作者:微信小助手
发布时间:2025-03-03T09:40:01
Milvus 是一个开源的、高性能、高扩展性的向量数据库,专门用于处理和检索高维向量数据。它适用于相似性搜索(Approximate Nearest Neighbor Search,ANN),特别适合AI、推荐系统、计算机视觉、自然语言处理(NLP)等领域。Milvus 由 Zilliz 开发,并已捐赠给 LF AI & Data 基金会。 向量是神经网络模型的输出数据格式,可以有效地对信息进行编码,在知识库、语义搜索、检索增强生成(RAG)等人工智能应用中发挥着举足轻重的作用。 文本、图像和音频等非结构化数据格式各异,并带有丰富的底层语义,因此分析起来极具挑战性。为了处理这种复杂性,Embeddings 被用来将非结构化数据转换成能够捕捉其基本特征的数字向量。然后将这些向量存储在向量数据库中,从而实现快速、可扩展的搜索和分析。 Milvus 提供强大的数据建模功能,使您能够将非结构化或多模式数据组织成结构化的 Collections。它支持多种数据类型,适用于不同的属性模型,包括常见的数字和字符类型、各种向量类型、数组、集合和 JSON。 Milvus 提供三种部署模式,涵盖各种数据规模: Milvus 主要由以下组件组成: Milvus 的云原生和高度解耦的系统架构确保了系统可以随着数据的增长而不断扩展: Milvus 本身是完全无状态的,因此可以借助 Kubernetes 或公共云轻松扩展。此外,Milvus 的各个组件都有很好的解耦,其中最关键的三项任务--搜索、数据插入和索引/压实--被设计为易于并行化的流程,复杂的逻辑被分离出来。这确保了相应的查询节点、数据节点和索引节点可以独立地向上和向下扩展,从而优化了性能和成本效率。 Milvus 支持各种类型的搜索功能,以满足不同用例的需求:1. 非结构化数据、Embeddings 和 Milvus
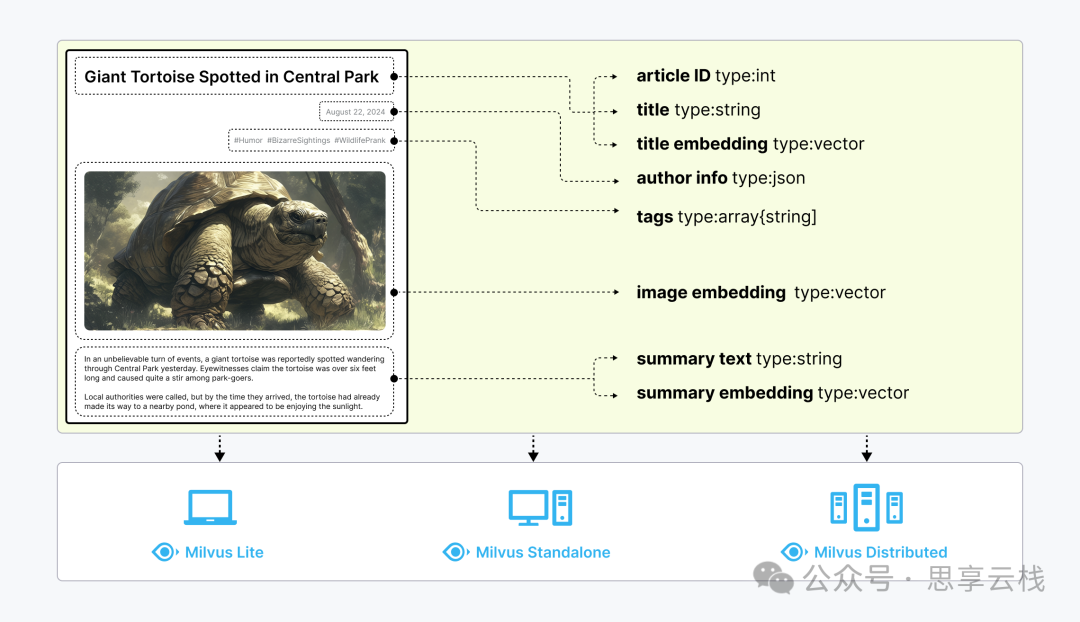
2. Milvus架构
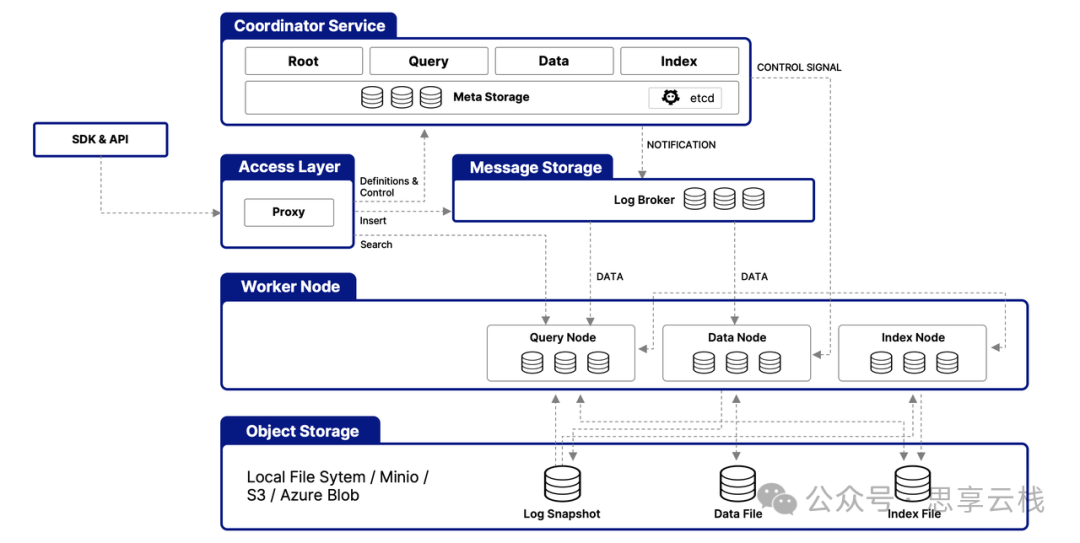
3. Milvus 支持的搜索类型
4. 相关资料