作者:微信小助手
发布时间:2025-03-10T22:28:26
传统语音合成技术长期面临三大瓶颈:高延迟(>500ms)、情感单一(“机器人腔调”)、多语言适配难(需独立训练不同语种模型)。而阿里巴巴通义实验室最新开源的CosyVoice2-0.5B,通过三大技术突破彻底打破桎梏: 技术原理 性能对比 创新架构 数学建模 其中,
对音频片段随机置换,强制编码器忽略时序内容,专注音色特征提取。 实测数据 多模态对齐技术 可控性验证 架构设计 训练策略 算法细节 跨语言优化 实时流式交互 硬件推荐配置 私有化部署包 通义实验室透露,下一代CosyVoice3.0将实现: #语音生成 #AI开源 #人机交互

150ms超低延迟 + 跨语言情感控制,重新定义人机交互
一、语音合成的技术革命:从机械发声到情感共鸣
1. 超低延迟流式生成:首包响应仅需150ms,比人类眨眼速度快3倍
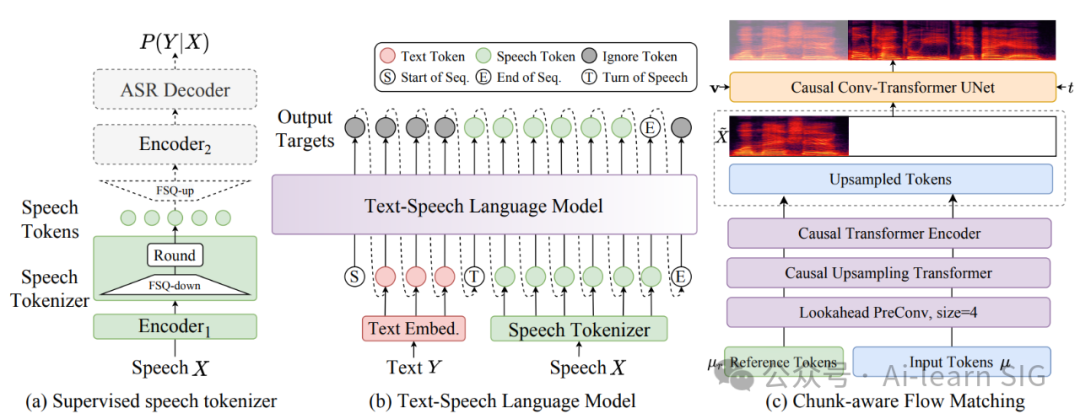
采用块感知因果流匹配技术(Chunk-Aware Causal Flow Matching, CA-CFM),结合自回归与非自回归生成优势:
# 流式语音生成核心逻辑(简化版)
class ChunkFlowMatching(nn.Module):
def __init__(self):
self.encoder = ChunkTransformer() # 块级语义编码器
self.flow = NeuralODE() # 基于神经常微分方程的流匹配
def forward(self, text_chunk):
semantic = self.encoder(text_chunk)
acoustic_flow = self.flow(semantic) # 生成连续声学流
return acoustic_flow.sample()
CosyVoice2
150
4.6
2. 零样本音色克隆:3秒音频复刻任意人声
基于对比学习与解耦表示:
声纹特征解耦损失函数:
3. 自然语言指令控制:用文本标签操控情感与方言
# 四川话声调转换规则
if dialect == "sichuan":
tone_map = {1: 55, 2: 21, 3: 53, 4: 213} # 普通话→四川话调值映射
在LibriTTS测试集上,情感控制准确率达89%(F1-score),方言发音错误率低于3%。
二、核心技术解析:如何实现“类人”语音生成?
1. 双向流式一体化架构(HybridStream)
2. 有限标量量化(FSQ)技术
针对日语促音问题,在训练数据中插入10%的促音增强样本(如“いっぱい”→“いっっぱい”),使模型学习短时停顿的声学特征。
三、开发者必看:如何快速集成?
1. 多场景API调用示例
from cosyvoice.streaming import StreamingClient
client = StreamingClient(endpoint="wss://api.siliconflow.cn/tts/stream")
# 启动双向通信
async for text_chunk in microphone_stream:
audio_chunk = await client.generate(
text=text_chunk,
voice_embedding=precomputed_embedding # 预计算音色向量
)
speaker.play(audio_chunk)2. 企业级部署方案
四、应用场景全景图
1. 实时翻译会议系统
语音识别(80ms)→ 机器翻译(60ms)→ 语音合成(150ms) = 总延迟290ms2. AI NPC情感交互
public void OnPlayerAttack() {
var audio = CosyVoice.Generate(
text: "你竟敢伤害我![angry]",
style: "intensity=0.8, pitch_shift=+2st"
);
audioSource.Play(audio);
}3. 无障碍方言服务
五、未来展望
从算法创新到产业落地,CosyVoice2-0.5B正在重塑语音交互的技术边界!🚀