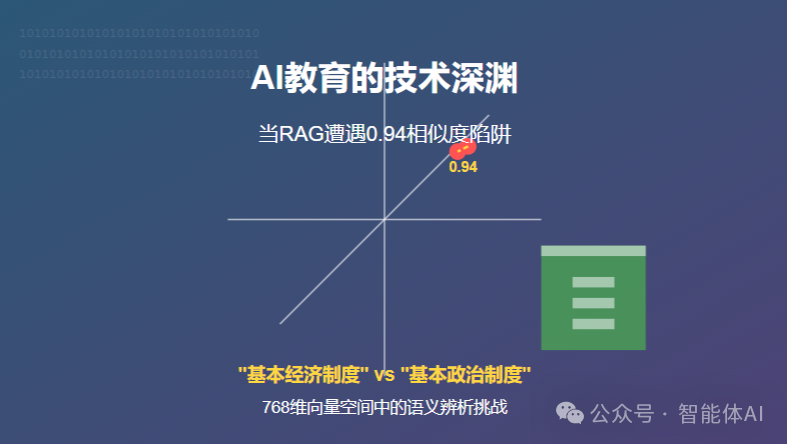
以为把AI变成"教育通"只需要喂题库?当RAG技术遭遇"基本经济制度"和"基本政治制度"的0.94相似度陷阱时,开发者才会惊觉:教育领域的知识检索,远非向量匹配那般简单。在这片看似题库铺就的坦途上,Embedding模型正在经历着比高考数学压轴题更严酷的语义辨析考验——当两个专业术语的余弦相似度突破0.9,人类教师秒懂的差异,AI却要经历"Embedding初筛+Reranker精排"的双重淬炼才能勉强分辨。今天,让我们撕开RAG在教育领域"即插即用"的伪装,直面那隐藏在768维向量空间里的技术深渊。
一、为什么RAG在教育行业如鱼得水?
教育行业有一个天然优势:题库资源。互联网上存在海量的题目、答案和解析,而且这些资源已经按照明确的知识结构被组织好了。每个题目对应一个答案和解析,这种天然的一对一关系,为RAG技术提供了绝佳的应用场景。
RAG技术简述:RAG结合了检索系统和生成式AI的优势,先从知识库中检索相关信息,再基于检索结果生成回答,保证AI回答既有创造性,又有事实依据。
与其他行业相比,教育行业的知识片段不需要复杂的切分和整理工作。当学生提出问题时,系统只需识别出对应的题目,就能立即找到相关的答案和解析,进而生成高质量的回复。即使面对复杂的数学公式,现代多模态模型(如GPT-4o)也能将图片转化为文字版本,进而实现知识检索。这意味着,无论是文字题、数学公式,还是物理图表,RAG技术都能驾驭自如。
二、RAG技术在教育中的"滑铁卢"

然而,技术从不是完美无缺的。
以下面这个初中政治知识的真实案例为例:
问题:我国社会主义初级阶段的基本经济制度是什么?这一制度的确立有什么意义?
检索结果Top3:
我国社会主义初级阶段的基本政治制度是人民代表大会制度。它体现了人民当家作主的社会主义民主政治本质,保障了广大人民群众的民主权利。(相似度0.94)
公有制为主体、多种所有制经济共同发展是我国社会主义初级阶段的基本经济制度。这一制度的确立有利于解放和发展社会生产力,促进经济持续健康发展。(相似度0.89)
我国的基本经济制度是在社会主义条件下发展市场经济,处理好政府与市场的关系,更好发挥政府作用。(相似度0.86)
看到问题了吗?正确答案(公有制为主体、多种所有制经济共同发展)排在了第二位!而排名第一的答案虽然文字相似度高达0.94,但实际上回答的是"基本政治制度"而非"基本经济制度",完全是不同的知识点。
这就是RAG技术在实际应用中的典型问题:
相似文本的语义区分困难:在"基本经济制度"和"基本政治制度"这样的概念中,Embedding模型难以区分关键的语义差异。
知识库大小的悖论:直觉上,知识库越大,覆盖场景越多,回答准确率应该越高。但实际情况却往往相反 —— 随着知识片段增多,检索准确率反而下降了。
三、为何会出现这些问题?Embedding模型的秘密
要理解RAG的局限性,我们需要了解Embedding模型的工作原理。
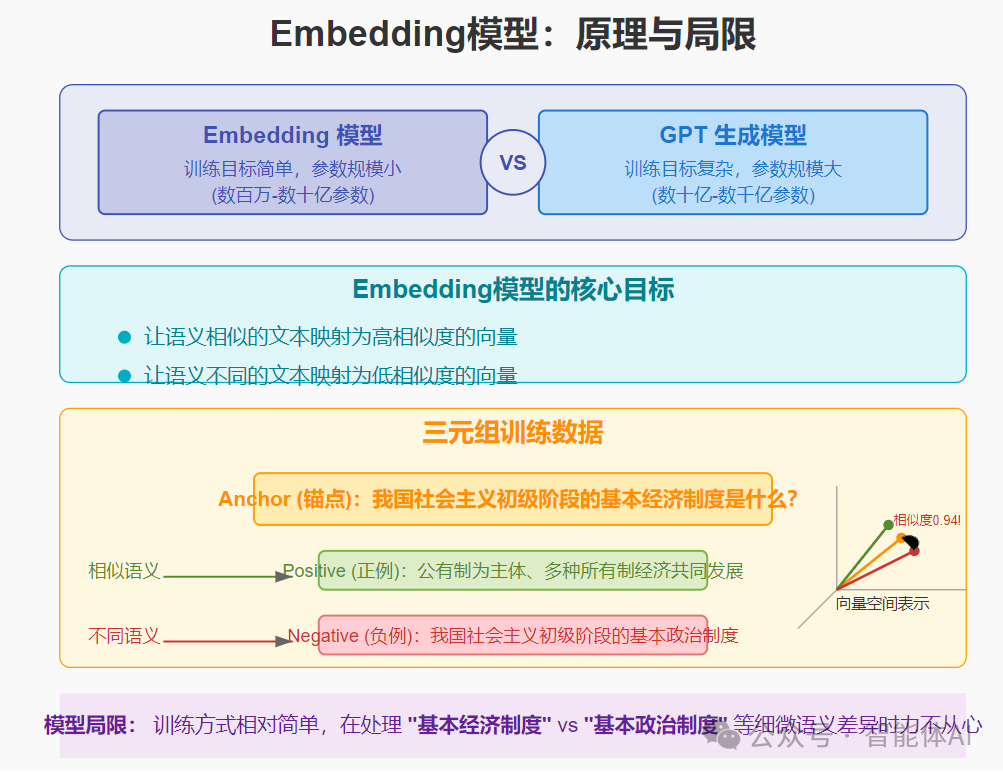
Embedding模型也是基于Transformer架构的语言模型,它与GPT等生成模型在理解语义方面的原理相似。但有一个关键区别:训练目标更简单,参数规模更小。
Embedding模型的核心目标是:
让语义相似的文本映射为高相似度的向量
让语义不同的文本映射为低相似度的向量
它通过数亿条三元组数据训练而成,每条数据包含:
Anchor(锚点):核心文本
Positive(正例):与锚点语义相似的文本
Negative(负例):与锚点语义不同的文本
然而,正是这种相对简单的训练方式,导致模型在处理细微语义差异时力不从心。当知识库规模扩大,包含更多相似但语义不同的内容时,准确率自然下降。
四、解决之道:Embedding+Reranker双模型协作
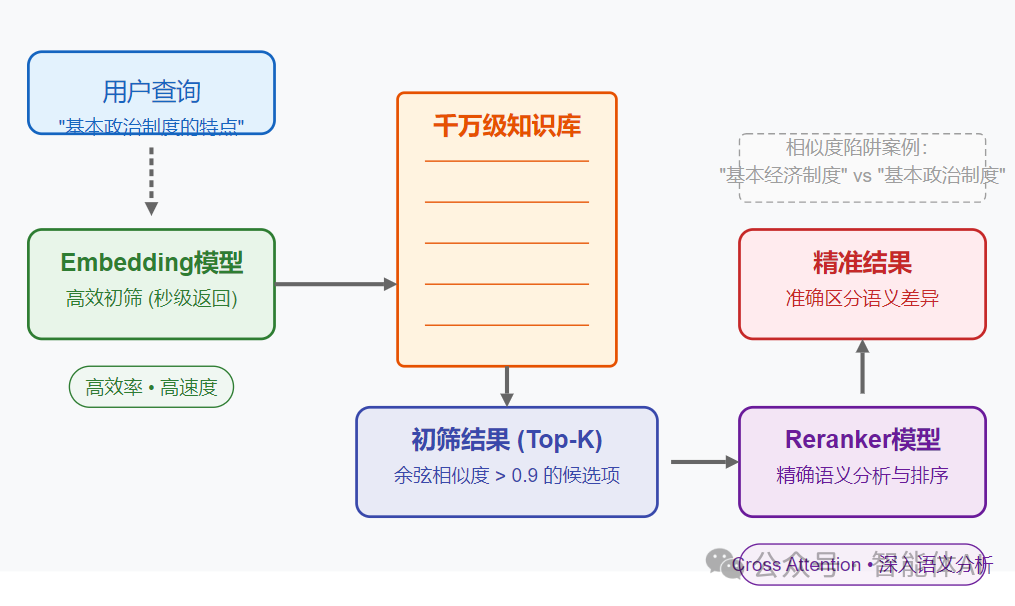
面对RAG的局限性,业内已经形成了一种共识:双模型协作是提升检索质量的有效方法。
1、Embedding模型:快速初筛
Embedding模型负责高效率、高速度的初步检索。它能在千万级知识库中秒级返回相似度较高的Top-K结果。
2、Reranker模型:精确排序
Reranker模型则负责对初筛结果进行更严谨、更深入的语义分析和重新排序。它通常使用Cross Attention机制,能更准确地捕捉查询与候选片段之间的语义关联。
目前市场上有多种优秀的模型可选:
智源人工智能研究院:BGE(BAAI General Embedding)
网易:BCE(Bilingual and Crosslingual Embedding)
阿里:Qwen GTE
腾讯:Conan-embedding
五、技术进阶:如何持续提升RAG效果?
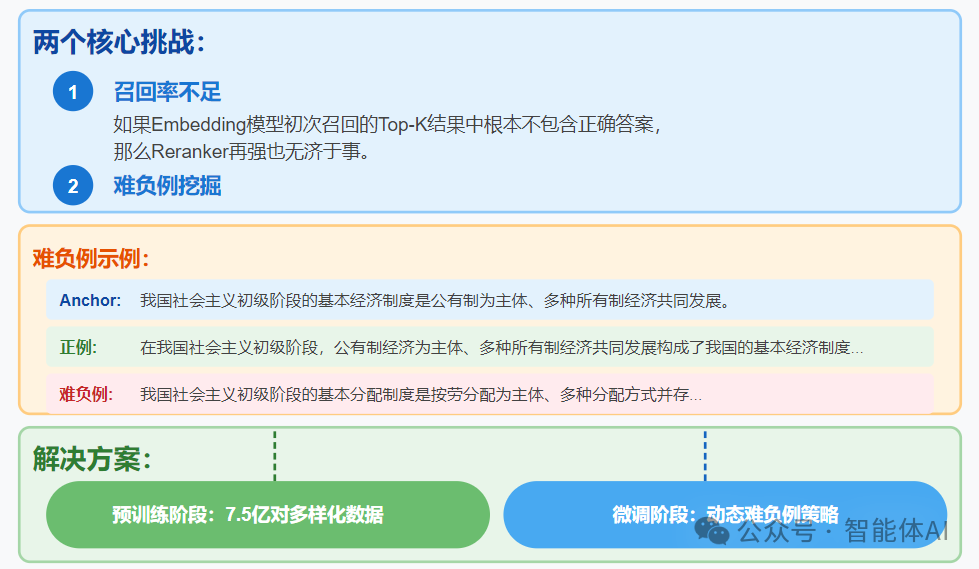
即使应用了双模型方案,我们仍然面临两个核心挑战:
1. 召回率不足
如果Embedding模型初次召回的Top-K结果中根本不包含正确答案,那么Reranker再强也无济于事。
2. 难负例挖掘
简单负例(如"社会主义经济制度"vs"资本主义政治制度")容易区分,但难负例则考验模型能力。例如:
难负例示例:
Anchor: 我国社会主义初级阶段的基本经济制度是公有制为主体、多种所有制经济共同发展。
正例: 在我国社会主义初级阶段,公有制经济为主体、多种所有制经济共同发展构成了我国的基本经济制度,这有利于解放和发展生产力。
难负例: 我国社会主义初级阶段的基本分配制度是按劳分配为主体、多种分配方式并存,这与我国的基本经济制度相适应,共同促进社会公平和经济发展。
注意这个难负例同样涉及"社会主义初级阶段"和"基本制度"的概念,但指的是"分配制度"而非"经济制度",这类细微差异往往难以被模型准确识别。
解决方案:
1)、预训练阶段:使用7.5亿对多样化数据(包括标题-内容对、问答对等)
2)、微调阶段:采用动态难负例策略
筛选与查询相似度高的负例
为每个查询动态生成更多难负例
不断更新训练数据,提升模型判别能力
六、垂直领域的Embedding微调
通过领域特定数据强化语义关联,提升检索精度(如教育题库匹配、医疗诊断精准度),对于教育等垂直领域,领域适应性的Embedding模型尤为重要。
微调的核心在于关联性数据:
教育领域:题目-解析对
医疗领域:症状-诊断方法对
法律领域:案情-判决对
与对话式模型相比,Embedding模型的微调安全性更高,不会产生不当内容,这对教育行业尤为重要。
七、总结
那些宣称"三天搭建智能答疑系统"的方案,往往在真实教学场景中暴露出惊人的脆弱性——就像在政治例题中,系统可能把"基本经济制度"和"基本政治制度"混为一谈,而这种错误在考试中将是致命的。教育AI的真正突围,需要开发者深入理解动态难负例挖掘的奥秘,掌握Cross Attention机制的精准调控,更要懂得如何让7.5亿训练对数据在垂直领域焕发生机。当你在GitHub上轻松clone某个RAG项目时,请记住:RAG的知识服务,从来都不是简单的向量游戏,而是一场关于语义粒度的纳米级战争。