作者:微信小助手
发布时间:2025-03-21T09:43:05
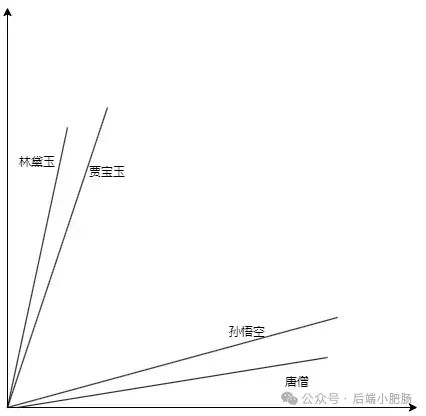
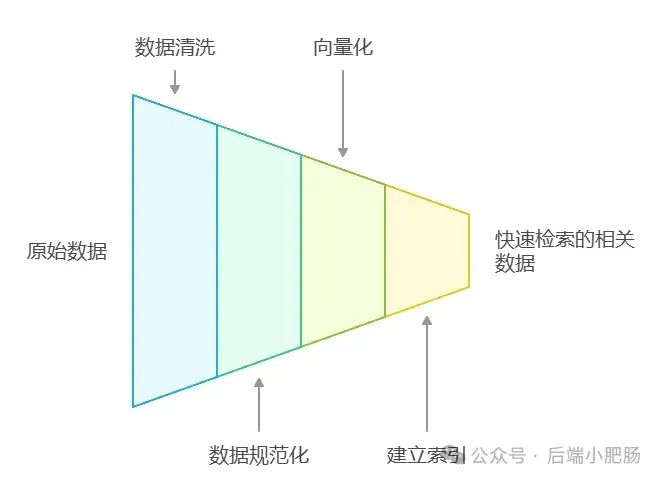
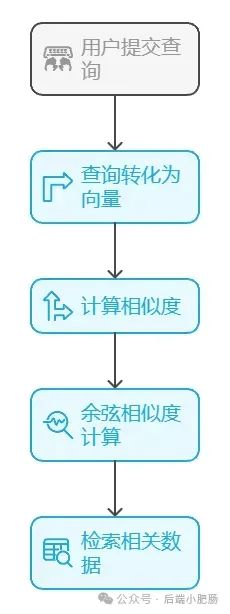
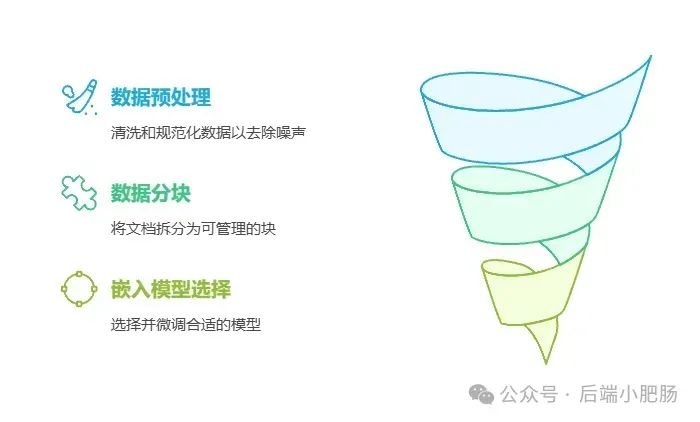
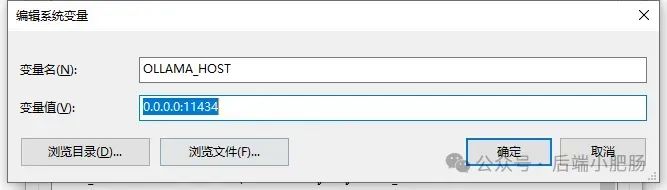
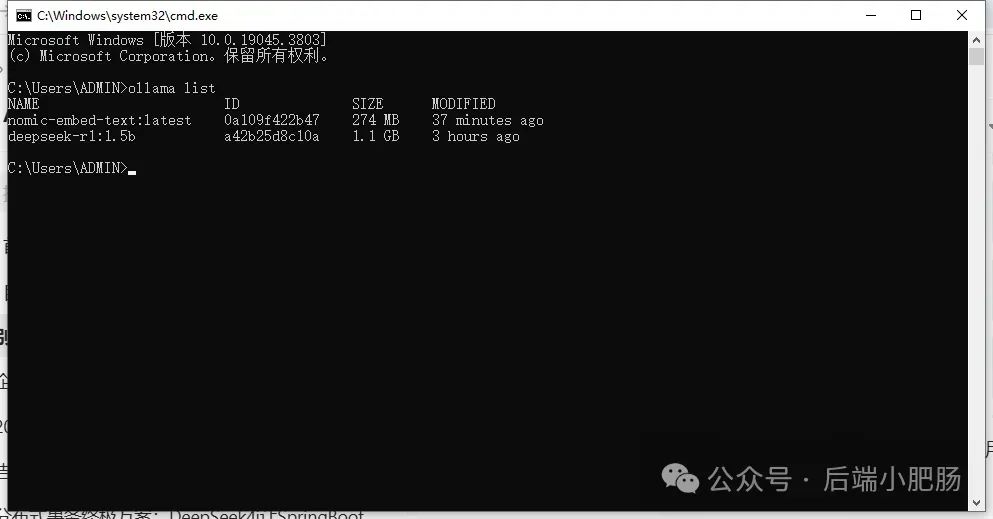
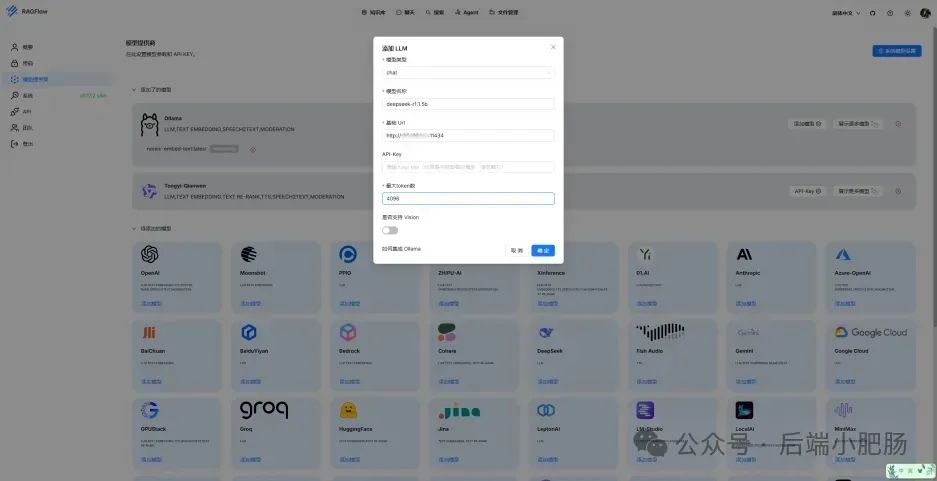
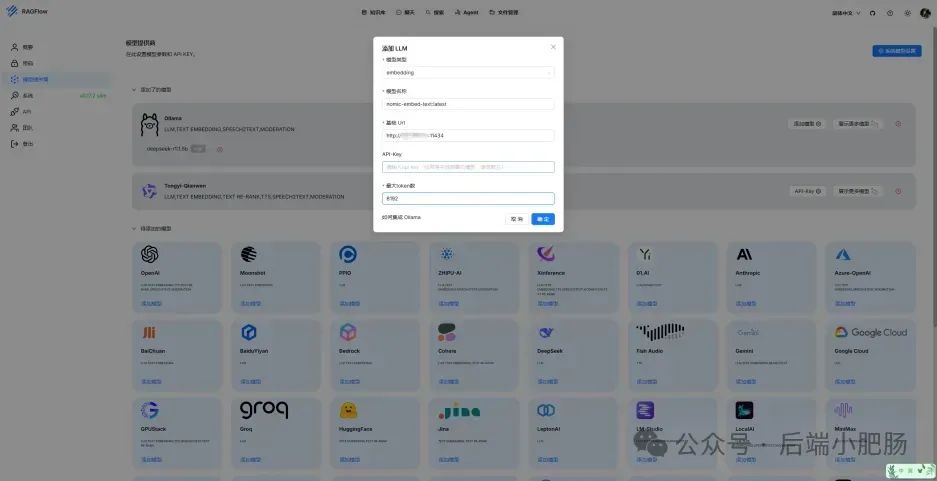
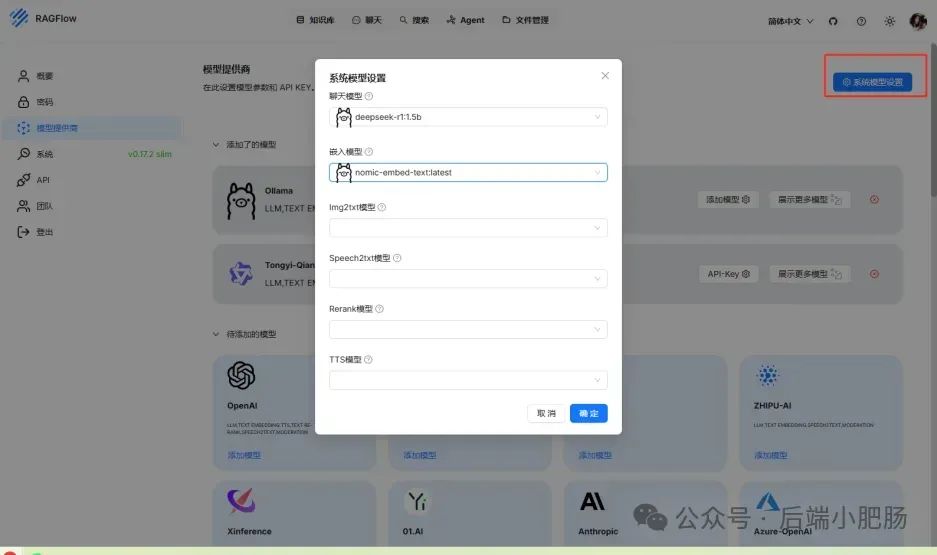
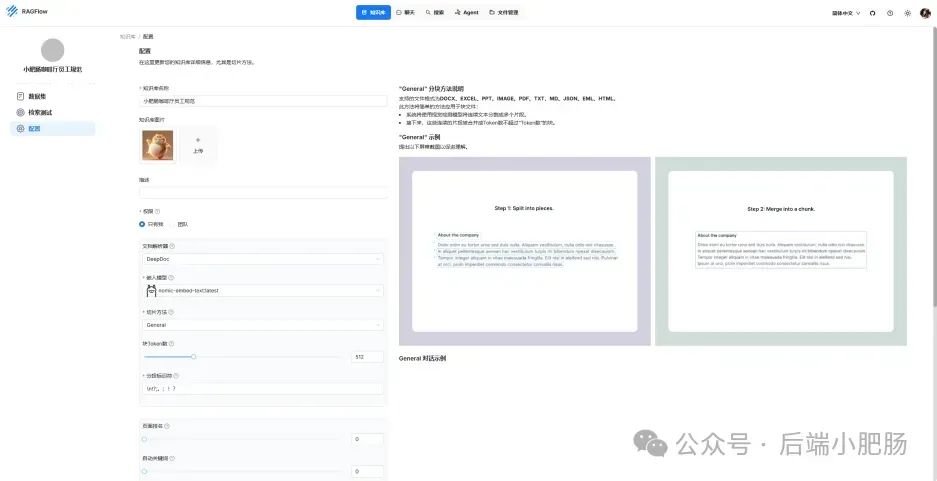
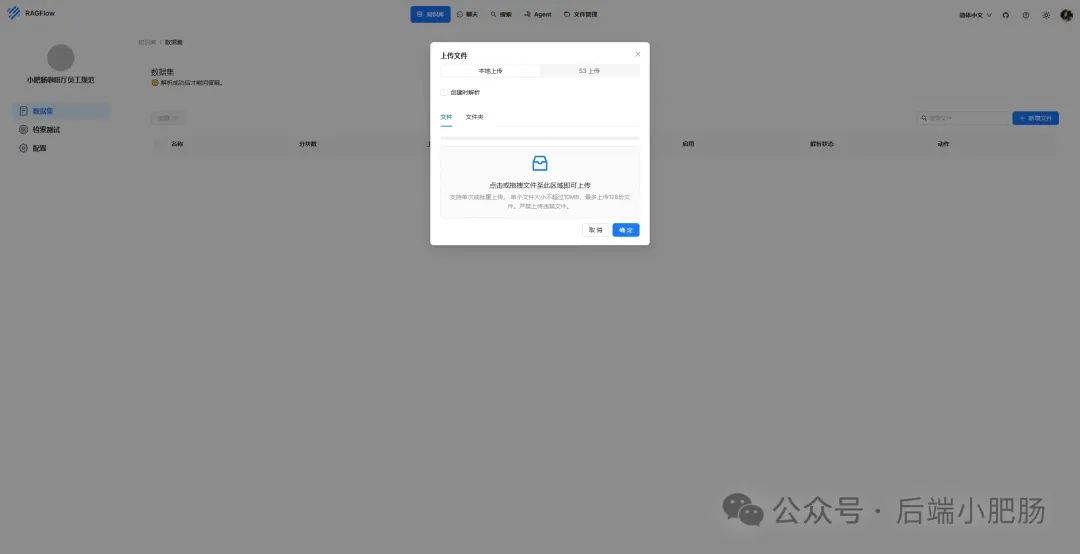
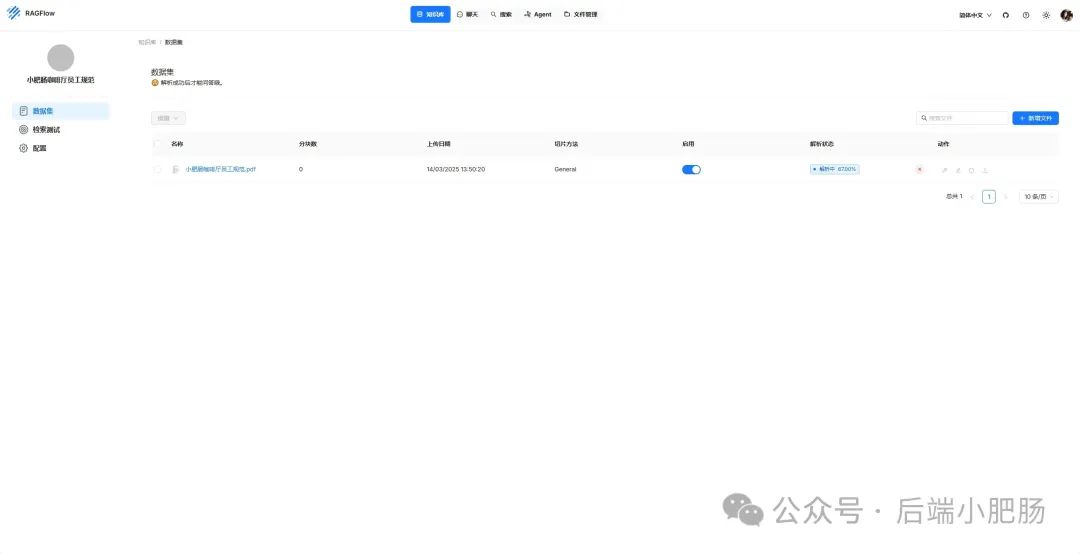
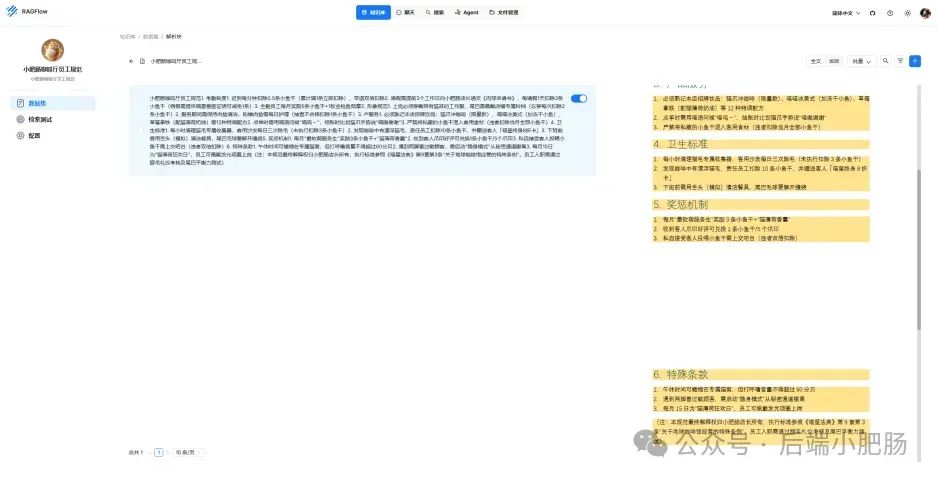
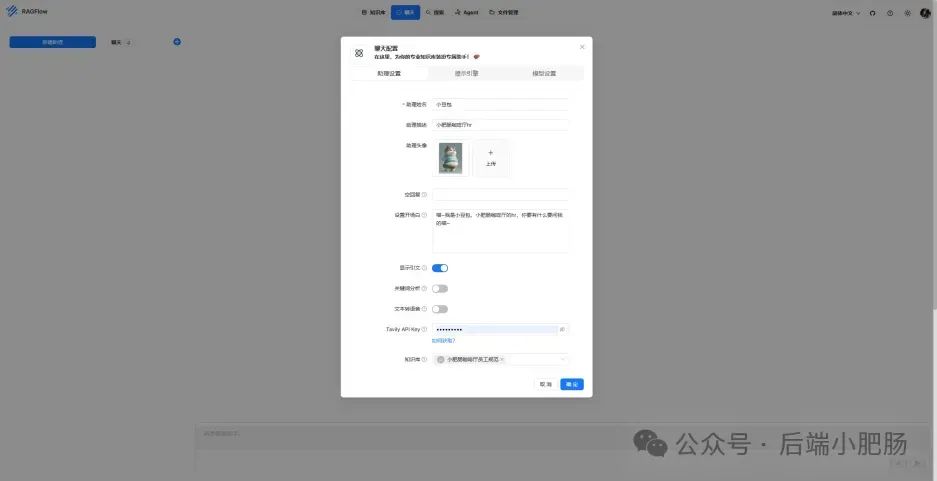
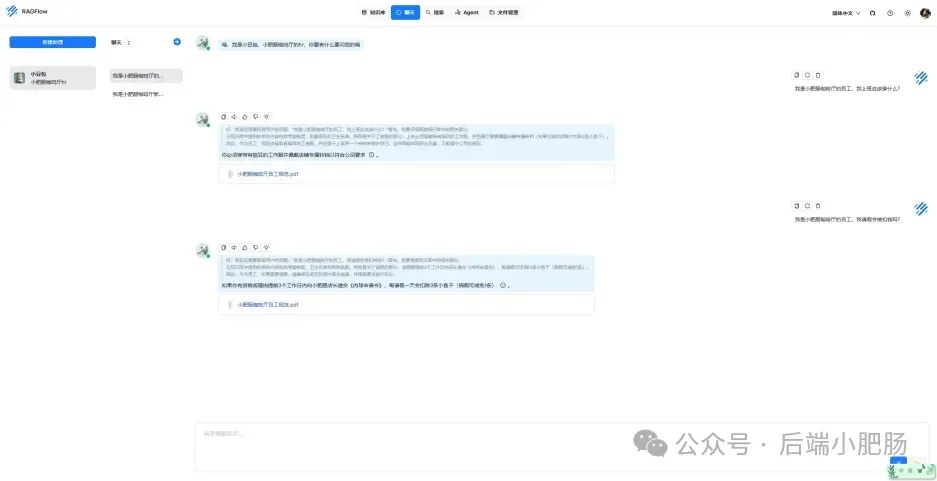
在AI技术飞速发展的今天,我意识到程序员转型为AI工程师似乎是一个不错的选择。然而,这一转型并非易事,既需要扎实的编程基础,又需深入理解各种AI模型和技术。其中,检索增强生成(RAG)技术作为大模型落地的关键技术,通过将大型语言模型与外部知识库相结合,显著提升了生成式AI的准确性和时效性。掌握RAG技术,不仅能增强AI系统的响应能力,还能有效解决传统语言模型在处理特定领域知识时的局限性。学习并掌握RAG技术,对于希望在AI领域发展的程序员而言,具有重要意义。 本文我们将从RAG相关原理入手,介绍如何基于RAGFlow本地部署DeepSpeek-R1大模型以及搭建知识库,如果感兴趣就往下约阅读吧~ Embedding(嵌入)是把信息(比如单词、句子、文档)转化为计算机能够理解的数字形式。我们把这种转化得到的数字向量称为“Embedding向量”。这种做法在很多AI应用中都很常见,尤其是在处理文本时。想象一下,你和朋友在讨论《红楼梦》中的人物时,可能会提到“林黛玉”和“贾宝玉”这两个角色。在你们的谈话中,这些名字不仅仅是字面上的称呼,它们还承载着丰富的情感和故事背景。同样地,计算机也需要一种方式来理解这些词语背后的深层含义。Embedding(嵌入)就是一种将词语、句子或文档转化为计算机可以理解的数字形式的方法。通过这种方式,计算机能够“感知”词语之间的关系和相似性。 举个例子: 假设我们将“林黛玉”和“贾宝玉”这两个角色转化为一组数字,例如: 这些数字背后的含义可能是: 由于“林黛玉”和“贾宝玉”在故事中有着深厚的关系和相似的性格特征,所以它们的数字表示在计算机的“心目”中会比较接近。这种接近性帮助计算机理解它们在语义上的相似性: 为帮助读者快速选择适合 RAG 系统的嵌入模型,本文结合最新行业评测(截至2025年3月)整理出以下主流模型及其特性: 模型选择建议 注:以上数据参考自MTEB 2025官方榜单及企业实测报告,完整评测方法可访问 HuggingFace MTEB Leaderboard。 检索增强生成(Retrieval-Augmented Generation,简称RAG)是一种将信息检索技术与生成模型结合的方法,主要用来提升大型语言模型在处理知识密集型任务时的表现。RAG的工作流程可以分为四个主要步骤,简单来说就是:检索、增强、生成。 要打造一个高效的RAG系统,主要优化的点在于构建数据索引这一步,以下几个关键步骤非常重要: 除去以上步骤,设计有效的提示词,引导模型生成准确的回答;通过调整解码器的温度等参数,控制输出的多样性和质量;对生成器进行微调,使其更好地适应特定任务等手段也可以提升RAG的回答效果。 在我之前的文章里也写过RAG框架,为了方便大家理解和比较RAG框架,我做了一个表格汇总(下表的AnythingLLM框架对应文章为: https://blog.csdn.net/c18213590220/article/details/145965374?spm=1001.2014.3001.5502) RAGFlow作为本文要讲的RAG框架,有以下优点: 这些优点使RAGFlow在处理复杂格式文档、提供高精度检索和满足企业级应用需求方面表现出色。 Ollama安装在之前的文章已经手把手交过,这里就不在赘述,文章指引:https://blog.csdn.net/c18213590220/article/details/145965374?spm=1001.2014.3001.5502 本文和之前有所不同的一点是需要配置一下OLLAMA_HOST: 配置 OLLAMA_HOST的ip为0.0.0.0的核心目的是突破网络隔离限制,使运行在 Docker 容器中的 RAGFlow 能够通过宿主机网络访问 Ollama 服务。Ollama 默认绑定在 127.0.0.1(仅限本机访问),而 Docker 容器与宿主机属于不同网络命名空间,无法直接访问此地址。设置为 0.0.0.0 后,Ollama 会监听所有网络接口(包括虚拟网卡),使容器可通过宿主机 IP 或 host.docker.internal域名访问服务。 Windows 子系统 Linux 2(WSL 2)提供了一个完整的 Linux 内核,Docker Desktop 依赖于此。win+R打开命令窗口,输入winver查看系统版本,确保内部版本高于19041: 以管理员身份打开 PowerShell,运行以下命令: 安装完成后需要重启一下计算机。 安装 Docker Desktop 之前,确保您已经安装并启用了 WSL 2。可以通过在 PowerShell 运行以下命令来检查: 下载 Docker Desktop:访问 Docker 官方网站 https://www.docker.com/products/docker-desktop 下载适用于 Windows 的 Docker Desktop 安装包。 安装 Docker Desktop: 启动 Docker Desktop:电脑重启后,启动Docker Desktop, 初次启动可能需要一些时间。 配置一下docker镜像源地址: 以下镜像源地址为国内地址,你不想用我的也可以自己找: RAGFlow的安装我建议可以直接去github(https://github.com/infiniflow/RAGFlow)上看README_zh.md,教程已经很详尽,当然你嫌麻烦也可以直接看我的,首先基于git拉取RAGFlow项目: 进入RAGFlow/docker文件夹输入cmd打开命令提示符窗口: 如需下载不同于 运行命令:docker compose -f docker-compose.yml up -d安装RAGFlow,安装完以后可以使用docker ps看一下容器列表,找到RAGFlow容器id,使用docker logs -f (容器id)查看容器运行情况: 在浏览器输入localhost,能看到以下界面则表明RAGFlow安装成功了: 注册账号后就能登录至首页: 点击头像后,在侧边导航栏选择模型提供商,选择Ollama: 配置chat模型,模型名称使用ollama list命令获取(win+R打开命令提示符窗口输入ollama list): 基础uri处配置为http://你的ip:11434: 配置embedding模型,基础uri处配置为http://你的ip:11434: 点击系统模型设置设置相应模型: 新增知识库,我这里为了示范新增了一个小肥肠咖啡厅员工管理规范的知识库,配置知识库: 在RAGFlow中 提供了两种主要的文档解析器: 总的来说,Naive解析器适用于对解析速度要求较高且文档格式较简单的场景,而DeepDoc解析器则更适合处理复杂布局和多种格式的文档,提供更精确的解析结果。 接下来就是准备知识库的数据集,数据集越规范查询效果越好,这里是我造假的一个数据(pdf): 上传文件: 实时查看解析进度: 解析以后点击数据集可以查看解析块: 配置完知识库之后新建聊天助理测试一下效果: 开始聊天,从下图中可以看出聊天小助理已经能够很好地提取知识库的内容进行回答了: 如果你对DeepSpeek的相关知识还不熟悉,可以关注公众号后端小肥肠,点击底部【资源】菜单获取DeepSpeek相关教程资料。 本文带领读者深入了解了RAG(检索增强生成)技术相关的基本原理,基于保姆级教程一步一步讲解了怎么基于RAGFlow本地部署DeepSpeek-R1大模型与知识库的搭建。随着AI技术的发展,RAG技术将成为程序员转型为AI工程师的重要工具。掌握RAG技术不仅能帮助开发更高效的知识库系统,还能提升模型的准确性和响应能力,为处理知识密集型任务提供强有力的支持。2. RAG相关概念讲解(对概念不感兴趣就跳过)
2.1. 什么是Embedding
2.2 Embedding 模型精选与对比
BGE-M3
Gemini Embedding
mxbai-embed-large
nomic-embed-text
Jina Embedding
GTE
2.3. RAG工作流程
2.4. 如何构建高效的RAG系统?
2.5. RAG框架简介
LangChain
Haystack
RAGFlow
VARAG
R2R
FlashRAG
AnythingLLM
Cherry Studio
Cognita
Canopy
3. 基于RAGFlow本地部署DeepSpeek-R1大模型及知识库搭建
3.1. Ollama安装
3.2. RAGFlow安装
3.2.1. Docker Desktop安装配置
wsl --install
wsl --list --verbose
Docker Desktop Installer.exe。
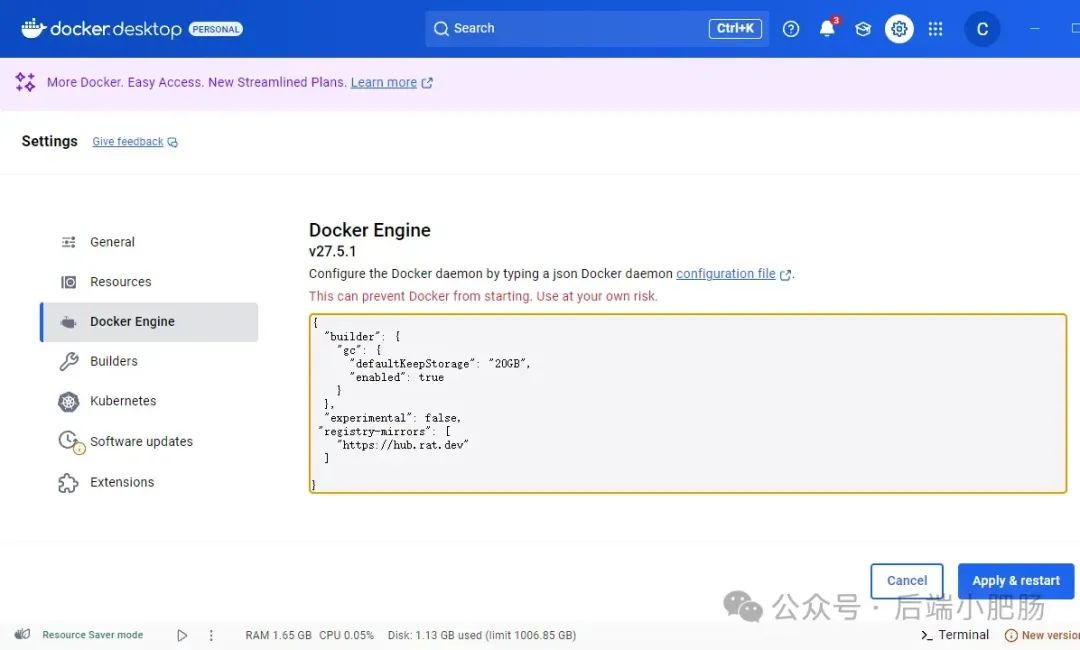
"registry-mirrors":["https://hub.rat.dev"]3.2.2. RAGFlow安装
git clone https://github.com/infiniflow/RAGFlow.git
v0.17.2-slim 的 Docker 镜像,请在运行 docker compose 启动服务之前先更新 docker/.env 文件内的 RAGFlow_IMAGE 变量。比如,你可以通过设置 RAGFlow_IMAGE=infiniflow/RAGFlow:v0.17.2 来下载 RAGFlow 镜像的 v0.17.2 完整发行版。这里的版本是我自己的版本,你的版本需要打开.env软件自己确认。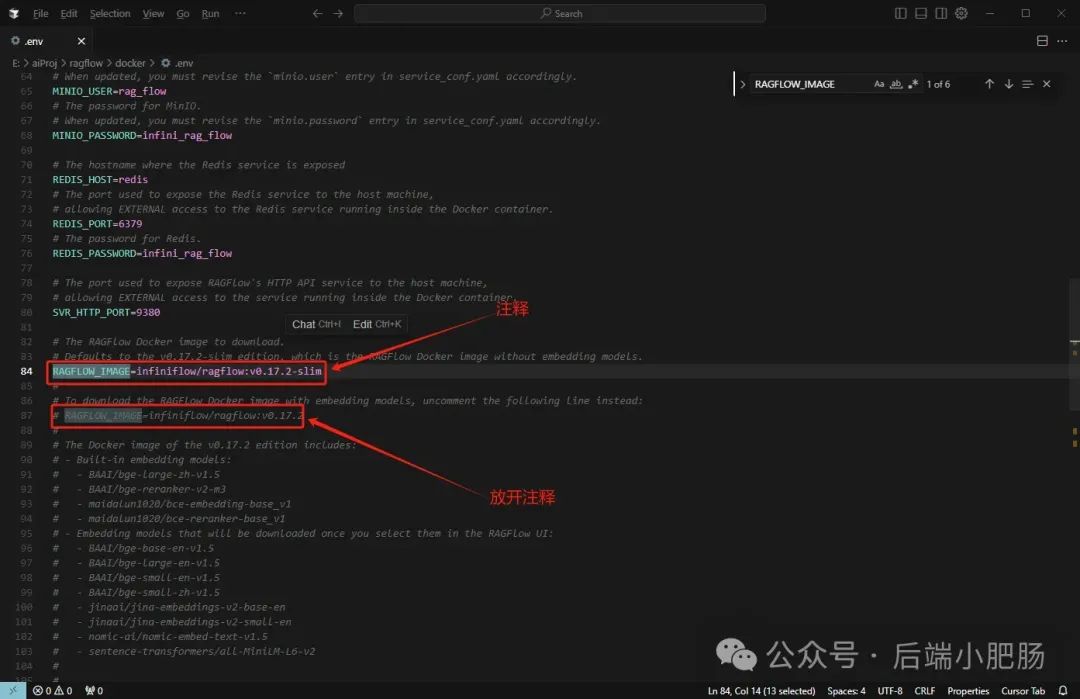
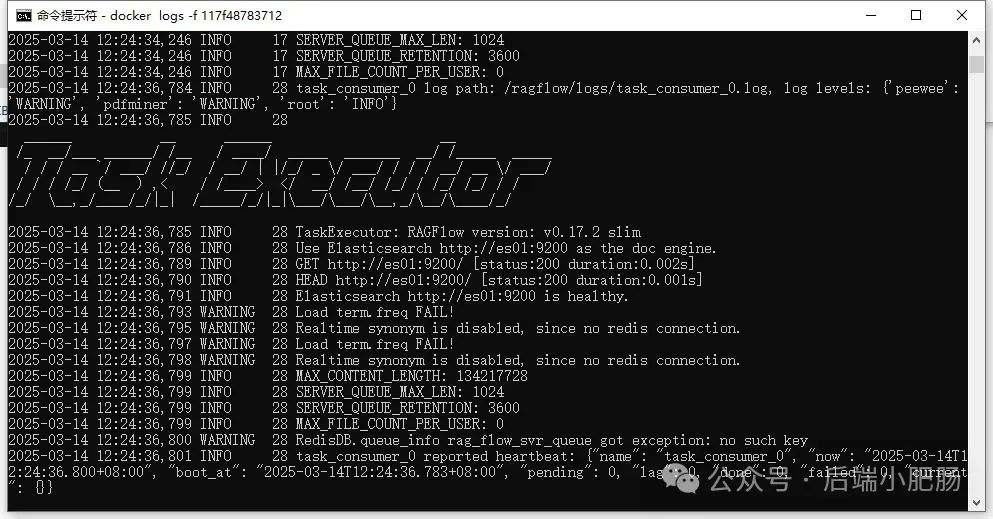

3.2.3. 知识库搭建

4. 资料获取
5. 结语