作者:微信小助手
发布时间:2025-02-26T11:39:31
过去一周,每天公众号和小红薯后台咨询RAG企业应用落地的私信又多了起来,目前已经从10+稳定在了 20+。承接了其中几个需求比较明确的项目,(目前3月底前排期已满),剩下的小部分接受了付费咨询。
在这个过程中很高兴能了解到很多之前没涉猎过的行业和场景,其中经常被集中问到的问题大概有四个:中小企业做RAG知识库落地选择框架哪个比较好?如果选择 RAGFlow 如何进行定制化开发?如何对文档中的图片进行识别检索?如何对复杂文档进行动态分块等。

关于选择什么框架的问题,仁者见仁,需要综合对比的盆友可以参考我之前发的那篇文章企业RAG落地避坑指南:自主开发 vs 三大框架,核心配置与选型全解析。这篇以 RAGFlow 框架为例,针对上述后三个问题结合目前团队实践经验,给各位做个分享,大家辨证参考。
毕竟,RAG并没有“一招鲜”的神奇魔法,传说那几个大厂手里掌握的RAG”核心技术“,私以为也是经过了必要且复杂的“策略优化-管道设计-训练-调优-发布”等专业开发流程,不过成熟的开源应用框架,无疑是更有想象空间的社会化大创新。
注:本篇会比较偏开发导向,非技术向盆友选择性翻翻就好。
以下,enjoy:
1
以上篇介绍的机械加工行业的维保场景为例RAGFlow+DeepSeek-R1:14b落地案例分享(足够详细):机加工行业设备维保场景,推荐先采用官方的 Python API 进行合理的优化配置后,再修改项目源码,最后根据业务目标做必要的高级优化拓展。此处附上一张个人项目实施过程中积累的些优化要点,供各位参考:
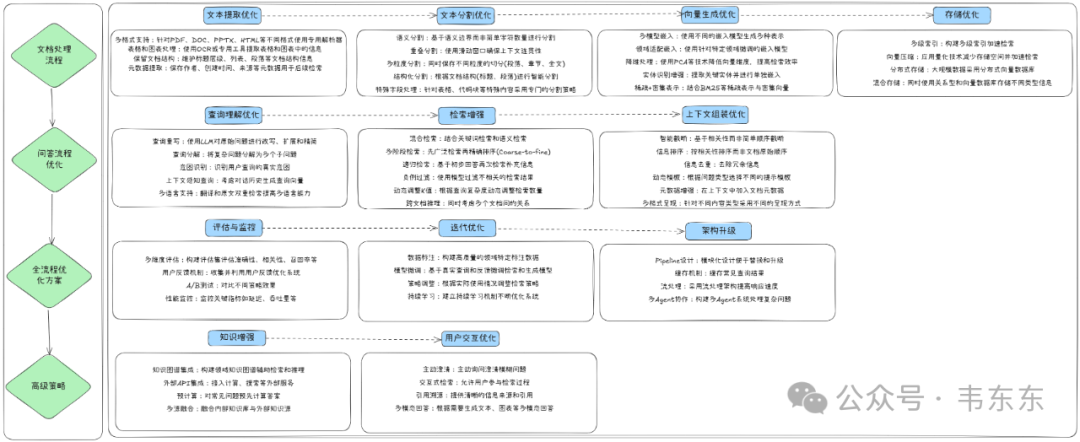
1.1
阶段一:API 优化配置
配置不同文档类型的解析策略
调整检索参数优化语义搜索质量
定制大模型提示词以适应机械行业特点
1.2
阶段二:基础源码修改
实现专业术语处理模块
开发查询路由机制
增加上下文增强功能
1.3
阶段三:高级优化扩展
实现多级索引结构
开发高性能缓存机制
添加查询日志分析系统
2
根据 RAGFlow 官方 Python API 文档,为大家完整梳理了所有可进行 API 优化的模块和参数。这些 API 调优可以不修改源码,直接通过参数配置实现性能提升。
建议在看完之后还是去官网看下原文,亲自动手试过一遍会有不一样的体感。原文出处:
https://ragflow.io/docs/dev/python_api_reference2.1
数据集管理
创建数据集 create_dataset
RAGFlow.create_dataset(name: str,avatar: str = "",description: str = "",embedding_model: str = "BAAI/bge-large-zh-v1.5",language: str = "English",permission: str = "me",chunk_method: str = "naive",parser_config: DataSet.ParserConfig = None)
优化参数:
embedding_model: 选择合适的嵌入模型,影响检索质量
中文场景推荐: "BAAI/bge-large-zh-v1.5"
英文场景可选: "BAAI/bge-large-en-v1.5"
language: 选择与文档匹配的语言
chunk_method: 关键参数,根据文档类型选择最佳分块策略
"naive": 通用文档
"paper": 论文/设备手册
"book": 结构化书籍
"table": 表格数据
"qa": 问答格式文档
"picture": 图片文档
"one": 整个文档作为一个块
"knowledge_graph": 知识图谱
parser_config: 精细调整解析配置
chunk_token_num: 控制分块大小
delimiter: 自定义分隔符
layout_recognize: 是否启用布局识别
raptor: 高级解析选项
更新数据集 DataSet.update
DataSet.update(update_message : dict) 优化参数:
embedding_model: 更换更适合的嵌入模型
chunk_method: 调整分块策略
meta_fields: 更新元数据字段
2.2
文件管理 (FILE MANAGEMENT)
上传文档 DataSet.upload_documents
DataSet.upload_documents(document_list : list[dict]) 优化参数:
display_name: 文件显示名,方便检索与管理
blob: 文件内容
更新文档 Document.update
Document.update(update_message : dict) 优化参数:
chunk_method: 文档分块方法
parser_config: 文档解析配置
对于图文文档,可设置: "layout_recognize": True
对于表格文档,可设置: "html4excel": True
解析文档
DataSet.async_parse_documents(document_ids : list[str]) 用于触发文档解析流程,支持批量处理。
2.3
分块管理 (CHUNK MANAGEMENT)
添加分块 Document.add_chunk
Document.add_chunk(content: str, important_keywords: list[str] = [])优化参数:
important_keywords: 关键词标注,增强检索相关性
更新分块 Chunk.update
Chunk.update(update_message : dict) 优化参数:
content: 更新分块内容
important_keywords: 更新关键词
available: 控制分块可用性
检索 RAGFlow.retrieve(关键API)
RAGFlow.retrieve(question: str = "",dataset_ids: list[str] = None,document_ids: list[str] = None,page: int = 1,page_size: int = 30,similarity_threshold: float = 0.2,vector_similarity_weight: float = 0.3,top_k: int = 1024,rerank_id: str = None,keyword: bool = False,highlight: bool = False)
优化参数 (最重要的检索相关参数):
similarity_threshold: 相似度阈值,影响召回范围
vector_similarity_weight: 向量相似度权重与关键词匹配权重的比例
设置为 0-1 之间,值越大向量权重越高
工业领域建议参考0.3-0.5,平衡专业术语与语义理解
top_k: 参与向量检索的 chunk 数量,影响检索范围
rerank_id: 重排序模型 ID,提升检索精度
keyword: 开启关键词匹配,对专业领域极其有用
highlight: 高亮匹配内容,帮助理解匹配原因
2.4
聊天助手管理
创建聊天助手 RAGFlow.create_chat
RAGFlow.create_chat(name: str,avatar: str = "",dataset_ids: list[str] = [],llm: Chat.LLM = None,prompt: Chat.Prompt = None)
优化参数:
llm: LLM 模型配置
model_name: 模型名称
temperature: 温度,影响创造性
top_p: 词汇采样范围
presence_penalty: 重复惩罚
frequency_penalty: 频率惩罚
max_token: 最大输出 token 数
prompt: 提示词配置
similarity_threshold: 相似度阈值
keywords_similarity_weight: 关键词相似度权重
top_n: 提供给 LLM 的 chunk 数量
rerank_model: 重排序模型
top_k: 重排序参与的候选数量 empty_response: 无匹配时的回复
show_quote: 是否显示引用来源
prompt: 系统提示词内容
更新聊天助手 Chat.update
Chat.update(update_message : dict) 优化参数: 同 create_chat 中的参数
2.5
会话管理 (SESSION MANAGEMENT)
创建会话 Chat.create_session
Chat.create_session(name: str = "New session")提问 Session.ask
Session.ask(question: str = "", stream: bool = False, **kwargs)优化参数:
stream: 流式输出,提升用户体验
**kwargs: 可传递给 prompt 中定义的变量
2.6
代理管理 (AGENT MANAGEMENT)
创建代理会话 Agent.create_session
Agent.create_session(id, rag, **kwargs)代理提问 Session.ask
Session.ask(question: str = "", stream: bool = False)与普通会话的ask方法类似。
3
3.1
专业术语处理
需要在检索引擎层面添加工业领域同义词和术语映射:
# 需要修改源码的示例逻辑class CustomTerminologyProcessor:def __init__(self, terminology_mapping):self.terminology_mapping = terminology_mapping # 同义词映射表def process_query(self, query):# 专业术语标准化# 车间俚语转换为标准术语processed_query = queryfor slang, standard_term in self.terminology_mapping.items():processed_query = processed_query.replace(slang, standard_term)return processed_query
修改点:
在查询预处理阶段添加定制的术语处理模块
需要在 RAGFlow 的查询管道中修改源码添加此功能
3.2
多级索引结构实现
需要定制 Milvus 索引策略,实现基础索引层和语义索引层的混合索引:
# 这部分需要修改源码,以下是概念性代码class CustomHybridIndexBuilder:def __init__(self, vector_db_client):self.client = vector_db_clientdef create_scalar_indices(self, collection_name, fields):# 创建设备编号、故障代码等标量索引for field in fields:self.client.create_index(collection_name, field, "scalar")def create_vector_indices(self, collection_name, fields):# 创建向量索引for field in fields:self.client.create_index(collection_name, field, {"index_type": "HNSW", "params": {"M": 16, "efConstruction": 200}})
修改点:
修改 RAGFlow 的索引构建模块扩展
Milvus 客户端接口以支持多索引策略
3.3
查询路由设计
需要实现定制化的查询路由逻辑,识别不同类型的查询并路由到最合适的检索通道:
# 查询路由器 - 需要源码修改实现class QueryRouter:def route_query(self, query_text):if self._is_equipment_code(query_text):return "exact_match", {"field": "equipment_code"}elif self._is_fault_code(query_text):return "exact_match", {"field": "fault_code"}elif self._is_parameter_query(query_text):return "parameter_lookup", {"field": "parameter_name"}else:return "semantic_search", {"model": "embedding_model"}
修改点:
在 RAGFlow 的查询处理流程中添加查询分类和路由机制
实现针对不同查询类型的专用处理通道
3.4
上下文增强机制
增加查询上下文增强,融入设备信息、历史记录等:
# 上下文增强器 - 需要修改源码实现class ContextEnhancer:def enhance_query(self, query, session_history, equipment_metadata=None):# 添加设备上下文信息if equipment_metadata:query_context = f"设备型号: {equipment_metadata['model']}, 生产年份: {equipment_metadata['year']}\n"query_context += query# 添加历史查询信息if session_history:relevant_history = self._extract_relevant_history(session_history, query)query_context = f"参考历史信息: {relevant_history}\n" + query_contextreturn query_context
修改点:
修改会话管理模块,实现会话状态跟踪
增加设备元数据关联机制
在查询处理流程中加入上下文增强步骤
4
依然是两种方案,直接使用RAGFlow API方案优势是更简单,使用现有功能,无需额外的模型调用,也能够直接显示原始图片,视觉效果更好,处理速度更快,不依赖外部 API,当然成本也无疑更低。
但使用一个多模态模型进行预处理的方案优势也很明显,图片内容被转换为文本,便于向量化和语义搜索,也可以依托多模态模型的能力,提供更丰富的图片内容解释。
目前实际测试下来,采用两种方案的组合,效果更加稳定。
4.1
使用多模态预处理生成图片描述
# 使用多模态模型生成图片描述processor = MultimodalDocumentProcessor(api_key="YOUR_API_KEY")enhanced_docs = processor.process_pdf("设备手册.pdf")
4.2
使用 RAGFlow 处理和存储原始图片
# 配置保留图片的数据集dataset = rag_object.create_dataset(name="图文设备手册",chunk_method="paper",parser_config={"layout_recognize": True})# 上传原始PDF文档with open("设备手册.pdf", "rb") as f:dataset.upload_documents([{"display_name": "设备手册.pdf", "blob": f.read()}])
4.3
创建能够提供文本描述和图片引用的助手
assistant = rag_object.create_chat(name="图文设备专家",dataset_ids=[dataset.id],prompt=Chat.Prompt(prompt="""你是设备维修专家。回答时,请同时提供:1. 文字描述解释故障和解决方案2. 引用相关图片,包括图片描述3. 告诉用户可以参考哪些图片获取更多信息{knowledge}"""))
4.4
源码修改的一些建议
增强图片提取和处理:
修改 PDF 解析器,更准确地绑定文本和相关图片
增加图片内容分析功能,自动标注图片类型(如"故障图"、"结构图"等)
实现图文混合索引:
为图片创建特殊索引,支持通过图片内容或相关文本检索图片
在检索结果中包含图片 URL 或直接嵌入图片
改进响应生成:
修改聊天助手的响应生成逻辑,自动识别图片引用
在生成的回答中包含相关图片或图片链接
5
RAGFlow的chunk_method参数是在数据集级别或文档级别设置的,不支持在单个文档内部动态切换不同的分块策略。但实际情况是,同一文档中的不同部分可能需要不同的处理方式,比如针对段落、图片、表格、图表等,使用单一的分块策略很难同时兼顾所有这些内容类型的特点。
5.1
4种分块策略对比
源码修改方案:
修改 RAGFlow 的文档解析器,使其能够识别文档中的不同部分并应用不同的分块策略,但这需要深入修改 RAGFlow 的核心处理逻辑,如果没有深入理解RAGFlow的全局代码,建议不要这么做。
文档预处理方案:
在上传到 RAGFlow 前预处理文档,将其拆分成不同类型的子文档。例如,将设备手册拆分为纯文本部分、表格部分、图文部分等然后分别上传到不同的数据集,每个数据集使用适合的分块策略。
这个方案优点是,可以充分利用RAGFlow针对不同内容类型的专门分块策略,但问题也很明显,就是文档上下文被拆分,可能影响整体理解。
自定义分块方案:
不使用RAGFlow 的自动分块,而是手动控制分块,使用chunk_method="one"将整个文档作为一个块导入,然后使用自定义逻辑创建更细粒度的分块。这种做法无疑可以实现最精细的控制、保留文档完整性,当然缺点就是实现上会相对麻烦。
混合模型方案:
创建多个使用不同分块策略的数据集,将同一文档上传到所有这些数据集,在检索时查询所有数据集并合并结果。这种方法保持文档完整性,但创建多个使用不同分块策略的副本,会造成存储冗余,检索时需要合并多个结果集。
5.2
推荐自定义方案
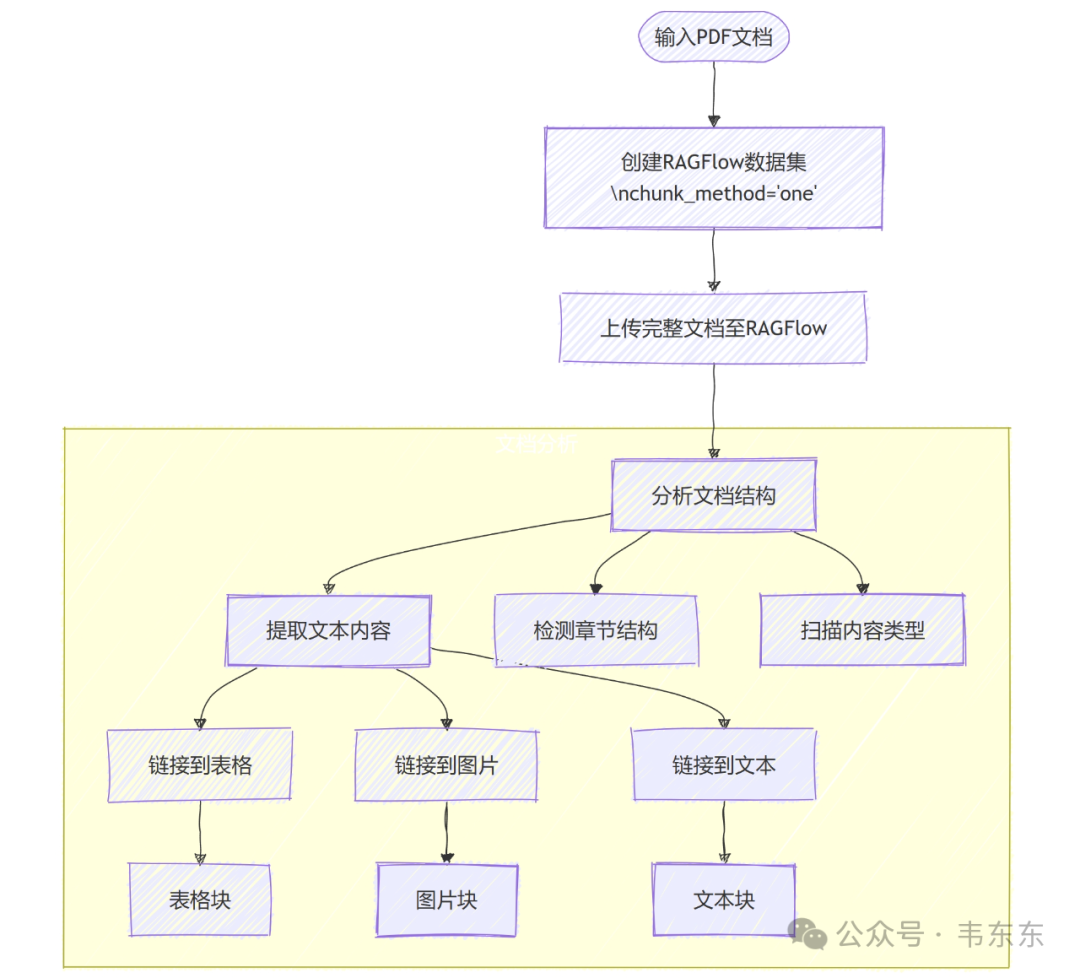
完整保留原始文档:
使用 chunk_method="one"将文档整体上传保留文档的完整性和上下文关系
自定义内容识别:
使用 PyMuPDF 识别文档中的不同内容类型:
文本、段落、表格内容图片及其相关描述、章节标题和结构
动态创建精细分块:
文本块: 基于段落和语义分界
表格块: 保留表格结构和行列关系
图文块: 关联图片和周围的描述文本
添加分块类型标记:
每个分块添加类型标识符[text], [table], [image]等
方便检索时区分不同类型的内容
丰富关键词提取:
为每个分块提取相关关键词
保留章节上下文信息
回顾23年和24年国内大部分中小企业对大模型应用落地的态度,大抵是23年在观望,24年上半年利润和数字化底座都不错企业开始内部小范围试错,发现效果不达预期后,要么放弃,要么就试图寻找一些外部解决方案。但对于大部分公司而言,大模型在企业应用落地受限于比较贵的部署成本和复杂的技术门槛迟迟没有提上日程,DeepSeek的1/20开源之后,正在改变这一局面,此刻我们或许也正处于一个关键的转折点之上。
RAG的落地优化需要群策群力先前试着建了微信群和小红书的群,活跃度比较差,本想搜个知识星球加入交流下,一时也没搜到,于是我就建了个,希望能吸引到一线的从业人员或者其他的积极行动者们充分交流。年费499,限时3天免费体验,有点小贵,新手慎入。
明天起正式发帖(卖个期货),内容方向如下:
已落地项目(目前有3个)中的技术方案及部分源码;
多个细分场景知识库应用的调研情况;
RAG相关系列论文和框架解读;
其他
from ragflow_sdk import RAGFlowimport fitz # PyMuPDFimport reimport pandas as pdimport ioimport loggingfrom typing import List, Dict, Any, Tuplelogging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')logger = logging.getLogger(__name__)class DynamicChunker:"""针对混合格式文档的自定义分块器"""def __init__(self, api_key: str, base_url: str):self.rag_object = RAGFlow(api_key=api_key, base_url=base_url)def process_document(self, pdf_path: str, dataset_name: str = None) -> str:"""处理PDF文档并实现自定义分块"""# 1. 创建或获取数据集if dataset_name:datasets = self.rag_object.list_datasets(name=dataset_name)if datasets:dataset = datasets[0]logger.info(f"使用现有数据集: {dataset.name}, ID: {dataset.id}")else:dataset = self.rag_object.create_dataset(name=dataset_name,embedding_model="BAAI/bge-large-zh-v1.5",language="Chinese",chunk_method="one" # 使用"one"方式,保持文档完整性)logger.info(f"创建新数据集: {dataset.name}, ID: {dataset.id}")else:dataset = self.rag_object.create_dataset(name="混合文档库",embedding_model="BAAI/bge-large-zh-v1.5",language="Chinese",chunk_method="one")logger.info(f"创建新数据集: {dataset.name}, ID: {dataset.id}")# 2. 上传文档with open(pdf_path, "rb") as f:document_blob = f.read()docs = dataset.upload_documents([{"display_name": pdf_path.split("/")[-1],"blob": document_blob}])if not docs:logger.error("文档上传失败")return Nonedoc = docs[0]logger.info(f"文档上传成功, ID: {doc.id}")# 3. 分析文档结构并创建自定义分块chunks = self._create_custom_chunks(pdf_path)logger.info(f"创建了 {len(chunks)} 个自定义分块")# 4. 手动添加分块到文档chunk_ids = []for chunk in chunks:content = chunk["content"]keywords = chunk["keywords"]chunk_type = chunk["type"]# 添加分块类型标记以便未来检索content_with_marker = f"[{chunk_type}]\n{content}"# 添加分块new_chunk = doc.add_chunk(content=content_with_marker,important_keywords=keywords)chunk_ids.append(new_chunk.id)logger.info(f"添加分块: 类型={chunk_type}, ID={new_chunk.id}, 关键词数量={len(keywords)}")return doc.iddef _create_custom_chunks(self, pdf_path: str) -> List[Dict[str, Any]]:"""分析PDF并创建自定义分块"""pdf_doc = fitz.open(pdf_path)chunks = []# 用于存储当前上下文current_section = ""current_text_chunk = ""current_table_data = []current_keywords = []for page_idx, page in enumerate(pdf_doc):# 提取页面文本text = page.get_text()# 检测章节标题section_headers = self._detect_section_headers(text)if section_headers:# 如果有积累的文本块,先保存if current_text_chunk:chunks.append({"content": current_text_chunk,"keywords": list(set(current_keywords)),"type": "text","section": current_section})current_text_chunk = ""current_keywords = []# 更新当前章节current_section = section_headers[0]current_keywords.append(current_section)# 检测表格tables = self._detect_tables(page)if tables:# 如果有积累的文本块,先保存if current_text_chunk:chunks.append({"content": current_text_chunk,"keywords": list(set(current_keywords)),"type": "text","section": current_section})current_text_chunk = ""current_keywords = []# 处理表格for table in tables:table_content = self._format_table(table)table_keywords = self._extract_keywords_from_table(table)chunks.append({"content": table_content,"keywords": list(set(table_keywords + current_keywords)),"type": "table","section": current_section})# 检测图片images = self._detect_images(page)for img_idx, img in enumerate(images):# 提取图片周围的文本作为上下文img_context = self._extract_image_context(text, img["bbox"])# 如果找到图片相关文本if img_context:# 如果有积累的文本块,先保存if current_text_chunk:chunks.append({"content": current_text_chunk,"keywords": list(set(current_keywords)),"type": "text","section": current_section})current_text_chunk = ""current_keywords = []# 创建图文块image_text_content = f"图片描述: {img_context}\n图片位置: 第{page_idx+1}页"image_keywords = self._extract_keywords(img_context)chunks.append({"content": image_text_content,"keywords": list(set(image_keywords + current_keywords)),"type": "image","section": current_section})# 防止重复处理同一段文本text = text.replace(img_context, "", 1)# 处理剩余文本if text.strip():# 按段落拆分paragraphs = self._split_into_paragraphs(text)for para in paragraphs:if len(para.strip()) < 10: # 忽略太短的段落continue# 累积文本直到达到合适的大小current_text_chunk += para + "\n\n"current_keywords.extend(self._extract_keywords(para))# 检查是否应该创建新的文本块if len(current_text_chunk) > 1500: # 大约300-500个词chunks.append({"content": current_text_chunk,"keywords": list(set(current_keywords)),"type": "text","section": current_section})current_text_chunk = ""current_keywords = []# 处理最后一个文本块if current_text_chunk:chunks.append({"content": current_text_chunk,"keywords": list(set(current_keywords)),"type": "text","section": current_section})return chunksdef _detect_section_headers(self, text: str) -> List[str]:"""检测章节标题"""# 这是一个简化的实现,可以根据实际文档格式调整header_patterns = [r"^第[一二三四五六七八九十\d]+章\s*(.+)$",r"^\d+\.\d*\s+(.+)$",r"^[一二三四五六七八九十]+[、..]\s*(.+)$"]headers = []for line in text.split("\n"):line = line.strip()for pattern in header_patterns:match = re.match(pattern, line)if match:headers.append(line)breakreturn headersdef _detect_tables(self, page) -> List[Any]:"""检测页面中的表格"""# 这里使用简化的检测逻辑,实际应用中可能需要更复杂的表格检测算法# 例如,可以寻找包含多个垂直和水平线的区域tables = []# 简单表格检测:查找水平线和垂直线的集中区域# 这里仅作为占位示例,实际实现会更复杂horizontal_lines = []vertical_lines = []for drawing in page.get_drawings():for item in drawing["items"]:if item["type"] == "l": # 线段x0, y0, x1, y1 = item["rect"]if abs(y1 - y0) < 2: # 水平线horizontal_lines.append((x0, y0, x1, y1))elif abs(x1 - x0) < 2: # 垂直线vertical_lines.append((x0, y0, x1, y1))# 简单的表格判定:有足够多的水平线和垂直线if len(horizontal_lines) >= 3 and len(vertical_lines) >= 2:# 找出所有线的边界,作为表格边界min_x = min([min(l[0], l[2]) for l in horizontal_lines + vertical_lines])max_x = max([max(l[0], l[2]) for l in horizontal_lines + vertical_lines])min_y = min([min(l[1], l[3]) for l in horizontal_lines + vertical_lines])max_y = max([max(l[1], l[3]) for l in horizontal_lines + vertical_lines])# 提取表格区域的文本table_rect = fitz.Rect(min_x, min_y, max_x, max_y)table_text = page.get_text("text", clip=table_rect)# 简化的表格结构化(实际应用中需要更复杂的逻辑)table_rows = table_text.split("\n")table = []for row in table_rows:if row.strip():cells = row.split()if len(cells) >= 2: # 至少有2个单元格才视为有效行table.append(cells)if table:tables.append(table)return tablesdef _detect_images(self, page) -> List[Dict[str, Any]]:"""检测页面中的图片"""images = []# 获取页面上的图片对象img_list = page.get_images(full=True)for img_idx, img_info in enumerate(img_list):xref = img_info[0]base_image = page.parent.extract_image(xref)if base_image:# 寻找图片在页面上的位置img_rects = []for rect in page.get_image_rects(xref):img_rects.append(rect)if img_rects:# 使用第一个找到的位置bbox = img_rects[0]images.append({"bbox": [bbox.x0, bbox.y0, bbox.x1, bbox.y1]})return imagesdef _extract_image_context(self, text: str, bbox: List[float], context_size: int = 200) -> str:"""提取图片周围的文本作为上下文"""# 在文本中查找可能的图片标题,如"图1","Figure 1"等caption_patterns = [r"图\s*\d+[\..:]?\s*(.+?)(?:\n|$)",r"Figure\s*\d+[\.:]?\s*(.+?)(?:\n|$)",r"图表\s*\d+[\..:]?\s*(.+?)(?:\n|$)"]for pattern in caption_patterns:matches = re.finditer(pattern, text, re.IGNORECASE)for match in matches:return match.group(0)# 如果找不到明确的图片标题,则尝试提取图片周围的文本# 这是一个简化实现,实际应用中可能需要更复杂的逻辑lines = text.split("\n")total_length = 0start_line = 0# 估计图片在文本中的位置# 这是一个非常粗略的估计,实际应用中需要更精确的方法relative_position = bbox[1] / 1000 # 假设页面高度为1000target_position = int(len(text) * relative_position)# 找到大致对应的行for i, line in enumerate(lines):total_length += len(line) + 1 # +1 for newlineif total_length > target_position:start_line = max(0, i - 2) # 从前两行开始break# 提取上下文(当前行及其前后几行)context_lines = lines[max(0, start_line):min(len(lines), start_line + 5)]return "\n".join(line for line in context_lines if len(line.strip()) > 5)def _format_table(self, table: List[List[str]]) -> str:"""格式化表格为文本格式"""if not table:return ""# 创建pandas DataFramedf = pd.DataFrame(table[1:], columns=table[0] if len(table) > 1 else None)# 转换为字符串形式result = io.StringIO()df.to_csv(result, sep="|", index=False)return result.getvalue()def _extract_keywords_from_table(self, table: List[List[str]]) -> List[str]:"""从表格中提取关键词"""keywords = []# 表头作为关键词if table and len(table) > 0:keywords.extend(table[0])# 第一列可能是行标题,也加入关键词for row in table[1:] if len(table) > 1 else []:if row and len(row) > 0:keywords.append(row[0])return keywordsdef _split_into_paragraphs(self, text: str) -> List[str]:"""将文本拆分为段落"""# 按照多个换行符拆分paragraphs = re.split(r"\n\s*\n", text)return [p.strip() for p in paragraphs if p.strip()]def _extract_keywords(self, text: str) -> List[str]:"""从文本中提取关键词"""# 这是一个简化的关键词提取方法# 实际应用中可以使用更复杂的NLP技术,如TF-IDF、TextRank等# 1. 移除停用词和标点stop_words = {"的", "了", "和", "与", "或", "在", "是", "有", "被", "将", "把"}cleaned_text = re.sub(r'[^\w\s]', ' ', text)words = cleaned_text.split()filtered_words = [w for w in words if w not in stop_words and len(w) > 1]# 2. 简单词频统计word_count = {}for word in filtered_words:if word in word_count:word_count[word] += 1else:word_count[word] = 1# 3. 选择频率最高的几个词作为关键词sorted_words = sorted(word_count.items(), key=lambda x: x[1], reverse=True)return [word for word, count in sorted_words[:10] if count > 1]# 使用示例if __name__ == "__main__":chunker = DynamicChunker(api_key="YOUR_API_KEY",base_url="http://YOUR_BASE_URL:9380")doc_id = chunker.process_document("设备维修手册.pdf", "动态分块测试")print(f"处理完成,文档ID: {doc_id}")
(完)