作者:微信小助手
发布时间:2025-03-03T07:58:05
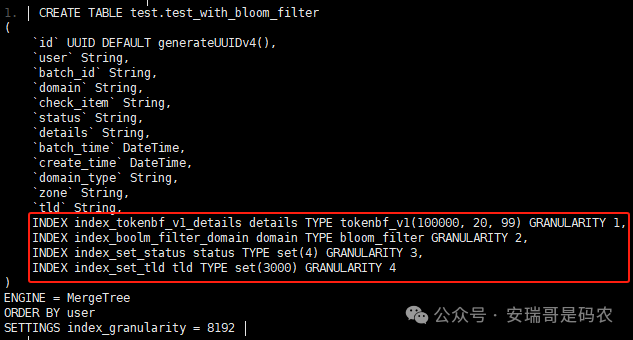
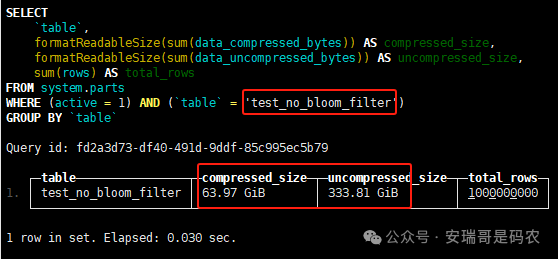
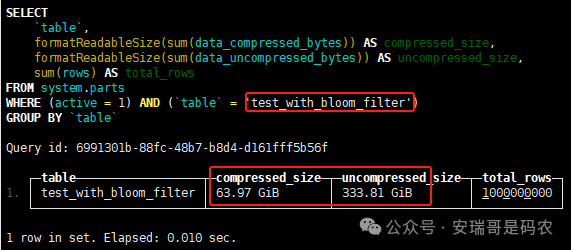
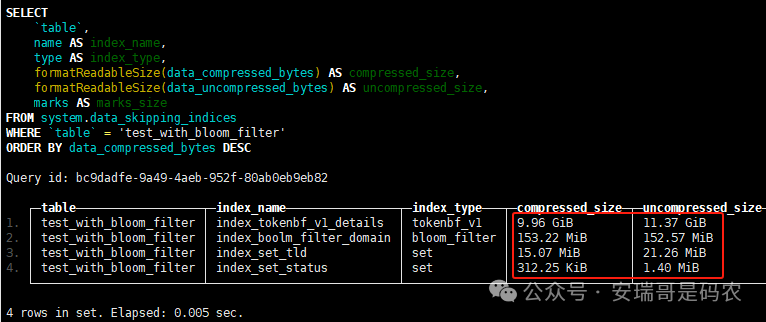
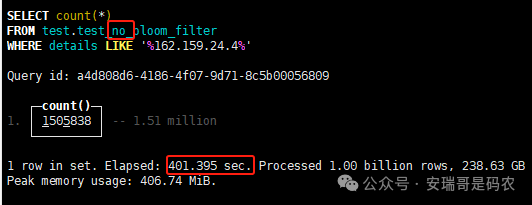
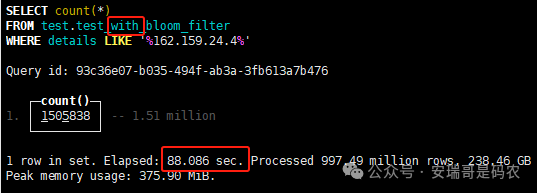
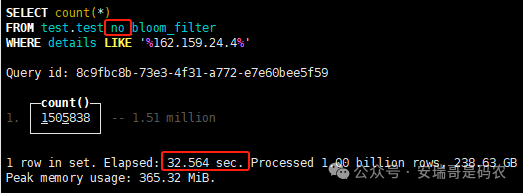
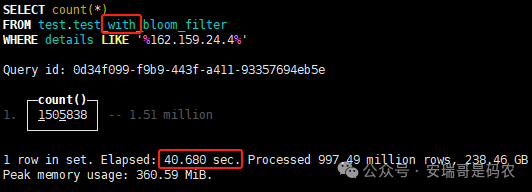
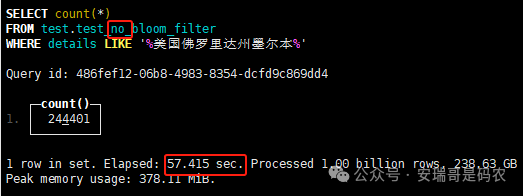
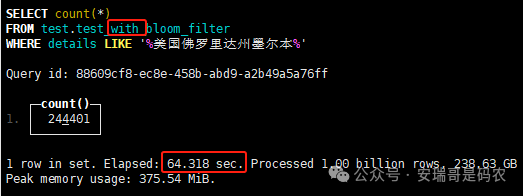
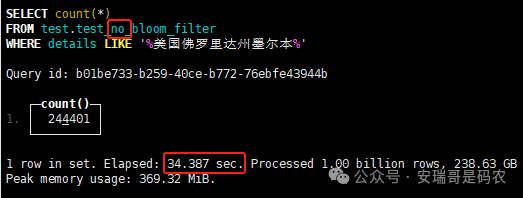
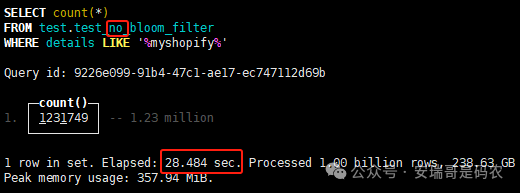
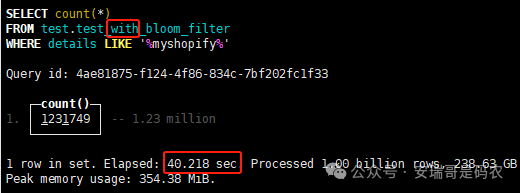
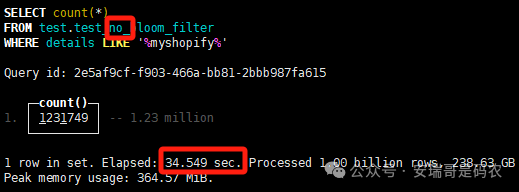
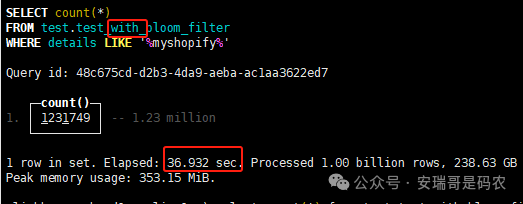
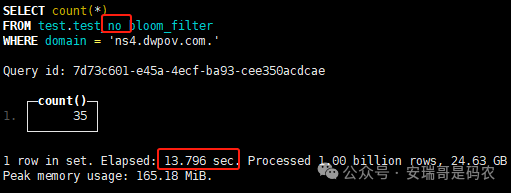
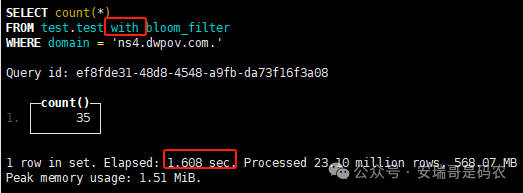
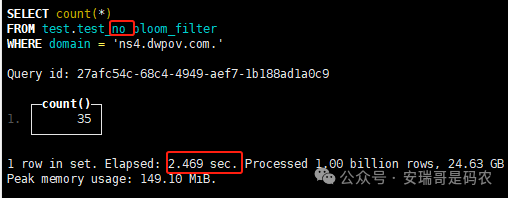
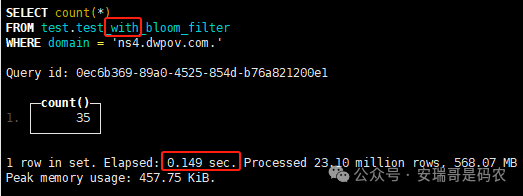
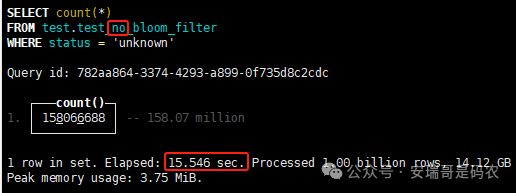
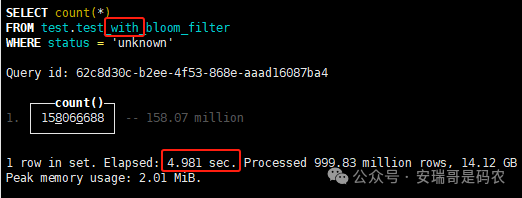
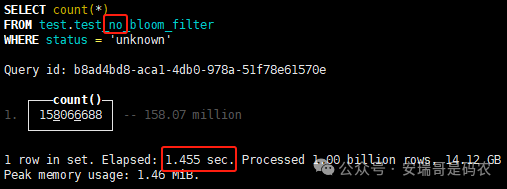
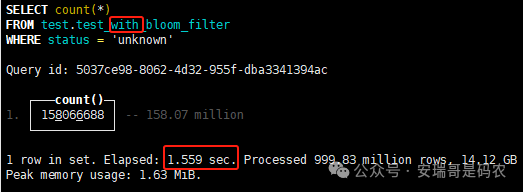
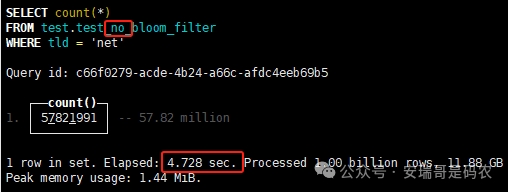
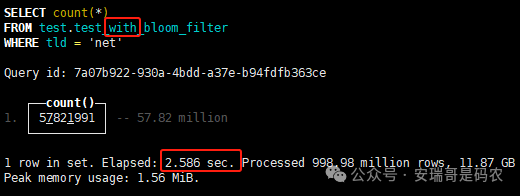
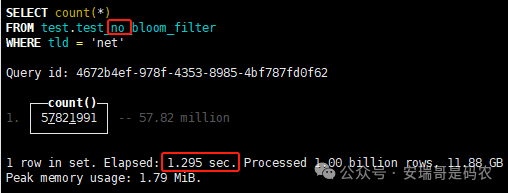
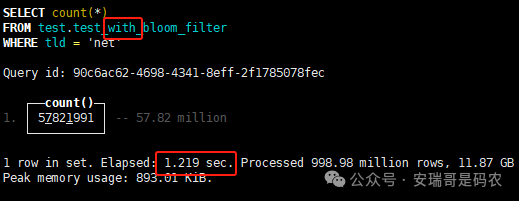
上期内容在对 Flink 的背压问题进行二次优化时,用到了 Redis 的布隆过滤器,其实当时在方案选型时发现,原来 clickhouse 也是有这么个东东的。 说到底,不管是 Redis 还是 CK 的布隆过滤器(Doris 也有),本质目的都在于「快速过滤」掉不相关数据(本质上,所有的索引都是这个目的)。 之所以上次的 Flink 背压问题没有选择 CK 的布隆过滤器,根本原因在于: 即便在被碰撞的 CK 表里,对查询字段启用了它,本质上还是基于「磁盘IO」,对于问题的解决可能帮助并不算太大。 那么今天这篇文章,我们就一起来聊聊 CK 的布隆过滤器,以及测试一下它的性能表现,看它到底值不值得一用。 0. 概念理一下 首先我们要明晰一个问题,那就是 CK 的索引种类到底有哪些? 总结起来有两大类:「主键索引(primary key index)」跟「跳数索引(data skipping index)」。 不知道有多少同学跟我一样,至今为止,暂时还没用过 CK 除主键索引之外的的其他索引功能(可能是就算不用,查询效率就足够快了吧)。 而一开头提到的 CK 布隆过滤器,其实就属于「跳数索引」中的 3 种实现。 为啥是 3 种? 根据 CK 官网的介绍,它的「跳数索引」一共分为 5 个小类: 类1,MinMax 索引:这个好理解,从名字就可以知道,它是用来额外记录某个列的最大值,跟最小值的; 类2,Set 索引:底层实现应该就是一个哈希表,用来存储某个列中的「不同值」,根据经验应该知道,这个索引类型,特别适合那种「低基列」,而且它可以接收一个参数,用来确定底层哈希表数组的大小。 比如对于一个枚举字段来说,你明明知道它的值一共就 100 种,那就直接设置为 set(100) 好了,避免了哈希表数组需要中途为了扩容,要额外重建的麻烦; 类3,普通布隆过滤器:之所以普通(对比后面 2 种特殊的),原因在于你写进什么数据,它就给你存什么,不给你额外做任何处理。 一般而言,布隆过滤器至少要接受 2 个参数(对比上次说的 Redis 布隆过滤器),但这里,只需要设置一个你期望的「误判率」就可以,其他的比如底层「位数组大小」,「哈希函数个数」,都交由 CK 自己去计算; 类4,N-gram 布隆过滤器(N-gram Bloom Filter):一种特殊的布隆过滤器,特殊之处在于它会对你写进来的数据先进行「切词」,而它的切词规则,则是基于这个 N 来确定,假如 N 为 3 ,对于字符 clickhouse,会被切为 cli、lic、ick、ckh、kho、hou、ous、use 这些碎字符,然后再写到布隆过滤器里,相比普通布隆过滤器原来的「只写一份」,变成了「要写多份」; 类5,token 布隆过滤器(Token Bloom Filter):另一种特殊的布隆过滤器,跟上面一样,也需要先对存进来的数据(比如字符),进行切词,只不过它的切词规则,很像我们熟悉的「倒排索引」,默认会根据「非文字或者英文字符」(比如空格、各种标点符号等)进行切分,同样也是要将切分后的 token,全部写入到布隆过滤器。 1. 布隆过滤器间的对比 对于 CK 的这 3 种布隆过滤器来说,第 1 种普通的布隆过滤器,很明显最适合那种「以整个内容作为搜索条件」的字段。 而对于 N-gram 布隆过滤器,因为它的特点是属于毫无章法的「无脑切」,适合那种脑子不清醒,只能大概记住一些「模糊字符片段」(甚至允许个别错误)的搜索方式,存储的字段内容,一般是一大段的文本。 对于 token 布隆过滤器,相比 N-gram 的无脑切词,要更符合人理解的切词规则,适合那种对「某个关键字」进行准确搜索匹配的方式,存储的字段内容,同样也一般是一大段文本。 2. 测试案例准备 上面理论罗里吧嗦说了那么多,这个 CK 支持的「跳数索引」的几种布隆过滤器,到底使用起来表现怎么样? 前面说过,因为之前的经验,很多时候我们就算不用这个「跳数索引」,CK 的查询效率也是能让人满意的,那为了尽可能凸显出使用它的价值,我这里准备了 2 张存储相同 10 亿条数据的表。 其中第 1 张表不添加「跳数索引」,表结构如下: 第 2 张表,根据字段特点添加了「跳数索引」,表结构如下: 瞅一眼数据量: 2.1 写入速度对比 同样的一份 10 亿数据,写入到不带「跳数索引」表里,需要的总时间: 为 3653 秒。 而写入到带有 4 个「跳数索引」的表里,需要的总时间: 为 12141 秒,是上面的 3.3 倍。 很明显,因为索引过程需要额外花时间,所以需要的写时间会更长。 2.2 存储大小对比 对于 CK 来说,原始数据占用大小跟「跳数索引」占用大小,是通过不同的元数据表进行统计的。 单纯从原始数据占用大小来看,用不用「跳数索引」,存储大小都一样: 非跳数索引表的原始数据存储大小 带跳数索引表的原始数据存储大小 对于额外的「跳数索引」占用情况如下: 从查询到的元数据来看,额外创建的「跳数索引」,需要的磁盘空间接近 10G(压缩后)。 3. 查询效率测试 因为这份数据有多个不同字段,且字段间的数据特点各不相同,这里根据字段特点,以及不同「跳数索引」的适配场景,分别创建了:token 布隆过滤器、普通布隆过滤器、以及 2 个 Set 过滤器。 3.1 token 布隆过滤器效率测试 之所以会创建这个「跳数索引」,因为这个 details 字段的数据内容非常丰富,类似长这样: 测试条件01:查找这个字段包含 IP 为「162.159.24.4」的记录总数。 第 1 次测试: 无索引表的效率: 耗时 401 秒。 有索引表的效率: 耗时 88 秒。 很明显,第 1 次测试时,带索引的表查询效率,要明显比不带索引的高出几倍。 第 2 次测试: 无索引表的效率: 耗时 32 秒 (效率大幅提高)。 有索引表的效率: 耗时 40 秒。 而第 2 次测试,因为缓存的原因,不带索引表的查询效率反而超过了带索引的表效率。 而且后续经过多次测试确认,针对这个 IP 查询场景,带索引的查询效率,跟不带索引的相比,效率已经没有了优势。 测试条件02:查询包含汉字「美国佛罗里达州墨尔本」的数据条数。 第 1 次测试: 无索引表的效率: 耗时 57 秒 有索引表的效率: 耗时 64 秒。 虽然差不多,但有索引的查询效率居然还要更慢一点。 第 2 次测试: 无索引表的效率: 耗时 34 秒。 有索引表的效率: 耗时 49 秒。 第 3 次、第 4 次... 这轮测试中,带索引表的效率表现,总体都不如不带索引表的效率。 测试条件 03:查找这个字段包含关键字「myshopify」的记录总数。 第 1 次测试: 无索引表的效率: 耗时 28 秒。 有索引表的效率: 耗时 40 秒。 第 2 次测试: 无索引表的效率: 耗时 34 秒。 有索引表的效率: 耗时 36 秒。 还是一样,不管后续查多少次,带索引跟不带索引的查询效率虽然总体上差不多,但依然还是不带索引的效率略胜一筹。 好了,就测到这样,基本上可以得出结论:对于当前场景(数据特点),「token 布隆过滤器」的表现非常鸡肋,除了徒增存储空间外,几乎没有表现出任何优势(偶尔一次),差评! 3.2 普通布隆过滤器效率测试 这次针对的是域名字段,字段名为 domain。 测试条件:查找 domain 值为「ns4.dwpov.com.」的数据条数。 第 1 次测试: 无索引表的效率: 耗时 13 秒。 有索引表的效率: 耗时 1 秒。 第 2 次测试: 无索引表的效率: 耗时 2 秒。 有索引表的效率: 耗时 0.1 秒。 经过多次测试,可以得出结论:针对当前场景,「普通布隆过滤器索引」表现出了应有的水准,确实能大幅提高查询效率。 3.3 Set 索引效率测试 这个索引一般会被应用到「低基列」,对于当前这张测试表,有 2 个地基列:tld 跟 status。 这两个字段的区别在于,tld 的基数为 1000+,而 status 的基数则只有 4 个。 测试条件 01:查找 status 为「unknown」的数据条数。 第 1 次测试: 无索引表的效率: 耗时 15 秒。 有索引表的效率: 耗时 4 秒。 第 2 次测试: 无索引表的效率: 耗时 1 秒多。 有索引表的效率: 耗时也 1 秒多。 测试条件 02:查找 tld 为「net」的数据条数。 第 1 次测试: 无索引表的效率: 耗时 4 秒。 有索引表的效率: 耗时 2 秒。 第 2 次测试: 无索引表的效率: 耗时 1 秒多。 有索引表的效率: 耗时也 1 秒多。 结论:CK 的 Set 索引也能表现出应有的水准,虽然效率提升没有那么惊艳,但额外占用的存储空间非常小,主打一个成本低,效果还可以。 最后 针对 CK 的这次「跳数索引」测试表现,总结如下: 1,表现最扑街的是「token 布隆过滤器」,消耗额外的存储空间最多(近10G),但表现却最差,甚至大部分时候有它,还不如没有(至于是不是我参数设置的不合理,有待进一步验证); 2,表现最好的要算是「普通布隆过滤器」,查询效率能明显提升的同时,消耗的额外存储空间也不高(约150MB),是这次测试的所有索引类型中,性价比最高的,好评; 3,至于 Set 索引,表现中规中矩,虽然没有提供多么惊艳的查询效率,但也实实在在提速了,也值得一个赞。