作者:微信小助手
发布时间:2025-03-18T11:56:20
准备一个几十秒音频
准备下载安装用GPT-SoVITS webUI软件对音频训练模型
下载地址已放结尾,请去查看!!!!

点击go-webui.bat运行 启动WebUI在浏览器中访问http://127.0.0.1:7860/,即可在浏览器中使用GPT-SoVITS-WebUI。
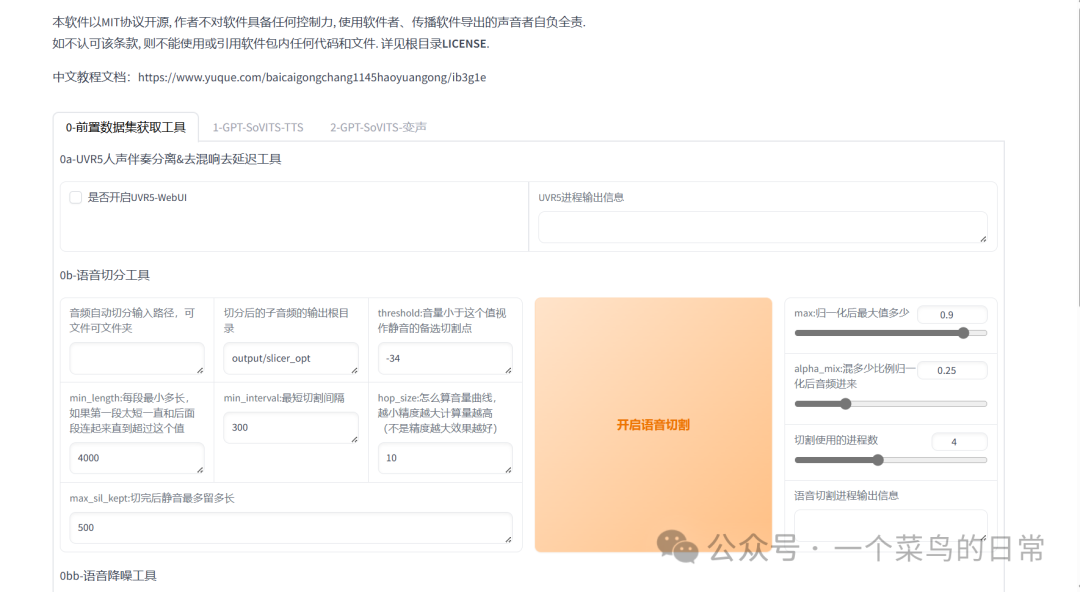
1.1 打勾:是否开启UVR5-WebUI

1.2 等待数秒后,自动弹出一个新页面(人声伴奏分离)。在该页面进行人声伴奏分离操作。
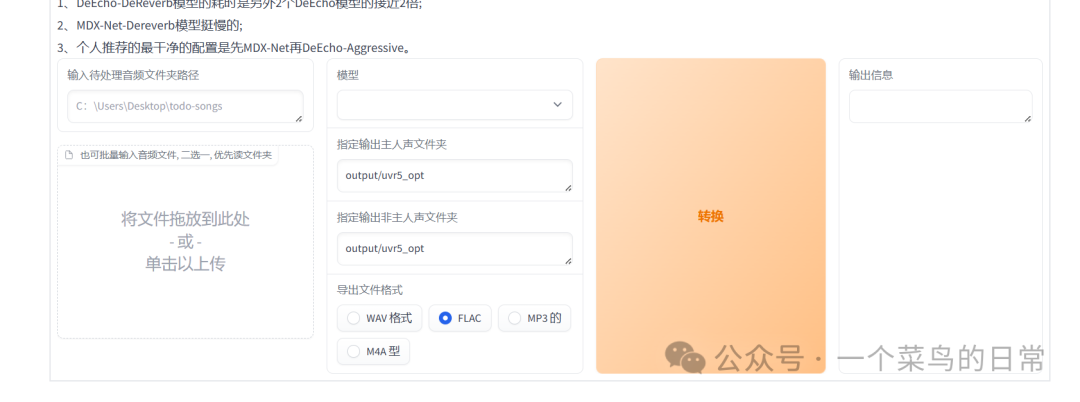
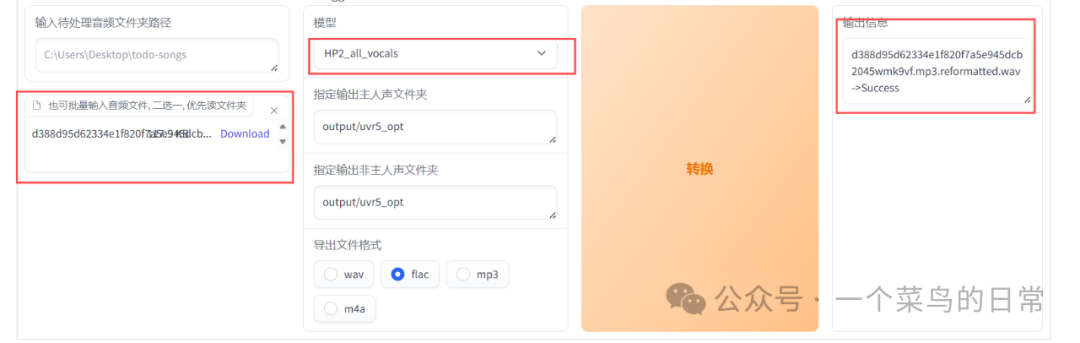
1.3 需要输入的有2个地方:把音频拖入或者点击上传和(模型)根据页面中的提示自行选择,其他不用管,输入完成后点击“转换”,输出信息为d388d95d62334e1f820f7a5e945dcb2045wmk9vf.mp3.reformatted.wav->Success,说明成功。
1.4:语音切分工具注意!!!
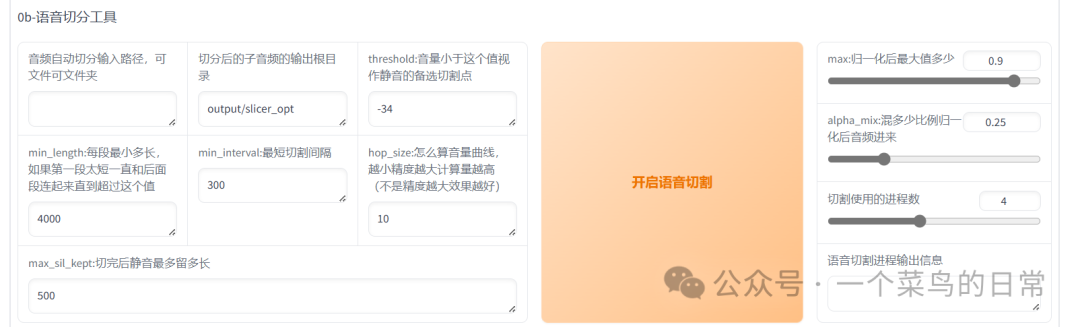
1.5:这里注意!!!
min_length建议将原值改为30(对于2分钟的音频而言)
min_interval建议将原值改为11(对于2分钟的音频而言)
低于2分钟不用管
格式:音频自动切分路径地址+音频.flac
路径输入完成点击开启语音切割,其他不用管。

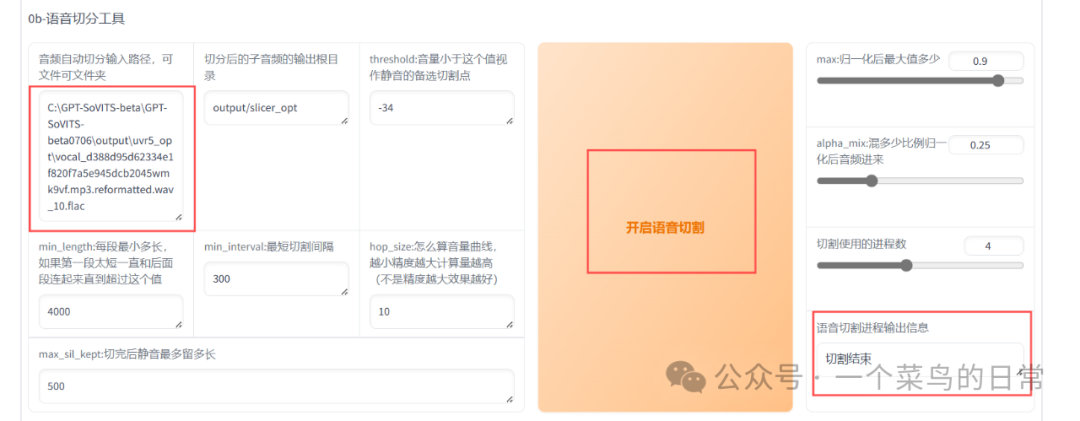

1.6: 切分后的音频数据集在这里
1.7:中文批量离线ASR
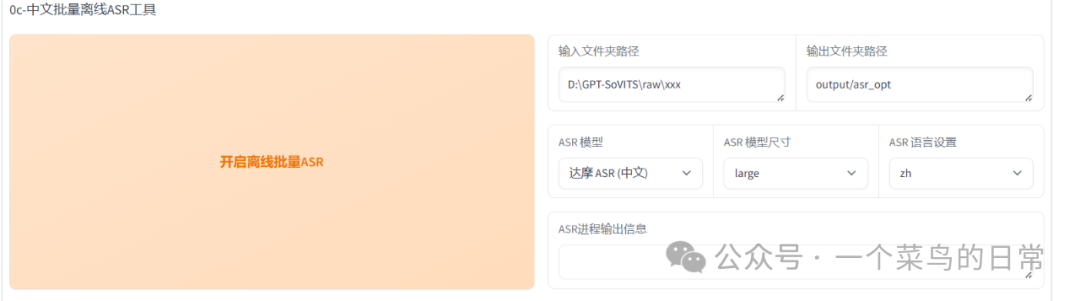
1.8:输入切分后的音频数据集文件夹路径,点击开启离线批量ASR。需要等一会ASR进程输出信息输出为:ASR任务成功,
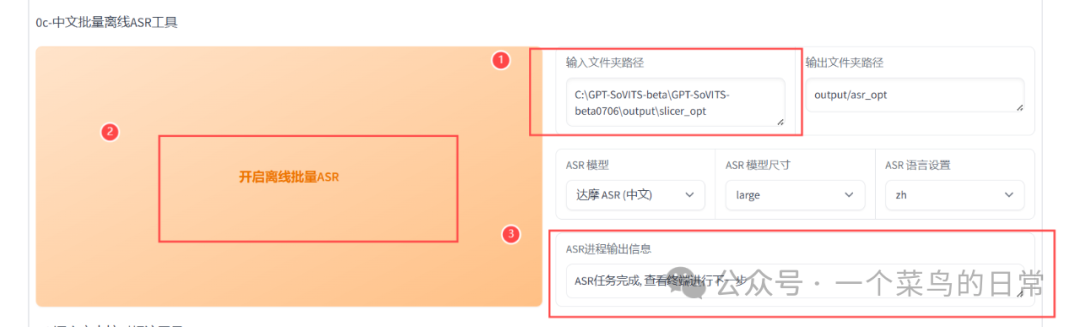
1.9:语音文本校对标注
输入 .list 标注文件的路径,看清再开启.


2.0:核对音频和文本是否对应。选中音频,可进行合并和删除操作。注意校对标注一个音频后及时保存,完成一页校对后,进入下一页继续标注。 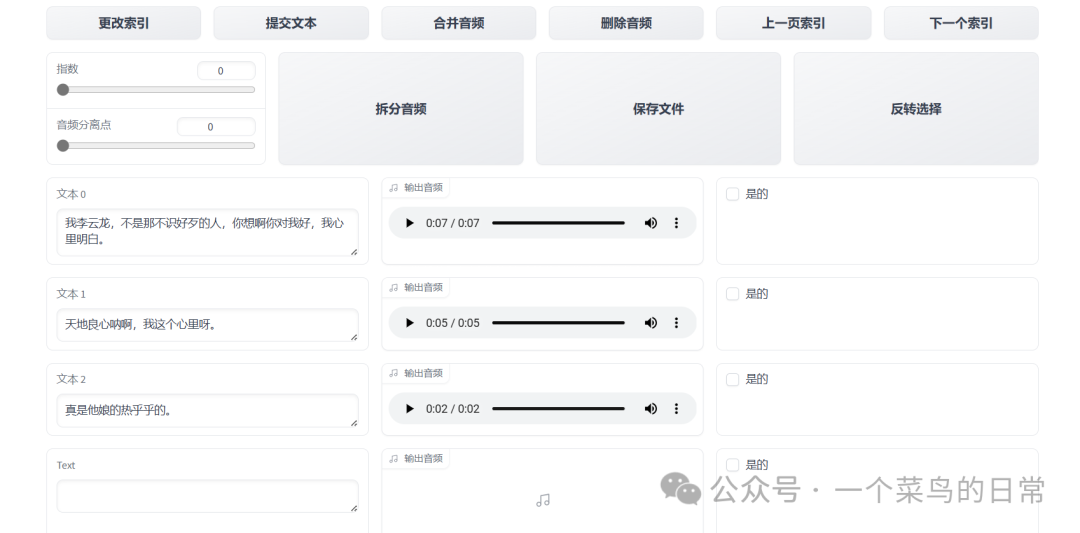
2.1:GPT-SoVITS-TTS对整理好的目标音频数据集,进行微调训练和推理。完成这一步,即可实现让目标声音说出任何文本内容,并进行测试试听。
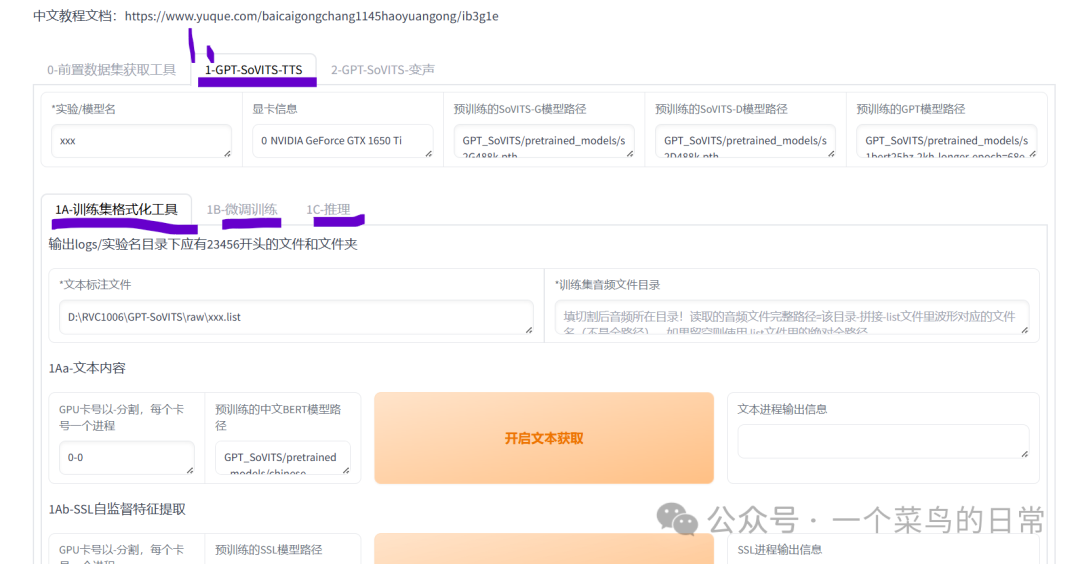
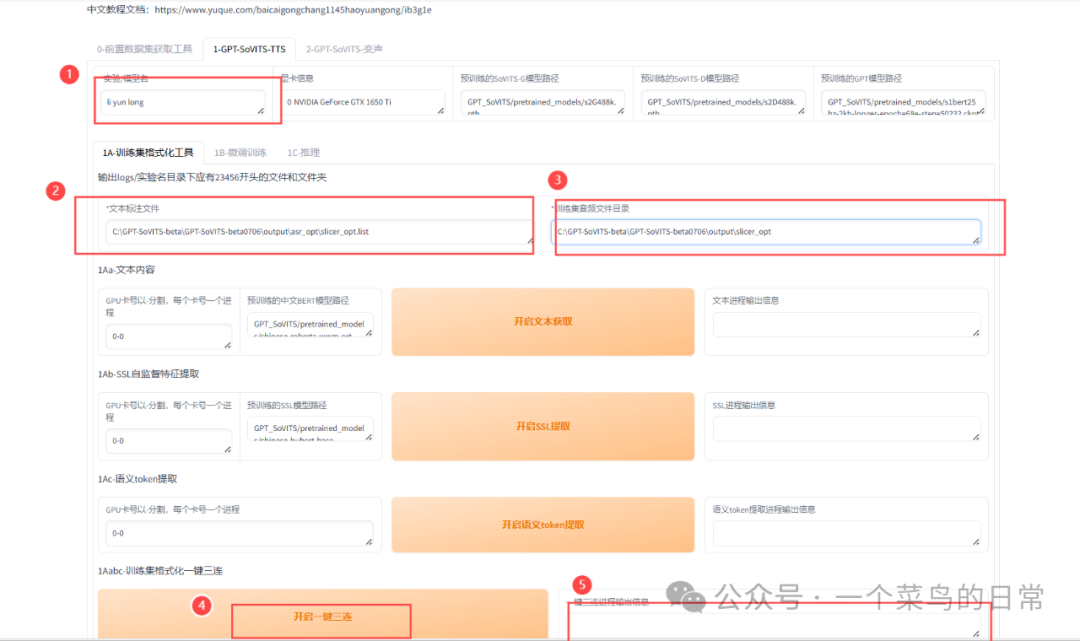
2.2: 命名该模型:如我要训练李云龙的声音,将模型命名为liyunlong
注意:文本标注文件:输入上一步标注好的文件路径(.list文件路径,不是文件夹路径)
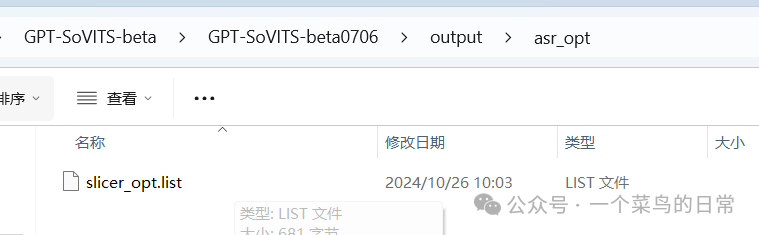
注意:训练集音频文件目录地址:

如图所示: 地址输入完成后,点击一键三连,等一会提示一键三连进程结束,完成!!!
2.3:点击1B-微调训练
直接(分别)点击开启SoVITs训练和开启GPT训练即可。当SoVITS训练进程输出信息和GPT训练进程输出信息分别显示SoVITS训练完成和GPT训练完成,同时后台无报错。表明训练成功。
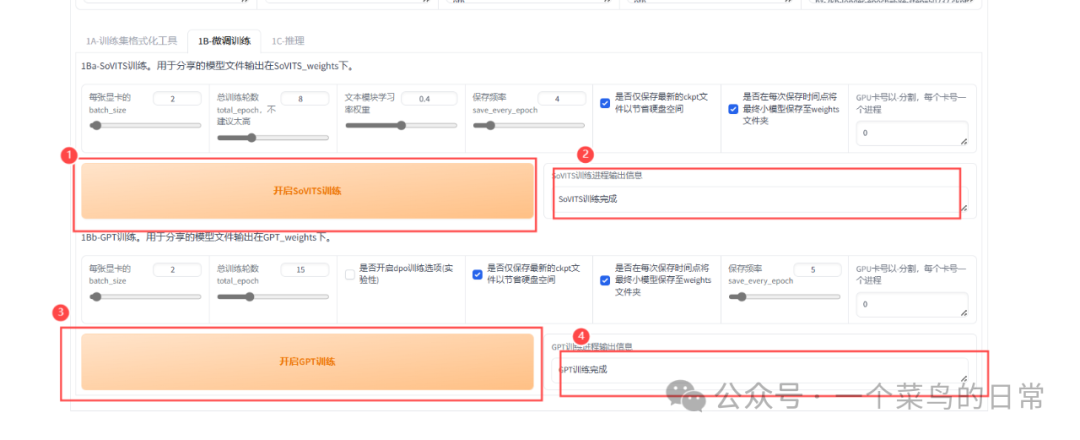
训练完成后,训练出来的音频模型会分别显示在GPT_weights和SoVITS_weights文件夹中。
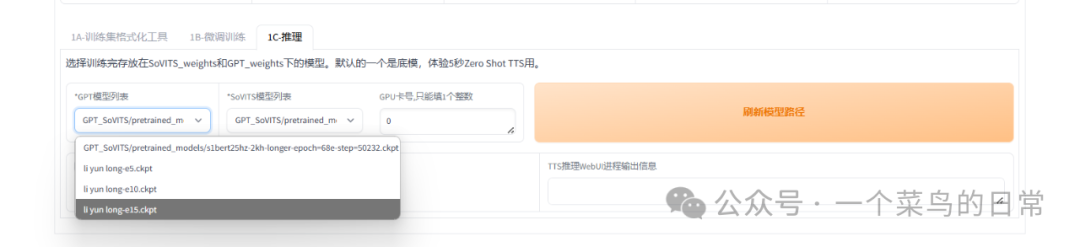
2.4:IC 推理
在推理页,点击刷新模型路径,即可在GPT模型列表中看到上一步训练的音频模型:li yun long

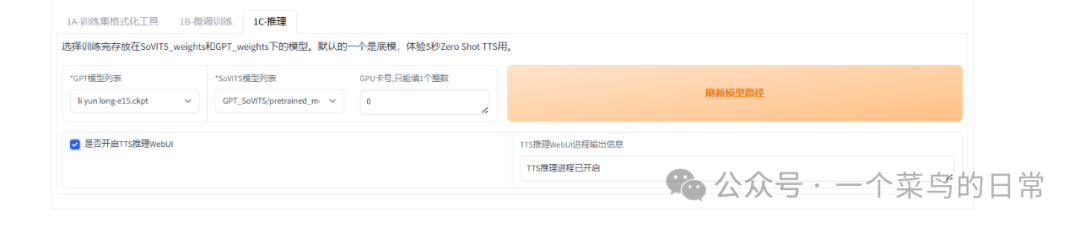
2.5:打勾:是否开启TTS原理webUI。等待一会,自动打开一个页面在开启的TTS原理webUI进行操作
2.6:上传参考音频文件,以及对应该参考音频的文本内容。参考音频的语种选择中文即可。
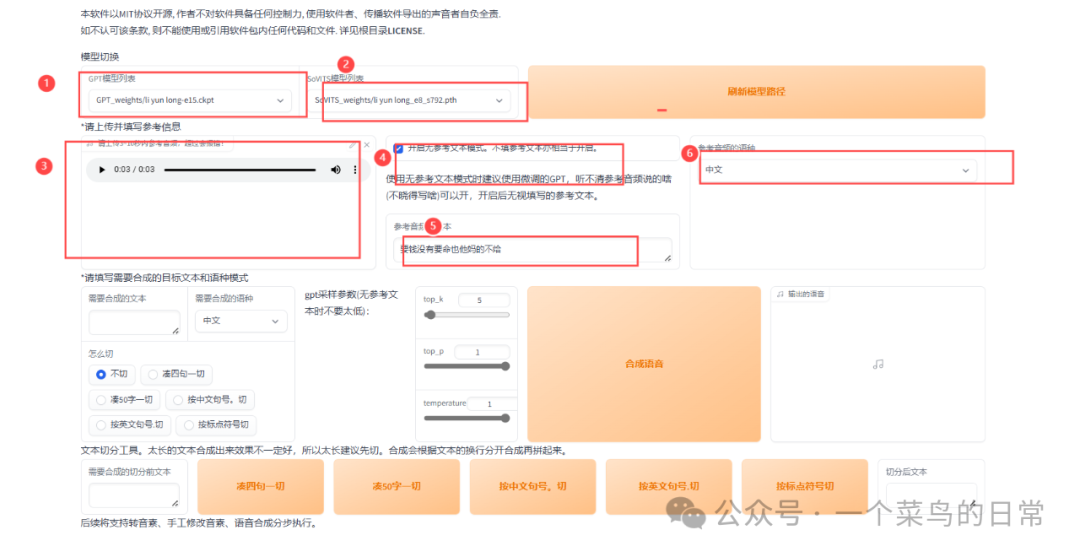
推理前我们需要给它一个目标音色参考音频,可以在\logs\YeShu\5-wAV32k路径下取一个音频。
参考音频文本可以在\logs\YeShu\这个路径的这个文件里找到。
找不到自己去找对应训练的模型音频,随便弄个参考音频和文本输上,
2.7:输入需要合成的文本:即想让训练的声音说什么内容,然后点击合成语音即可在右侧输出的语音中试听声音效果。

2.8:实时变声,后续的变声部分还在施工当中。

结束语:
GPT-SoVITS-WebUI凭借其强大的功能和易用性,为语音技术的爱好者和开发者提供了一个强大的工具。它使得语音合成、识别和处理变得更加高效和便捷。随着技术的不断发展,我们期待GPT-SoVITS-WebUI能在未来的日子里,为语音技术的探索和应用带来更多的可能性。
下载地址:出于对原作者的尊重,我不会直接提供整合包的网盘链接,有需要的可以按照提示,给 @花儿不哭 发私信获取,或者从 Github 下载
附原出处开源地址:https://github.com/RVC-Boss/GPT-SoVITS