作者:微信小助手
发布时间:2025-03-18T21:49:45
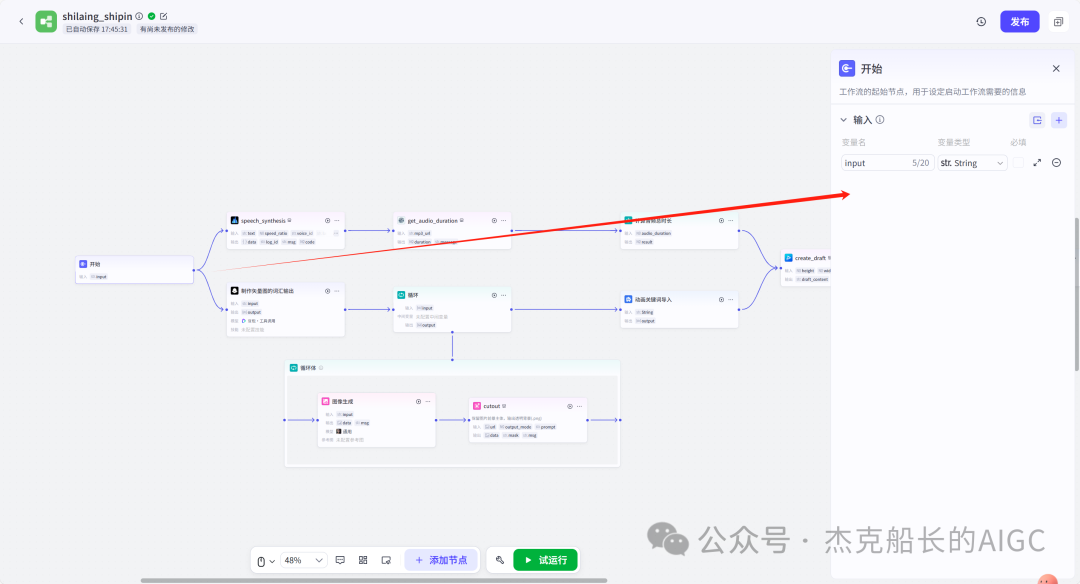
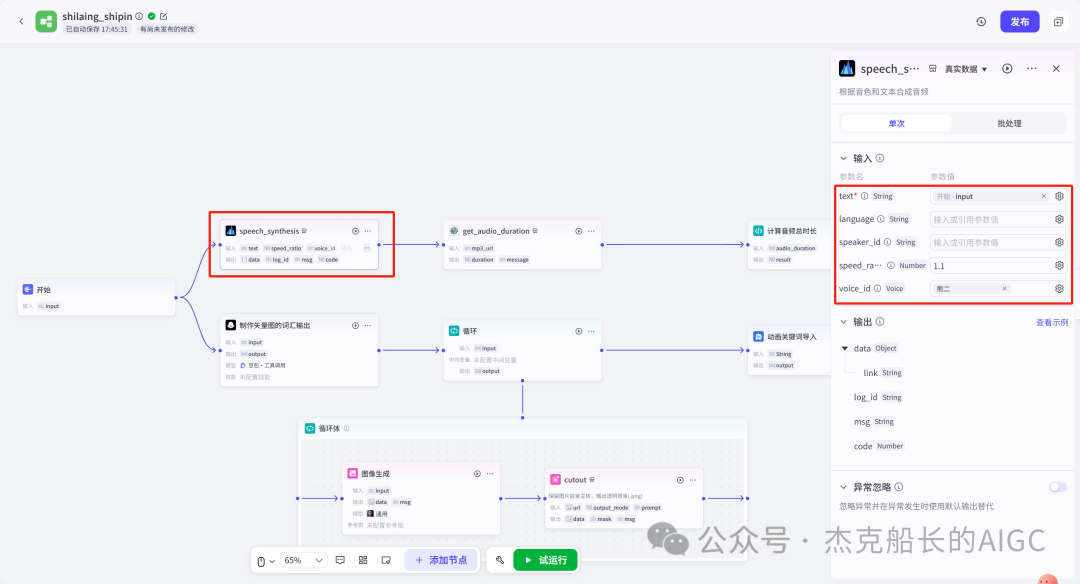
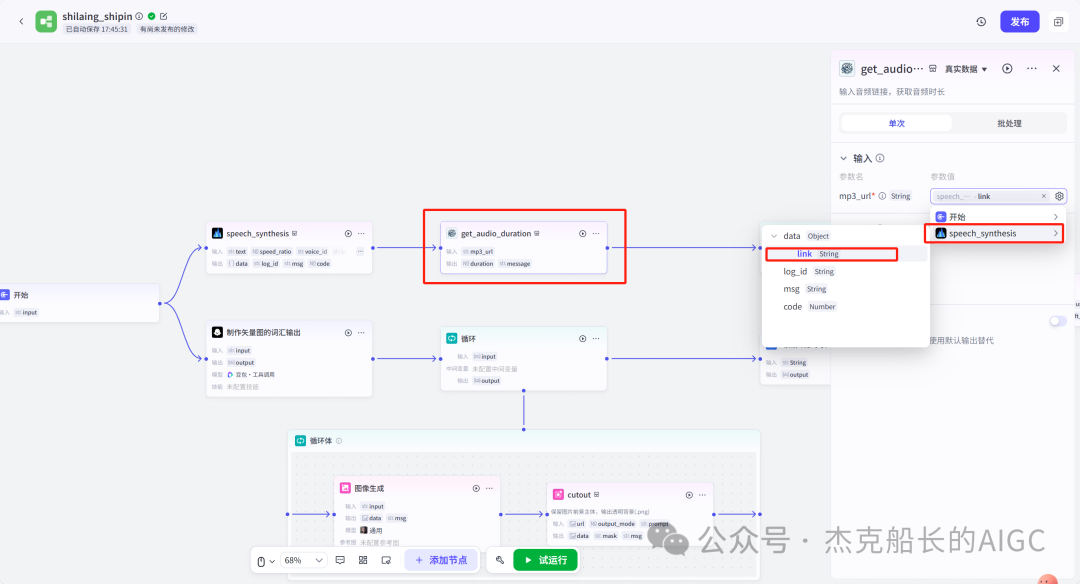
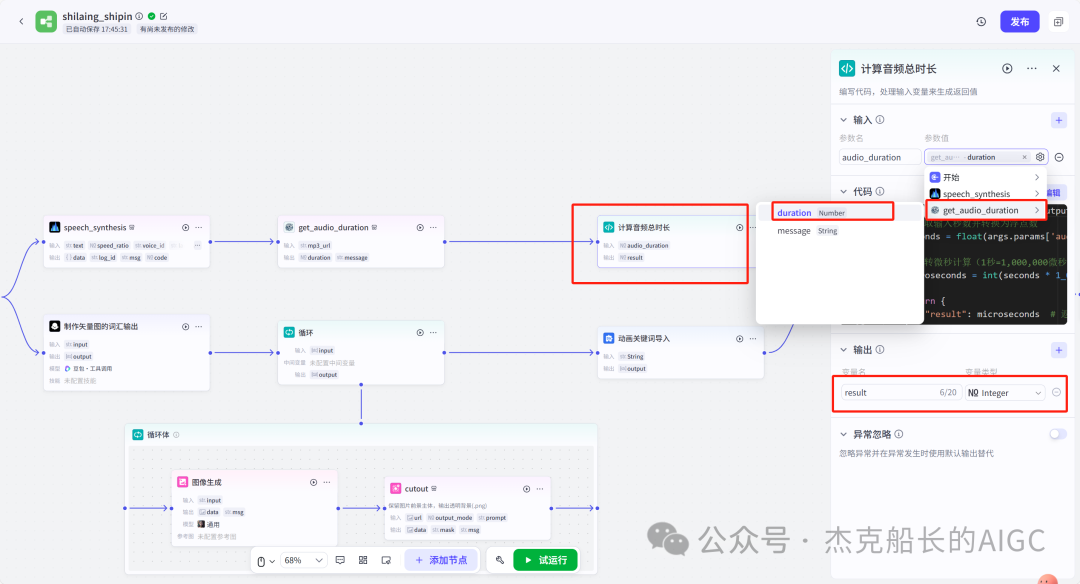
读完这篇文章,别忘记给舰长点一个关注!舰长的智能体搭建文章,不仅是节点的构建,也有思路的分享。智能体搭建最重要的就是思路。最希望,能给大家带来不一样的搭建思路和方法。 点一点上方的🔵蓝色小字关注,你的支持是我最大的动力!🙏谢谢啦!🌟" 大家好!我是舰长🙏 昨天晚上舰长团队-福建老师利用近两小时直播教用Coze搭建一个的知识分享类视频制作工作流。因为所涉及内容较多建议先点个在看喔!先看一下本次分享成果: 先梳理一下本次分享的目录和大致内容: 1.为什么舰长会做这样的视频案例 2.视频工作流设计和思路分享 3.视频工作流各节点配置和使用 4.视频工具使用和下载注意,以及福利领取方式 第一点:为什么舰长会做这样的视频案例 抖音搜索“半条心理”,通过搜索该人可以发现,他的视频流量是相当可以的,一个视频有几万到几十万的点赞,短短三个月多涨粉10万多。 而舰长这套工作流可以在2分钟之内容做出一样的效果出来 不管我们在使用Coze搭建各种各样的工作流都有一定的思路和想法(解决方法)而本次的案例思路还要多一个,要会用剪映制作视频。 该对标账号的视频中的元素: 白色带黑色线条的背景;左上角的文字;右上角的文字;中间不停切换的矢量icon图;视频下方的视频;以及背景音频(讲知识) 有了这些元素我们就能在剪映上制作出样的视频,当然元素如何获取?这也是一个很重要的地方。当然如果使用从Coze工作流来提供元素的话就方便的多。 左上方文字为本视频的总结话语,可以用大模型节点为我们生成;右上方文字,背景和黑色线条都是不动的元素,中间的矢量icon图可以用生成图像节点制作,下方的实时字幕需要借助工具,背后的音频可以用官方插件语音合成来制作。 素材部分: 开始节点: 语音合成插件: text:为文本输入引用开始节点即可 speed_ratio:为语速,可看情况调节 voice_id:声音音色配置 获取音频时长插件(获取生成音频的时间,秒) 代码节点:计算音频总时长(微秒) 这个代码主要功能就是在输入进来的时间*100000 代码舰长已经整理好~ 大模型节点:专门生成图片的提示词 输入:引用开始节点的参数 系统提示词和用户提示词都已整理好 输出:要修改为array
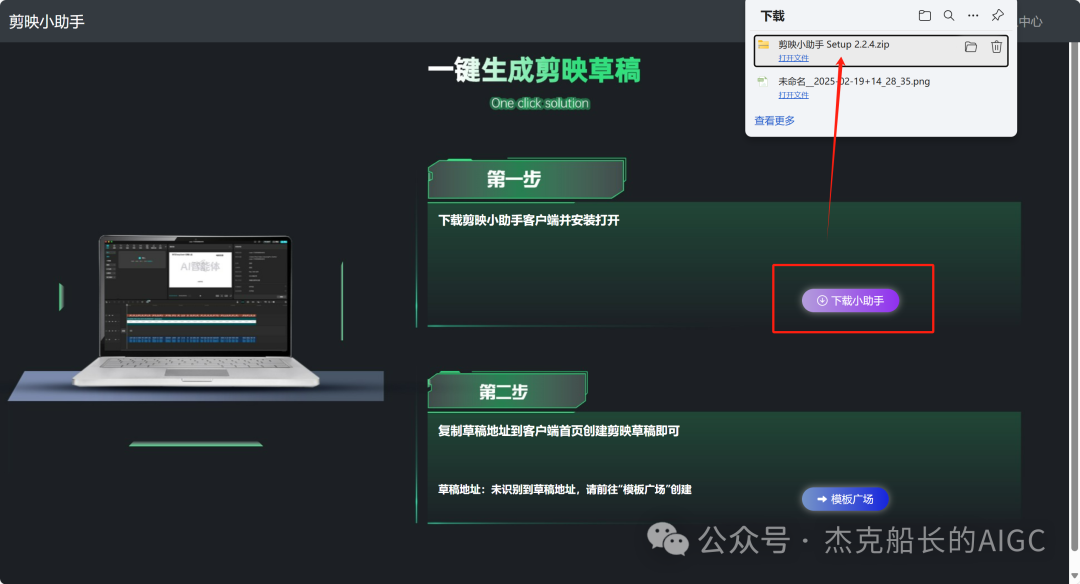
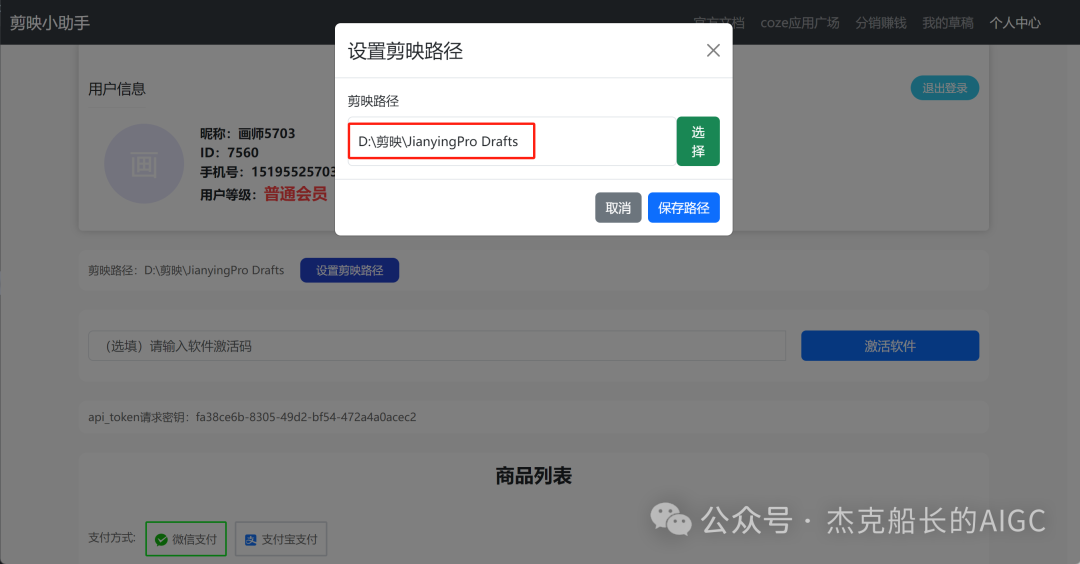
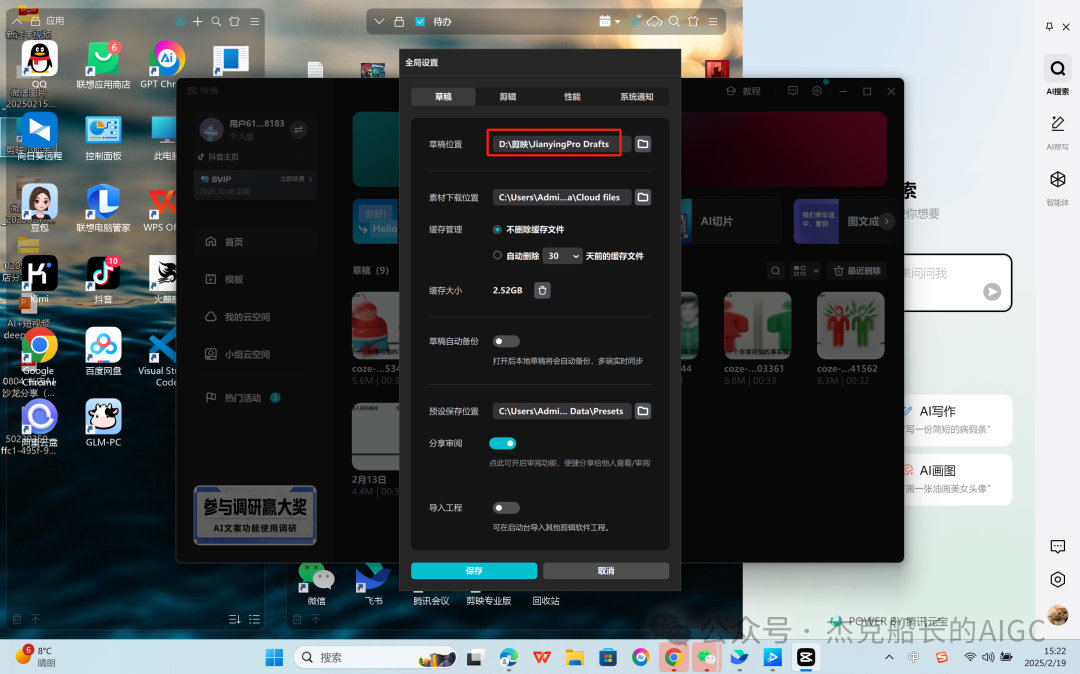
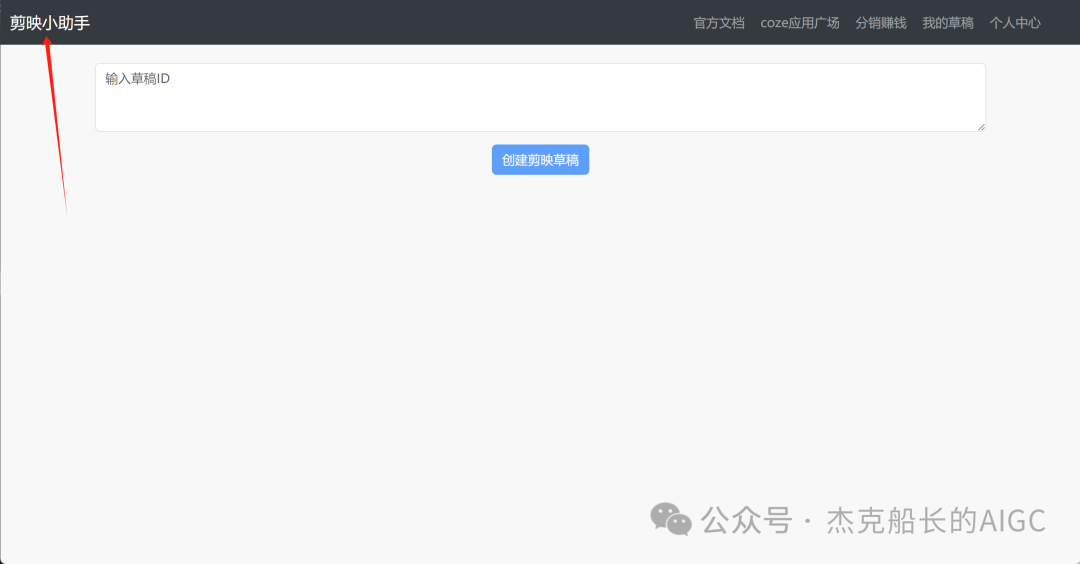
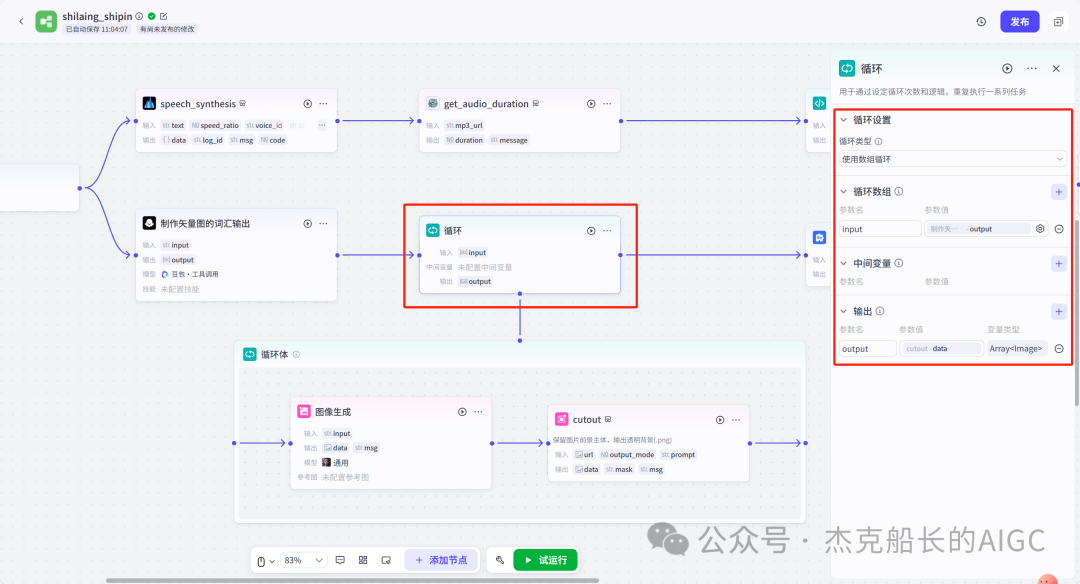
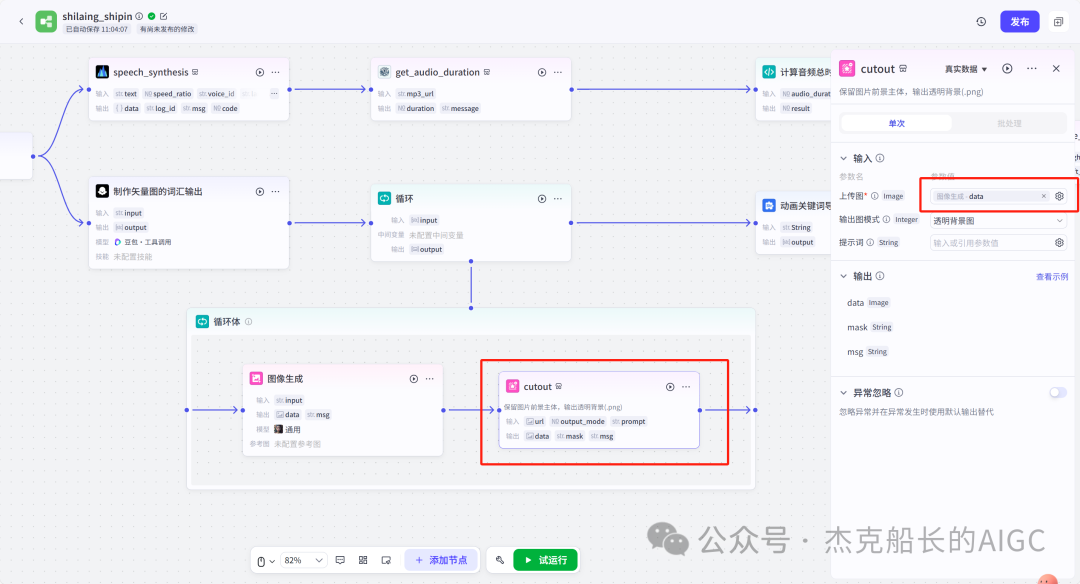
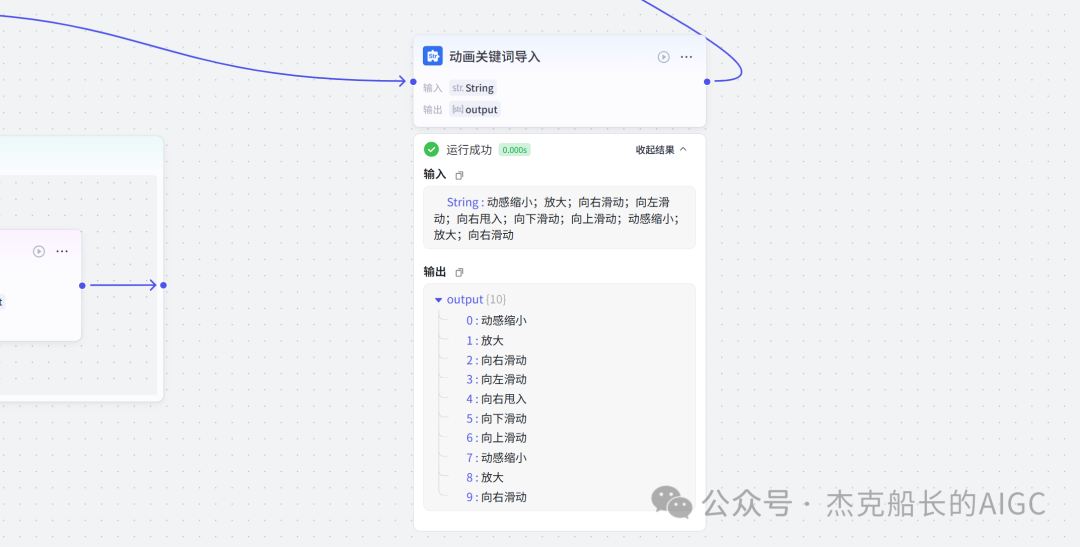
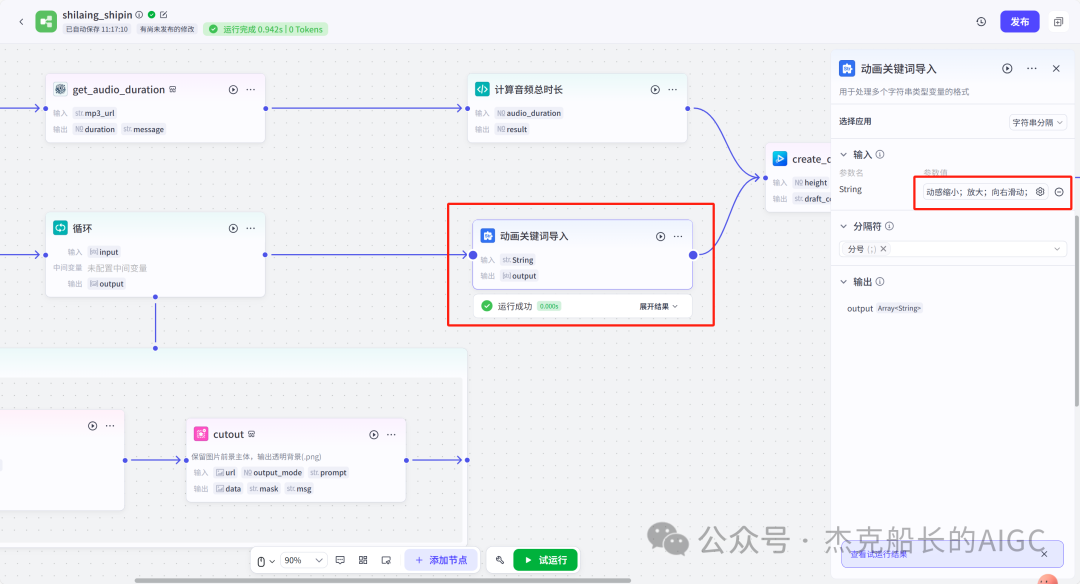
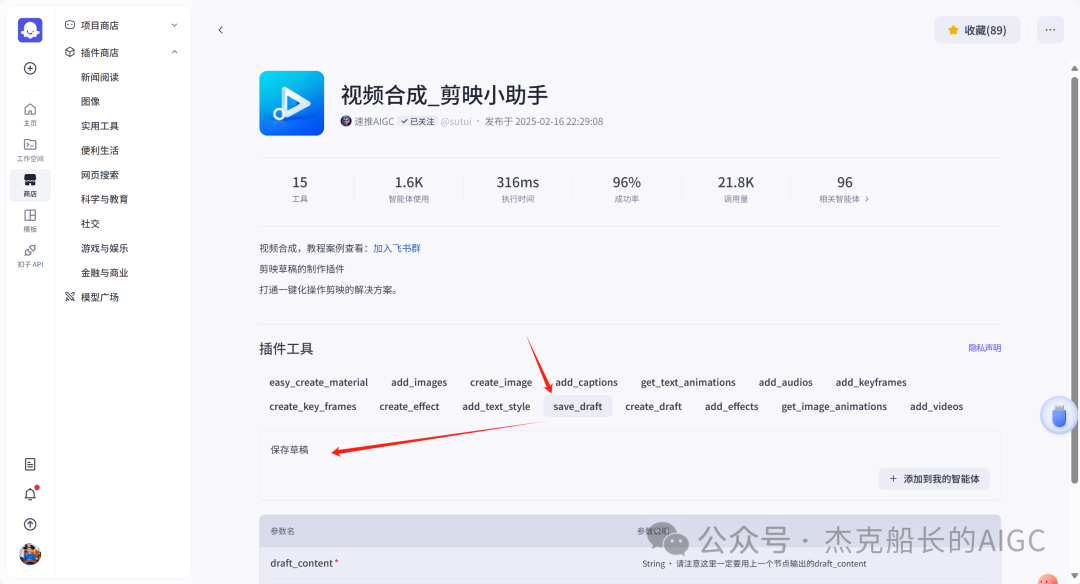
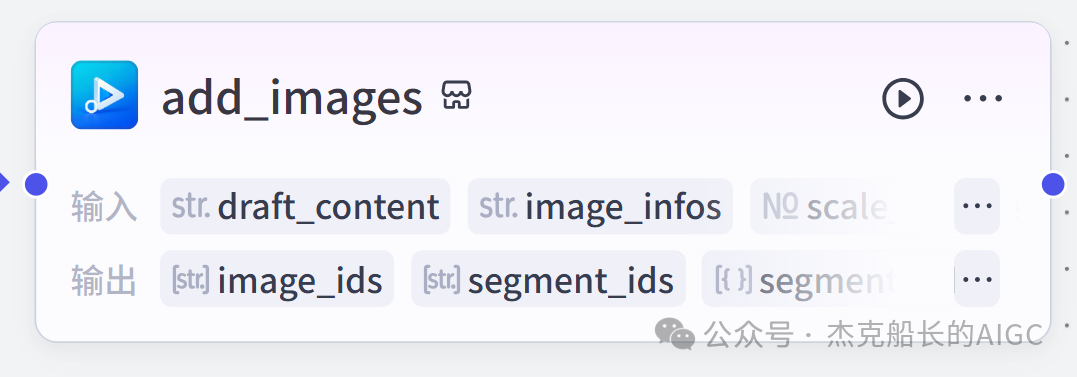
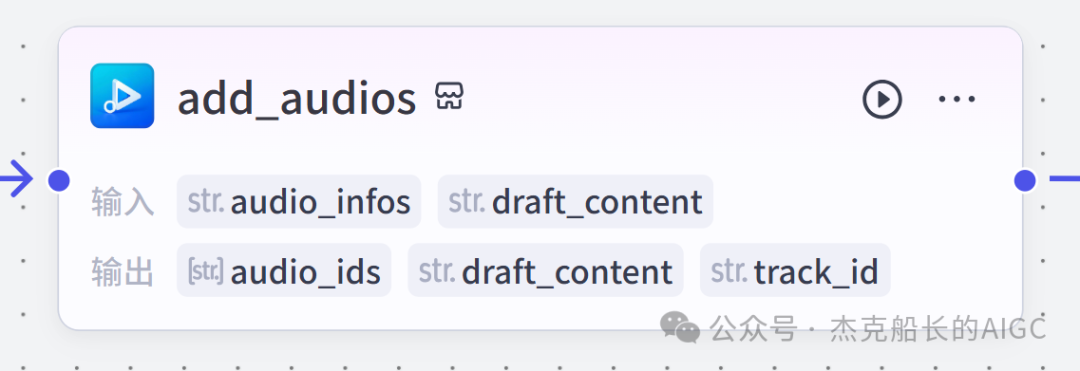
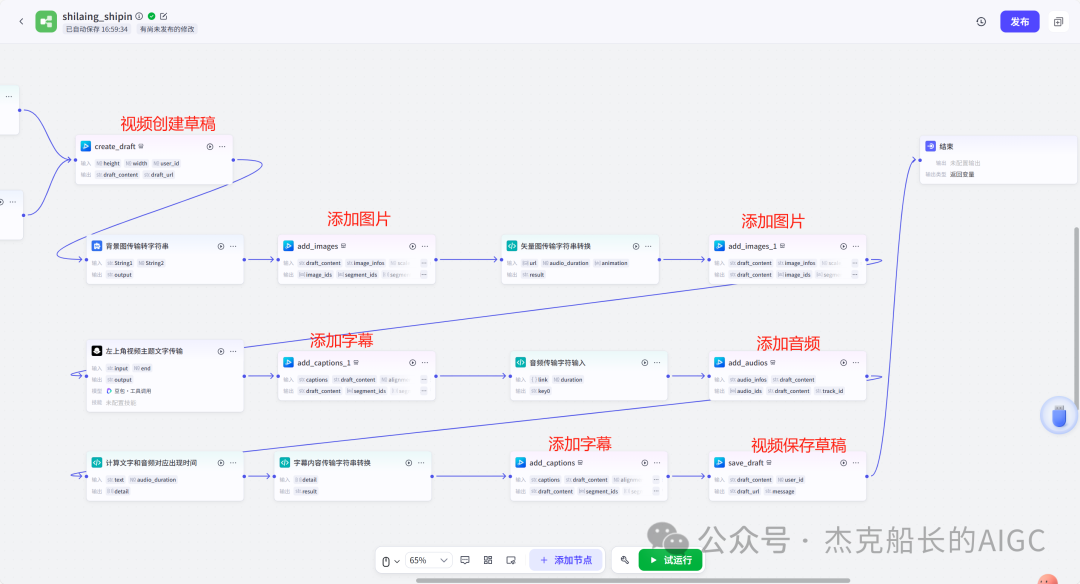
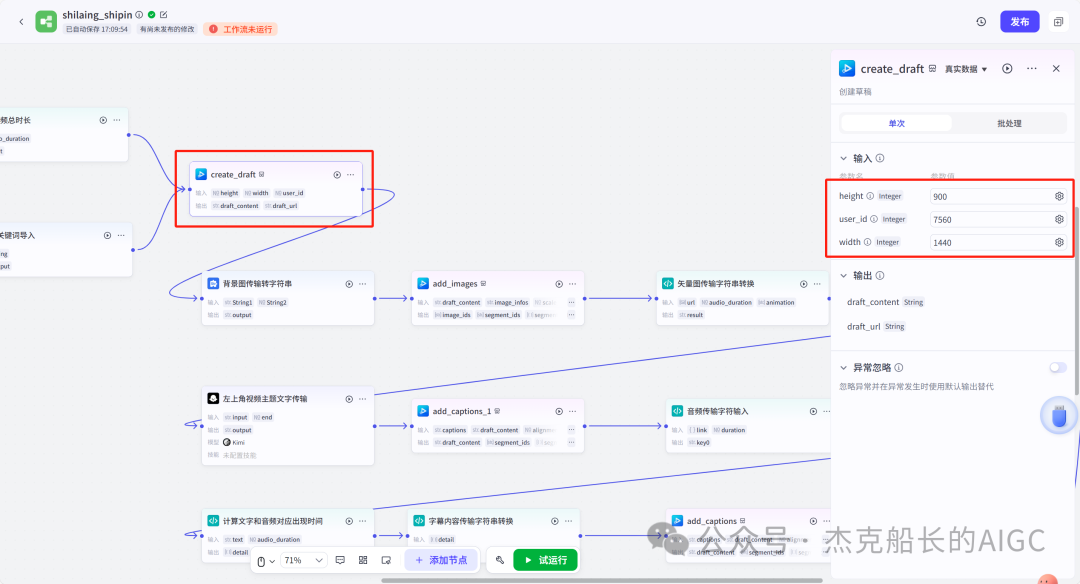
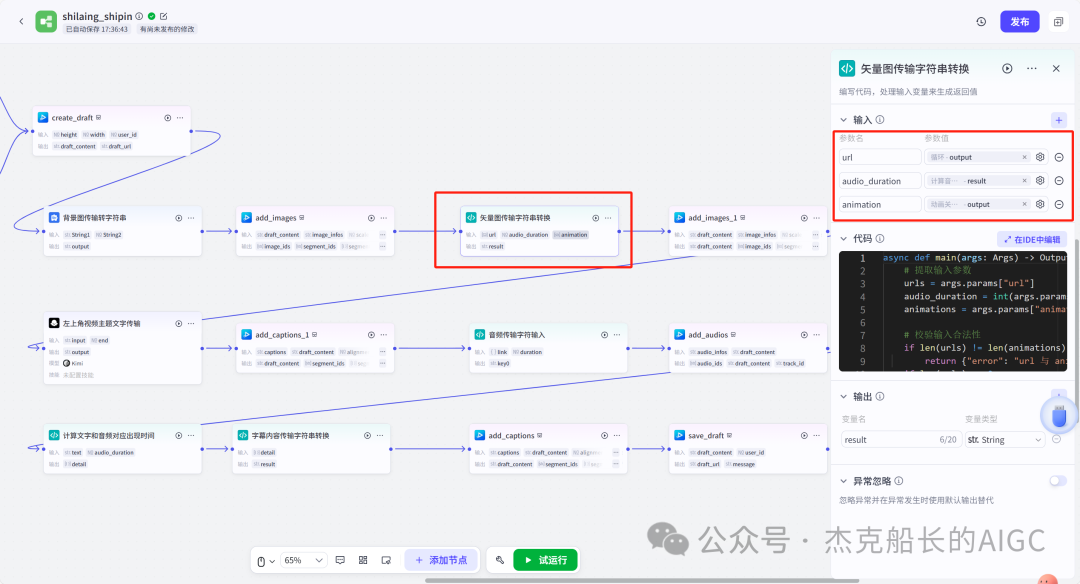
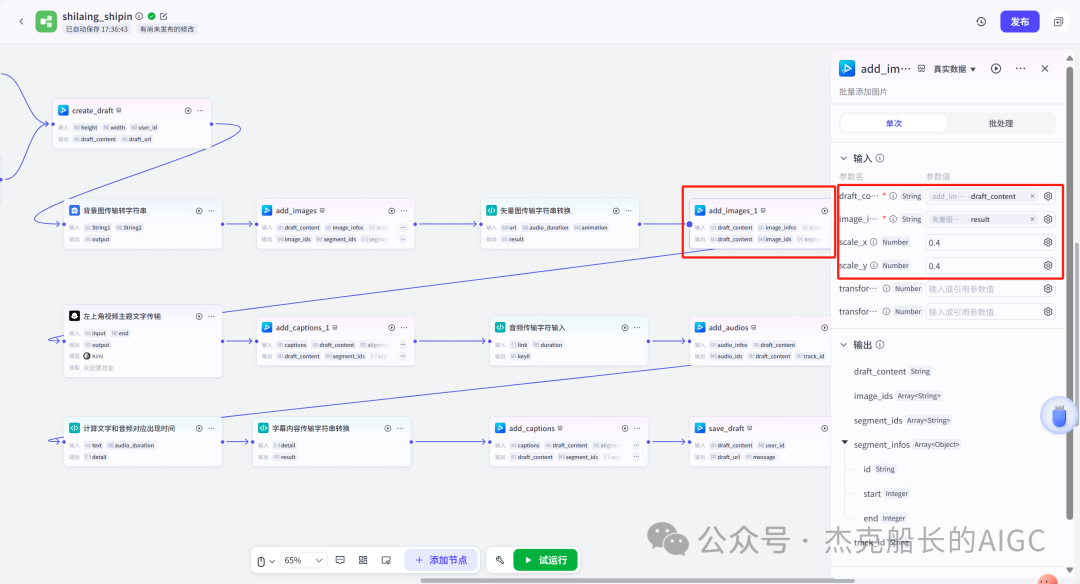
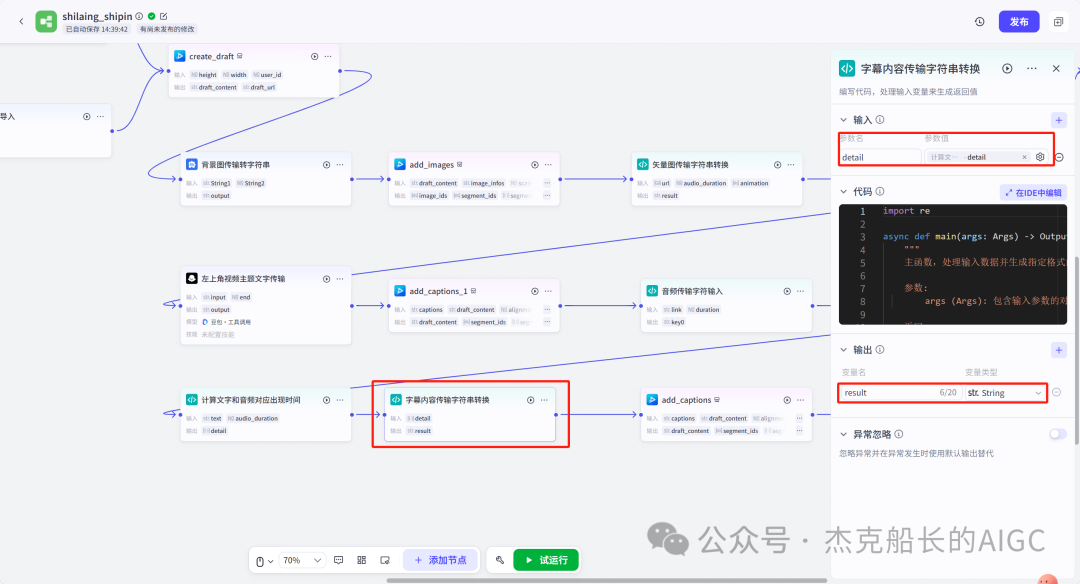
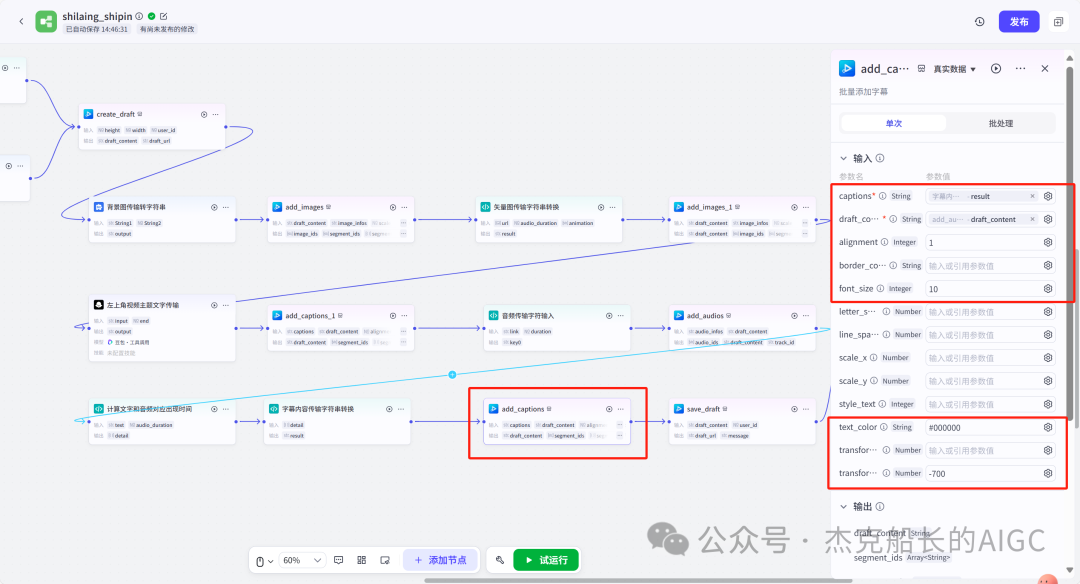
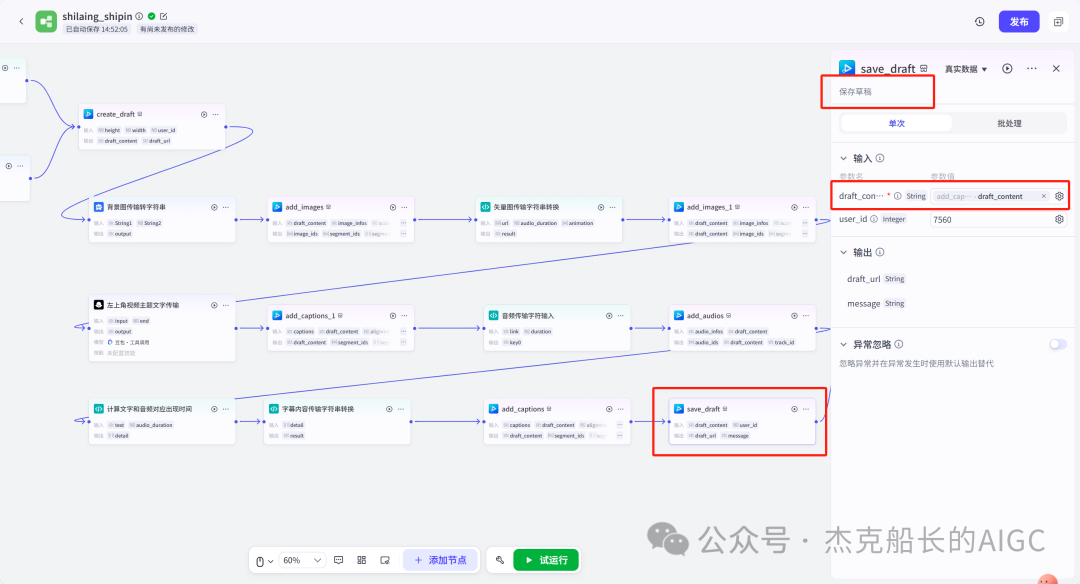
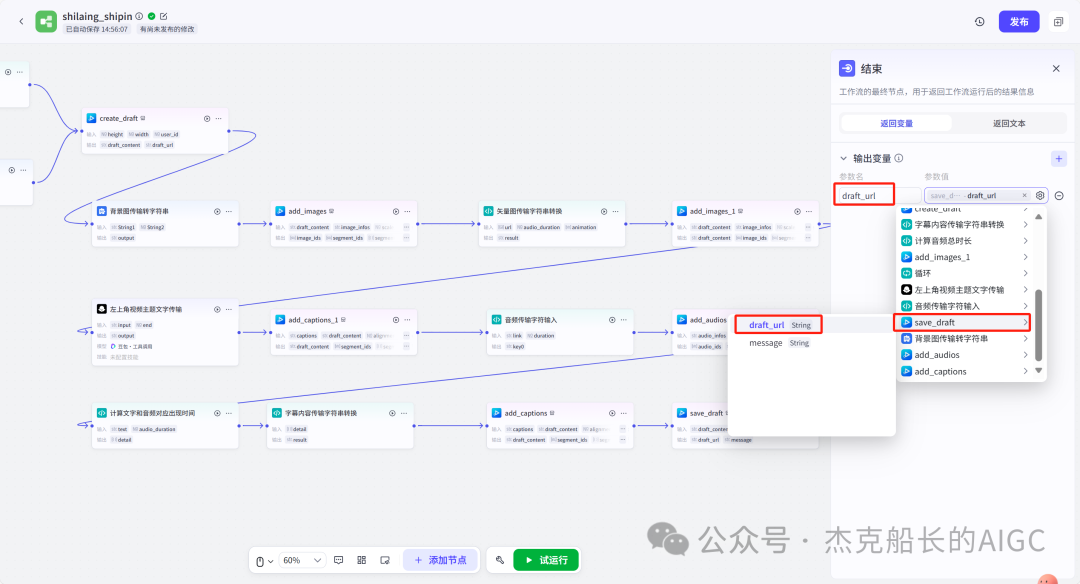
循环节点外部配置: 循环类型:现在循环数组 循环数组:引用大模型节点(图中的制作矢量图的词汇输出) 输出:需要配置好内容节点才可以引用,这里是引用循环中的插件“抠图cutout”的输出 循环节点内部节点配置:图像生成(专门生成矢量的小人物图片) 模型设置舰长这里是没有动的,也就是默认,可以根据情况进行调节 输入:引用循环的(item input) 提示词 循环节点内部节点配置:插件-抠图(官方插件抠图) 这个节点是为了将图像生成的图片的背景给剔除 上传图:就引用图像生成的输出“data” 完成循环内部节点的配置后回到循环节点的外部,对输出进行一个引用,引用对象就是插件的输出 文本处理节点 目的:将动画进行手动排序设置好后,用文本处理进行字符串分隔 需要处理文本(这些词汇都是剪映上的动画名称):动感缩小;放大;向右滑动;向左滑动;向右甩入;向下滑动;向上滑动;动感缩小;放大;向右滑动 处理后的效果: 节点的配置如下: 选择字符串分隔 456输入需要处理的文本,可以选择变量方式传入也可以选择直接文本传入。 分隔符根据动画之间的间隔符号来决定 到这里我们所有的材料和所需都已经准备好,下面就是本次的分享重中之重,将这些内容整合到一起,变成一个视频。 将素材合成一个视频主要依靠舰长的合作伙伴所开发的一款插件:视频合成_剪映小助手 要想成功完成一个视频素材的融合,需要先知道插件如何使用,基本流程是什么? 舰长这里简单的讲解一下,在插件中有其他插件工具。想要合成一个一个视频需要一个创建草稿(工具名称:create_draft),有了草稿还需要一个保存草稿(工具名称:save_draft) 这两款工具就是一个视频草稿的基本步骤,由(工具名称:create_draft)开始(工具名称:save_draft)结束。 其余工具就不一一介绍,主要介绍我们本次搭建所需要用到的插件。 批量添加图片 (工具名称:add_images) 批量添加音频 (工具名称:add_audios) 批量添加字幕 (工具名称:add_captions) 工作流详图:这里截掉了上半部分工作流 整个工作流舰长截图给大家,大家有没有发现什么规律? 每个插件前是不是都有1~2个节点(有大模型节、文本处理节点、代码节点)这些节点可以说都是为了将内容传输到插件中,因为插件有特殊的传递格式需要靠这些节点去准备。 里面涉及到4个代码节点,都是较为简单的代码组成,主要就是格式转换加上一些计算。 height:为画幕的高 width:为画幕的宽 900:1440是9:16的比例 文本处理节点:背景图传输转字符串 srting1:是图片链接也就是背景图片的在线链接: https://p9-bot-sign.byteimg.com/tos-cn-i-v4nquku3lp/d48ed6761667430986f5bf6090d0b3ea.jpg~tplv-v4nquku3lp-image.image?rk3s=68e6b6b5&x-expires=1742089416&x-signature=pT5Ntx1N3DFuPJkoc%2BhFyhDdKVE%3D srting2:引用代码节点(获取音频总时间)的输出result 添加图片插件 这个插件需要提供上一个插件节点的草稿ID(draft_content);这个草稿ID是顺着来的,必须连接上一个ID,这里是除了创建草稿后的第一个插件,所以引用创建草稿的。 draft_content:引用创建草稿插件的(create_draft)的draft_content image_infos:图片输入,引用背景图传输转字符串(文本处理节点) 代码节点:矢量图传输字符串转换 url:引用前面循环节点的输出 audio_duration:引用代码节点(计算音频总时间)的输出result animation:动画词,引用文本处理节点(动画关键词导入)的输出 代码:代码较长舰长已经准备好 输出变量名为result 添加图片插件 这个插件需要提供上一个插件节点的草稿ID(draft_content);这个草稿ID是顺着来的,必须连接上一个ID draft_content:引用第一个添加图片插件(add_images)的draft_content image_infos:图片输入,引用代码节点(矢量图传输字符串转换) scale_x和scale_y是图片缩放值:设置0.4就是40% 视频中的左上角是由每次提供主题而生成的字幕,所以单独使用一个插件导入。主题是通过模型来生成的,同时还有传输插件的内容一并靠模型解决即可。 大模型节点:左上角视频主题文字传输 输入: input:引用开始节点 end:引用代码节点(计算音频总时间)的输出result 系统提示词: 添加字幕插件 这个插件需要提供上一个插件节点的草稿ID(draft_content);这个草稿ID是顺着来的,必须连接上一个ID captions:图片输入,引用大模型节点(左上角视频主题文字传输)的输出 draft_content:引用第一个添加图片插件(add_images_1)的draft_content alignment:文字对齐,0左对齐 font_size:文字大小,5号 text_color:文本颜色,#000000为黑色 transform_x:x轴方向-1020 transform_y:y轴方向800 这个音频就是背后说话人的音频,由插件语言合成提供音频URL 代码节点:(音频传输字符串转换) 输入: “link”:引用语音合成插件(speech_synthesis)的“link” duration:引用获取音频时长插件(get_audio_duration)的输出 代码:代码较长舰长已经准备好 输出: 设置变量名称为“key0”变量类型为srting 添加音频插件 这个插件需要提供上一个插件节点的草稿ID(add_captions_1);这个草稿ID是顺着来的,必须连接上一个ID。 audio_infos:素材内容传输,引用前置代码节点的输出 draft_content:引用第一个添加图片插件(add_captions_1)的draft_content 字幕会根据音频说话人的声音时间去跳动转换 代码节点:计算文字和音频对应出现时间 输入: text:引用开始的text变量 audio_duration:引用插件(get_audio_duration)获取音频时长的输出 代码:代码较长舰长已经准备好 输出:子项是该输出变量的右边“+”号,且类型为Array或object detail 类型为Array 增加detail子项:sentence 类型为Srting 增加detail子项:time_range 类型为object 增加time_range的子项:start 类型为Srting 增加time_range的子项:end 类型为Srting 增加detail子项:effective_char_count 类型为Srting 增加detail子项:word_count 类型为Srting 代码节点:字幕内容传输字符串转换 输入: detail:引用代码节点(计算文字和音频对应出现时间)的输出“detail” 代码:代码较长舰长已经准备好 输出:result 变量类型为Srting 添加字幕插件 captions:引用代码节点(字幕内容传输字符串转换) draft_content:引用上一个插件节点(add_audios)的“draft_content” alignment:1 font_size:10 text_color:#000000 transform_y:-700 到这里整个剪映草稿的模版编辑就完成了,完成这一步即可获得一个剪映的草稿ID 输入:引用前面一个插件(添加字幕插件 add_captions)的draft_content 这样相当于两个部分的工作流都已经搭建好(素材准备部分+剪映草稿编辑部分)整个流程逻辑就是通过一个视频插件+前置的转换格式导入节点组成。看似复杂,体验下来还是相当顺手的。 通过工作流的最后的保存草稿,会返回一个:draft_url链接,而这个链接需要借助一个平台去提取到自己的剪映中。 第一步:确保自己电脑有剪映专业版 第二步:打开网址下载软件: https://ts.fyshark.com/#/login?user_id=7560 第三步:解压缩文件并安装 第四步:打开软件——点击个人中心——手机验证码登入 第五步:设置个人中间草稿位置和剪映中的草稿位置,确保在同一个位置即可 第六步:点击剪映小助手回到首页,粘贴工作流返回的链接 第七步:点击创建剪映草稿即可,等待一会可以在剪映的草稿位置看到 注意事项:如果遇到打开无法显示素材元素的叉掉重新进一次即可。下载软件为剪映小助手,每天享有三次免费的提取次数。
不管哪些自媒体平台上,能提供情绪价值的视频图文或者知识分享类的视频图文,都是较为好的视频,且这些视频有一个有点好做!还能引发共鸣。

第二点:视频工作流设计和思路分享

第三点:视频工作流各节点配置和使用
工作流部分分两个部分:素材部分和制作视频部分
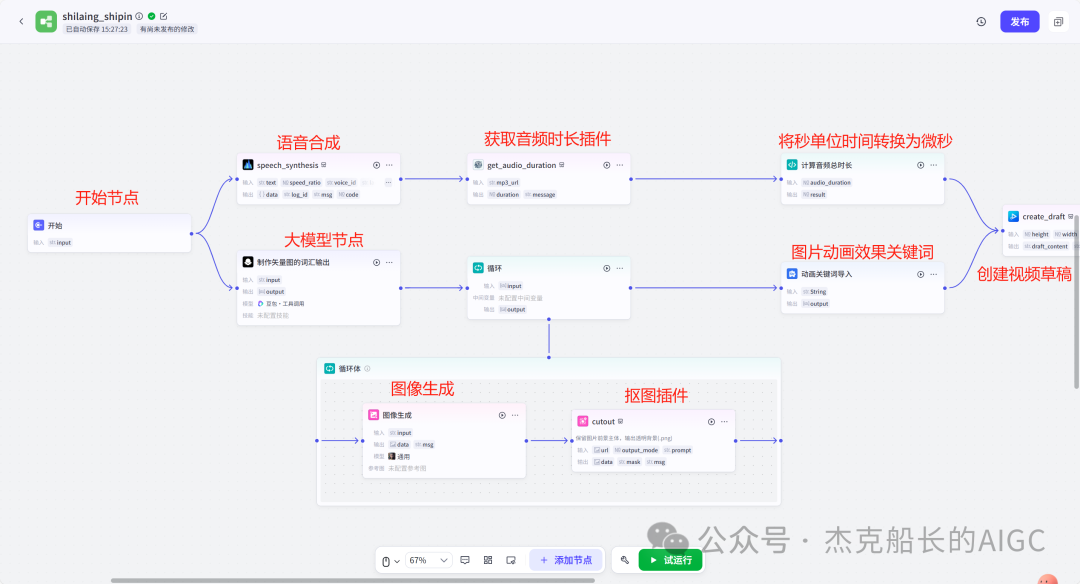


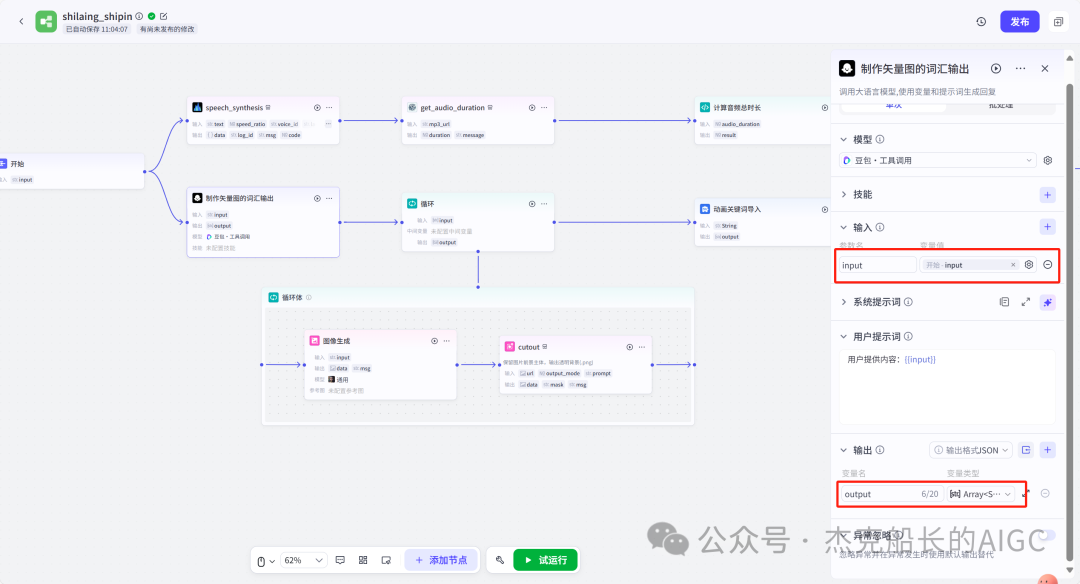
生成两个人型图案,一个为红色人型图案,一个为绿色人型图案,图标风格,纯白色背景,纸片人风格,{{input}}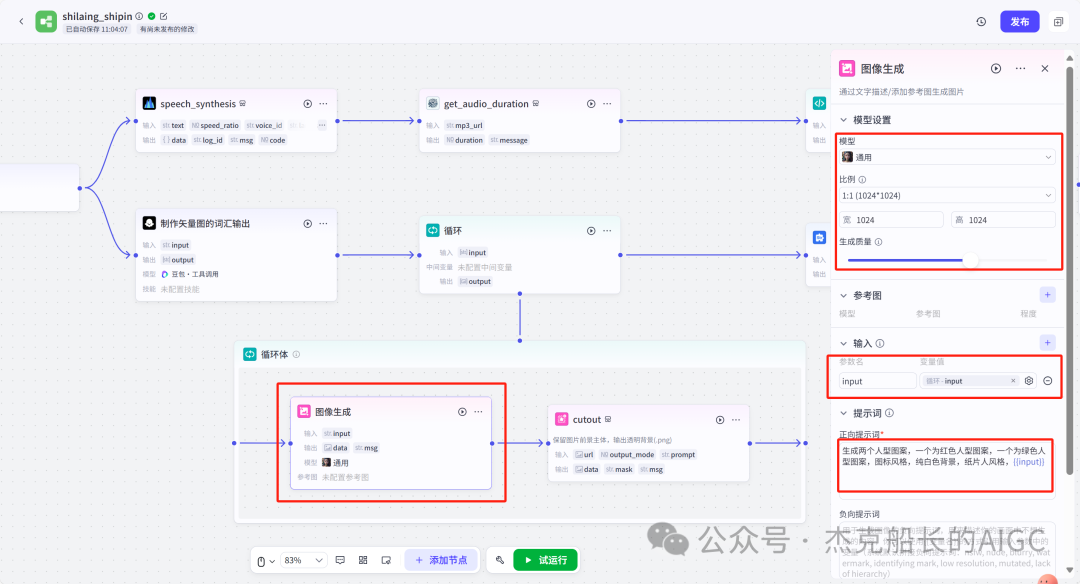
制作视频部分

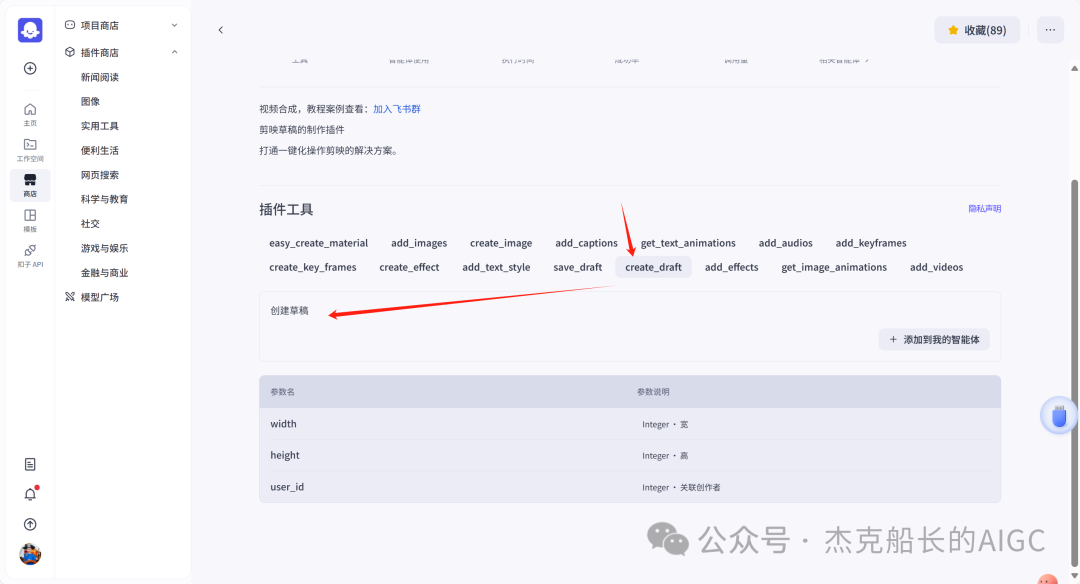
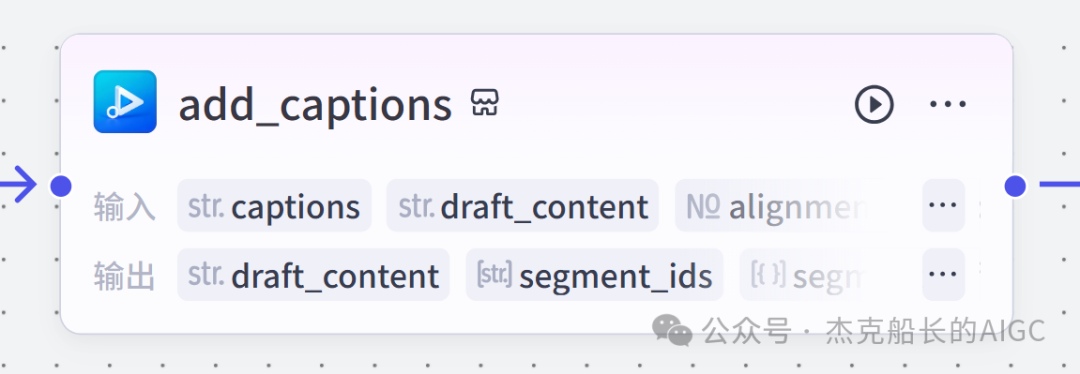
创建草稿
添加背景图片(两个节点)
[{"image_url": "{{String1}}","width": 1440,"height": 900,"start": 0,"end": {{String2}} }]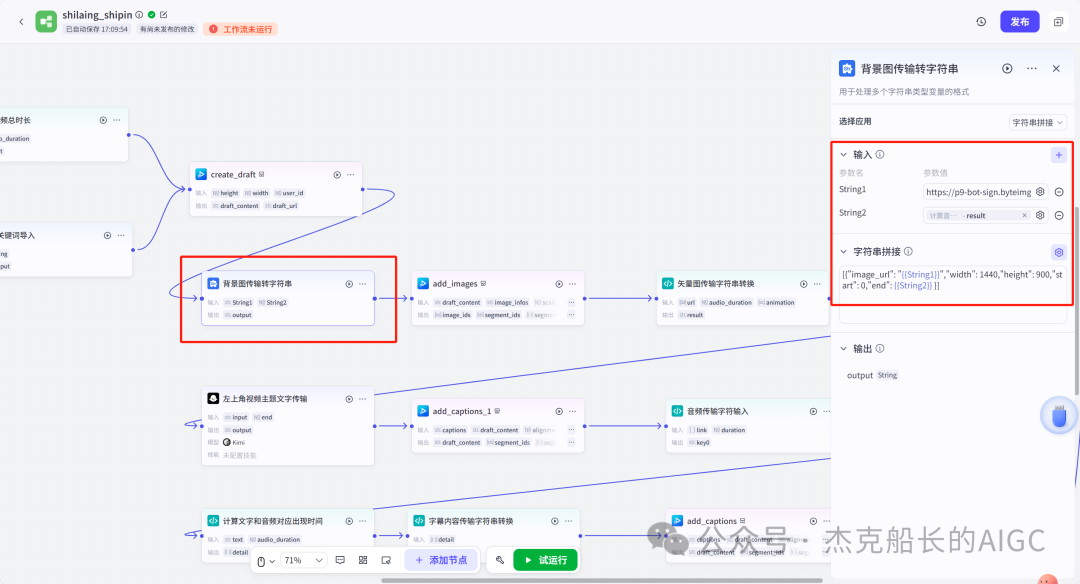
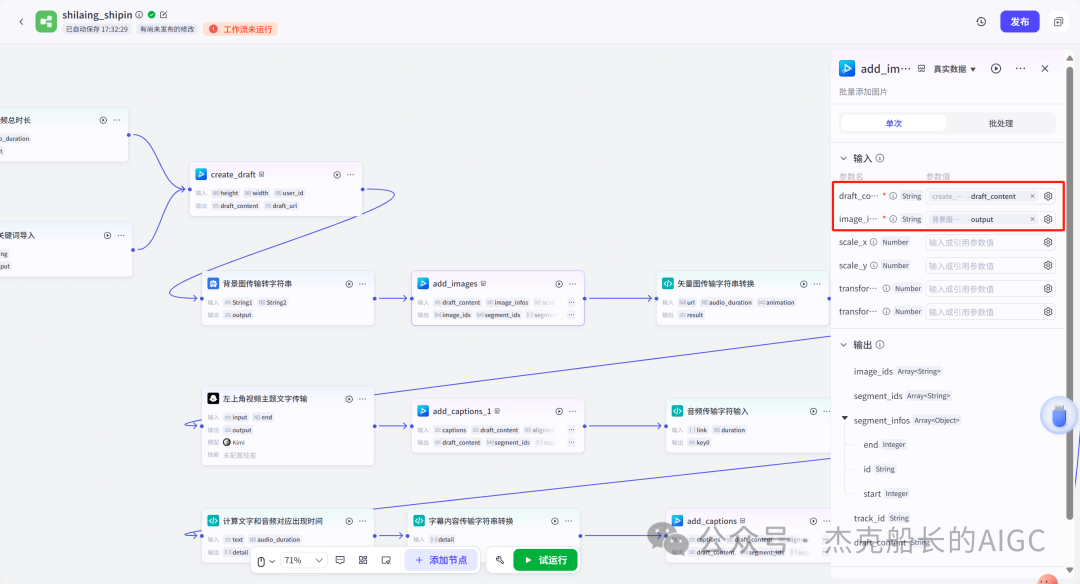
添加矢量icon图片(两个节点)
添加左上字幕(两个节点)
根据用户输入内容:{{input}},识别出一个主题不超过10字
## 输出格式(按编排好的内容进行输出)
[{"text":"{生成的主题内容}","start":0,"end":{{end}}}]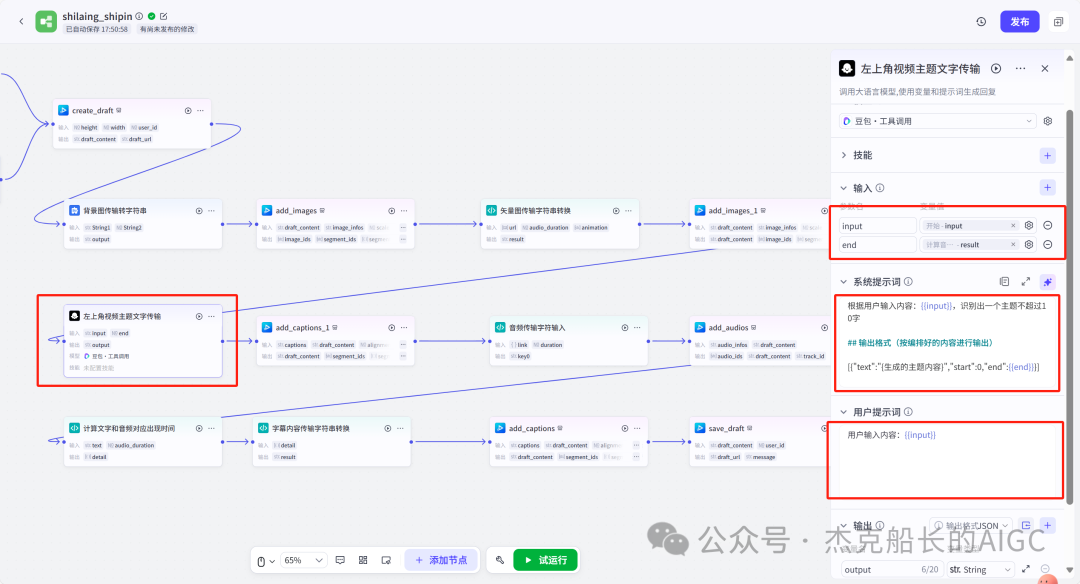
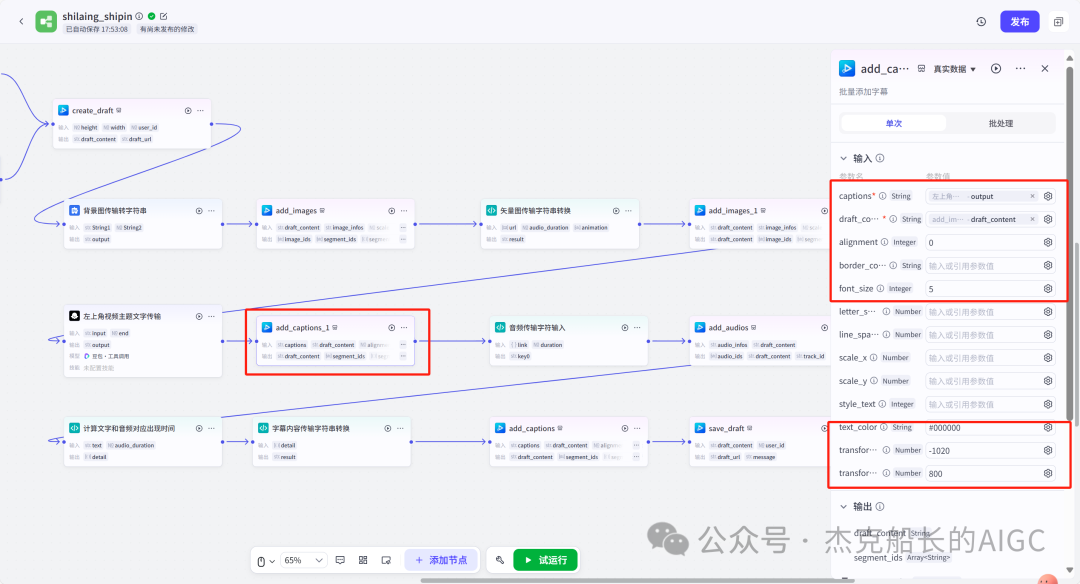
添加音频(两个节点)
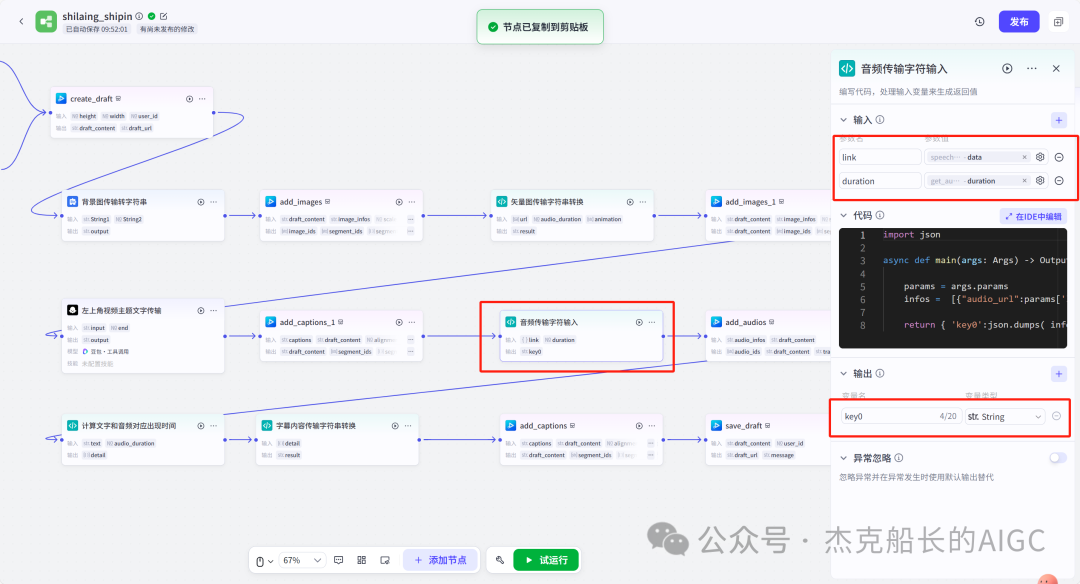
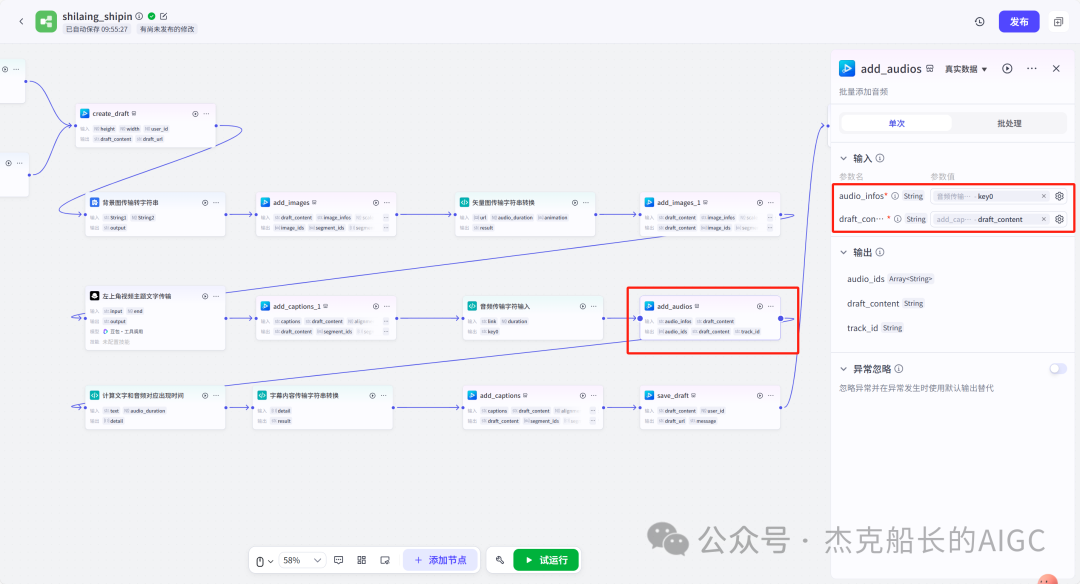
添加字幕主要字幕(三个节点)
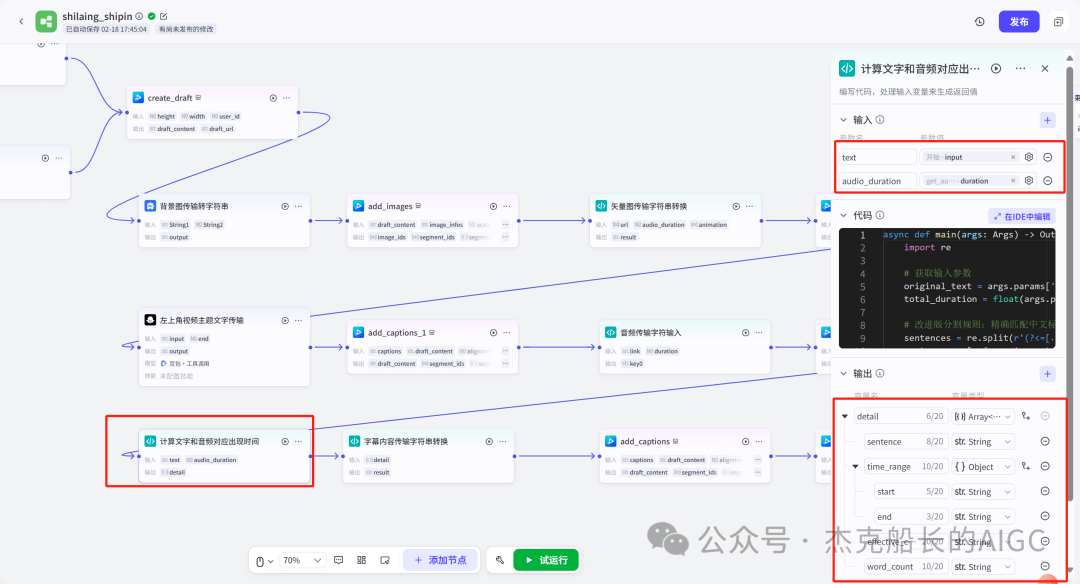
保存草稿
结束节点
第四点 视频工具使用和下载注意,其他需要注意点