作者:微信小助手
发布时间:2025-02-17T18:02:44
群友一直希望我做一个dify的教程,我把去年的dify铲了,重新安装了一遍。 同时基于以前的文章提问,以及群友的问题,我先做一个知识科普,不感兴趣的可以绕过这块。 国产AI之光!DeepSeek本地部署教程,效果媲美GPT-4 deepseek一键生成小红书爆款内容,排版下载全自动!睡后收入不是梦 大语言模型(LLM)是通过深度学习技术,基于海量历史文本数据训练出的概率生成系统。 更新机制 综上,我们能做的更新机制就是给它通过提示词上下文临时注入知识。 我们之前说的知识库都是广义知识库。 在 嵌入模型是一种将高维离散数据(文本、图像等)转换为低维连续向量的技术,这种转换让机器能更好地理解和处理复杂数据。 举一个例子来理解向量,你正在玩一个叫做"猜词"的游戏。你的目标是描述一个词,而你的朋友们要根据你的描述猜出这个词。你不能直接说出这个词,而是要用其他相关的词来描述它。例如,你可以用"热"、"喝"、"早餐"来描述"咖啡"。嵌入模型就是将一个词转化为其他相关词的专用模型。 "热"、"喝"、"早餐" 可以理解为向量。不过向量值是在向量空间的特定位置,在这个空间里语义相近的词会自动聚集起来。所以就有了相似度的概念,相似度越高,越匹配。 我们使用的bge-m3 只能向量化出1024维。 2,将文档分割成适当大小的文本块 3,使用embedding模型将每个文本段转换为向量 4,将向量和原文存储到向量数据库中 查询处理阶段 1,将用户输入问题转换为向量 2, 在向量库中检索相似内容 3, 将检索到的相关内容作为上下文提供给LLM 我们用的本地应用工具,一般都是粗粒度分段,向量化的质量没法保证。 根据上一步,我们可以知道本地知识库+本地大模型是安全的。 本地知识库+远端api的大模型,会把片段上传。 假设你已经安装了docker,docker安装不同的架构安装方式不一样,这里就不做教程了。 已经登录了docker 安装完docker以后,记得调整docker镜像的存储地址。 通过官网下载,如果你没有魔法,可以从网盘里那对应的 如果没有git环境,可以直接从网盘下载压缩包。 我们下载以后,只关注docker文件夹和README_CN.md即可。 由于我的dify安装的比较早,是0.7.x版本,为了给大家演示,就把原来的铲了。如果你以前安装过dify,使用以下命令清理历史镜像 我们进入dify目录下的docker目录中,比如我的 E:\ai\code\dify\docker 修改dify绑定ip API 服务绑定地址,默认:0.0.0.0,即所有地址均可访问。 刚开始我以为是控制dify对外暴露的服务的,改成了127.0.0.1,然后出现以下的502,折腾了我快3个小时。 修改端口(非必须) 默认占用的是80和443端口,如果你本机已经部署了其他的应用,占了该端口,修改.env文件中的下面两个变量 上传文件大小 默认上传图片大小是10MB,上传视频大小是100MB,文件默认是50MB,如果有需要修改下面对应的参数 启动以后在docker Desktop中查看, http://127.0.0.1:8001/install 填写相关信息,设置管理员账户。 添加对话模型 关于ip 添加向量模型 系统模型设置 2,选择已经配置的模型,当然建立知识库的时候,也可以切换 3,选择向量模型 4,保存 腾讯模型配置(免费到2月25日) 2,模型名称选择deepseek-r1 3,api key 填写自己的即可 4,填写地址:https://api.lkeap.cloud.tencent.com/v1 硅基流动添加 模型供应商 配置好以后,我们可以在模型列表那里看到所有的模型 dify的分段有个好处,设置分段以后,可以实时预览,可以根据预览效果,自己实时调整分段策略。 关键点: 1,默认 2,最大分段长度为4000tokens,默认为500tokens 3,分段重叠长度,默认为50tokens,用于分段时,段与段之间存在一定的重叠部分。建议设置为分段长度 Tokens 数的 10-25%; 4,文本预处理规则:用于移除冗余符号、URL等噪声 5,这里还有一个点,向量模型会自动按段落或语义进行切分,也就是大家分段以后内容缺失的根因。 父子模式采用双层分段结构来平衡检索的精确度和上下文信息,让精准匹配与全面的上下文信息二者兼得。 关键点 1,父区块(Parent-chunk)保持较大的文本单位(如段落),上下文内容丰富且连贯。默认以 2,子区块(Child-chunk)以较小的文本单位(如句子),用于精确检索。默认以 3,也可以选择噪音清理 4,在搜索时通过子区块精确检索后,获取父区块来补充上下文信息,从而给LLM的上下文内容更丰富 以句子为最小单位,向量化以后向量匹配的准确度会极大的提升。 官方示意图如下: 索引模式有两种。分别是高质量索引和经济索引 适用场景:需要高精度语义检索(如复杂问答、多语言支持)。 我们看下官方推荐的配置 3,选择向量模型 4,选择系统推荐的混合检索 5,选择Rerank模型,并选择对应的rerank模型 适用场景:预算有限或内容简单(如关键词匹配为主的FAQ)。 点击工作室,我们可以看到有很多丰富的应用,包括聊天助手、agent、工作流等 我们选择最简单的应用,聊天助手,点击5,创建空白应用 2,选择相关的模型 3,设置召回数量(文本片段数量) 4,相似度匹配,设置0.7 2,点击发送 3,调试成功以后可以点击发布 后续我会分享dify相关的高级功能。 同时也会基于dify做整合企业知识的相关功能开发。 相关资源网盘地址: https://pan.quark.cn/s/7909300e0028 创作不易,辛苦大家动动发财的小手。知识科普
关于模型
能力边界
关于知识库
维度
广义知识库
模型知识库
数据来源
更新方式
知识范围
关于模型哪里我们说了,我们可以通过提示词临时注入知识,给大模型,但是大模型的上下文是有长度限制的,我们通过各种技术把最合适的内容挑选出来,然后给大模型。关于嵌入模型
ollama show bge-m3:latest
architecture bert
parameters 566.70M
context length 8192
embedding length 1024
quantization F16为什么没有匹配到知识
 知识预处理
知识预处理
1, 上传文档本地知识库安全吗?
dify安装
前提条件
安装
下载dify
# 进入要下载的目录,打卡命令提示行工具,cmd或者powershell
cd E:\ai\code
#下载
git clone https://github.com/langgenius/dify.git
# 国内镜像站
https://gitee.com/dify_ai/dify
清理(非必须)
cd docker 进入目录
# 清理历史镜像
docker-compose down -v --rmi all创建配置
# 以示例创建一个.env的文件,执行下面命令
cp .\.env.example .env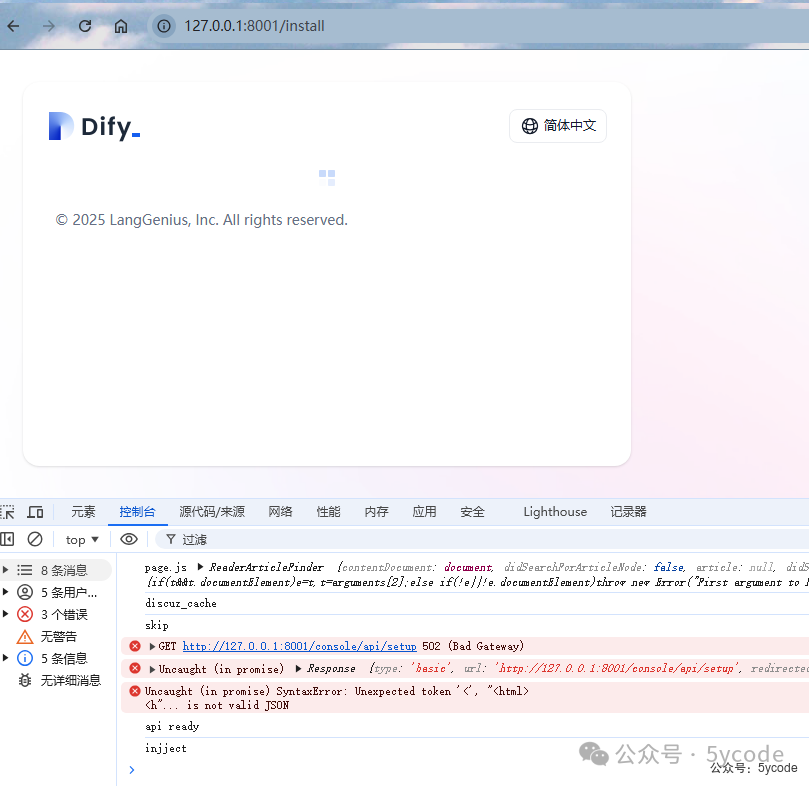
EXPOSE_NGINX_PORT=8001
EXPOSE_NGINX_SSL_PORT=8443# Upload image file size limit, default 10M.
UPLOAD_IMAGE_FILE_SIZE_LIMIT=10
# Upload video file size limit, default 100M.
UPLOAD_VIDEO_FILE_SIZE_LIMIT=100
# Upload audio file size limit, default 50M.
UPLOAD_AUDIO_FILE_SIZE_LIMIT=50启动dify
docker compose up -d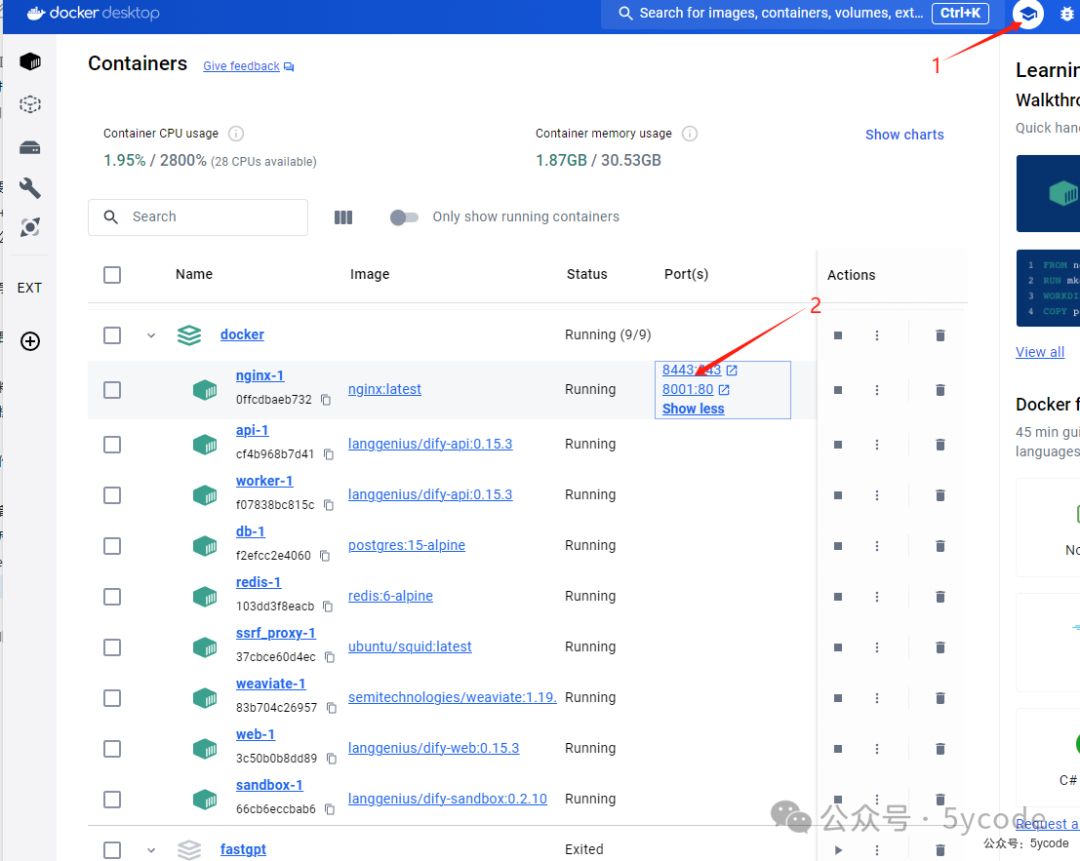

设置管理员与登录
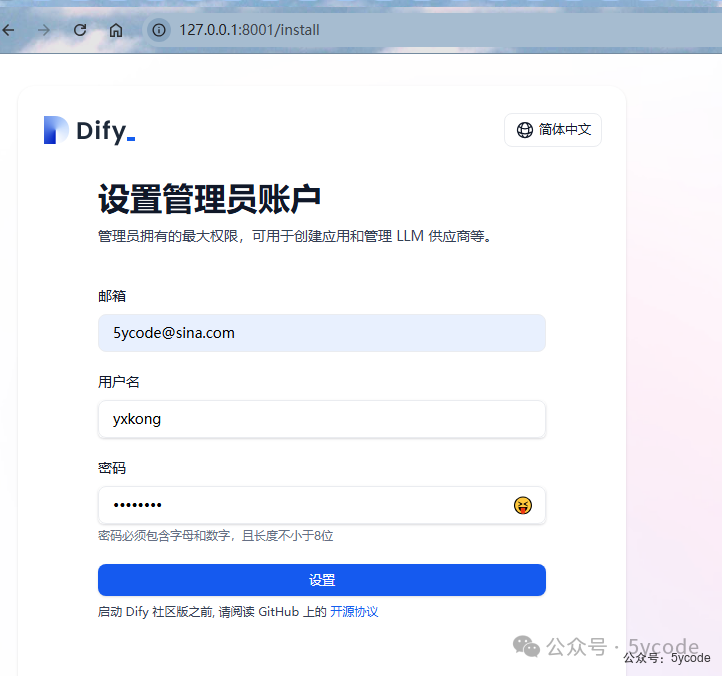 设置成功以后,登录
设置成功以后,登录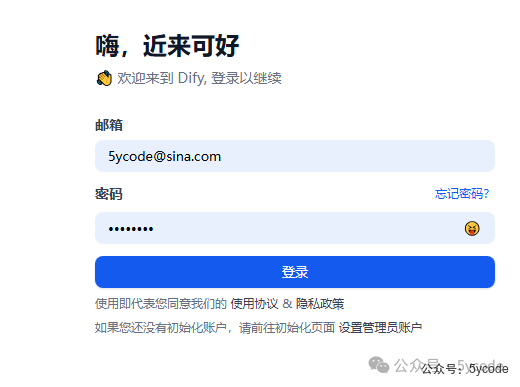
设置模型
 1,点击右上角的账户 2,点击设置
1,点击右上角的账户 2,点击设置本地模型设置
 1, 点击模型供应商 2,下拉找到ollama 3,点击添加模型
1, 点击模型供应商 2,下拉找到ollama 3,点击添加模型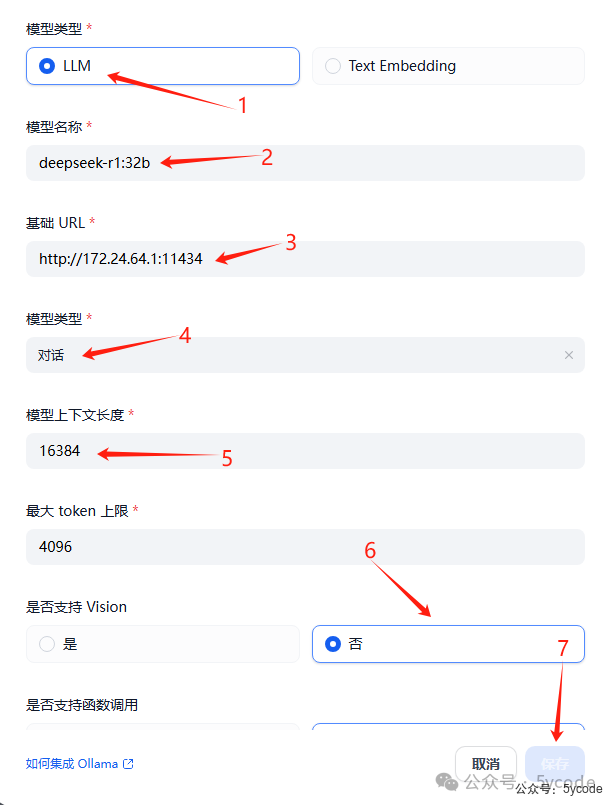 按照步骤添加模型即可,注意模型上下文长度,可以通过
按照步骤添加模型即可,注意模型上下文长度,可以通过ollama show 模型名称查看,如果你经常用大文本,就直接调到最大值。需要注意的是dify,上传文件是有大小限制的。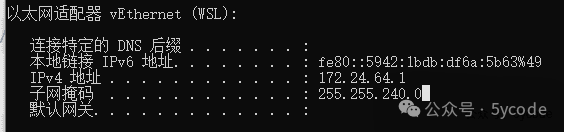 我使用的是本地docker虚拟网络,如果你ollama设置了
我使用的是本地docker虚拟网络,如果你ollama设置了OLLAMA_HOST为0.0.0.0 需要注意网络安全,防止外网有人能访问。我是将我的ollama绑定到了局域网ip上了。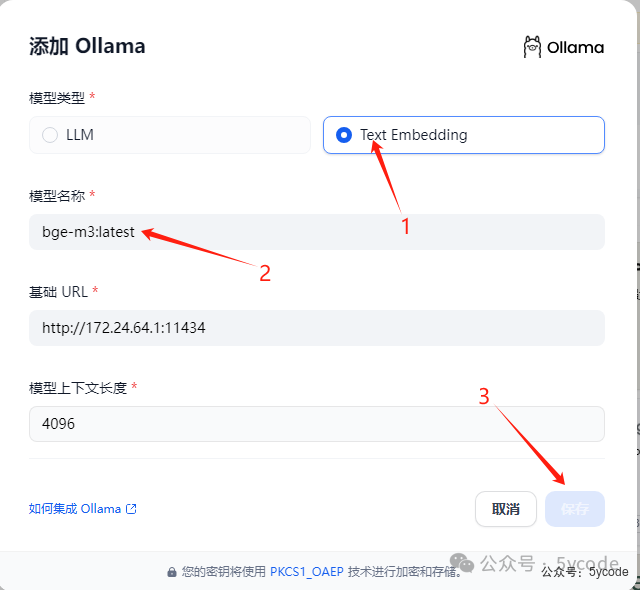 1,注意选择text embedding
1,注意选择text embedding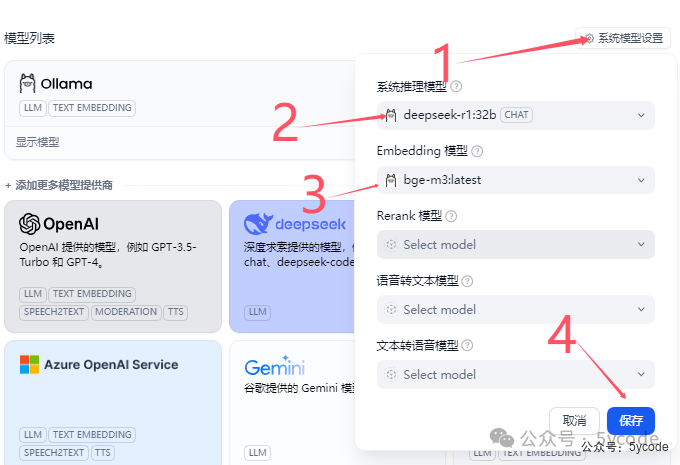 1,点击系统模型设置
1,点击系统模型设置在线api模型配置
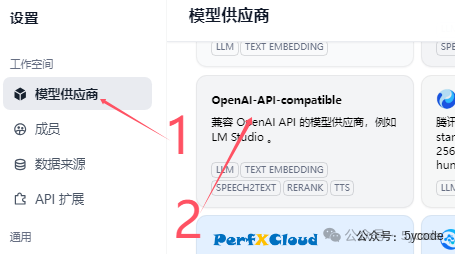 没找到对应的模型供应商,直接选择openai兼容的模型供应商。
没找到对应的模型供应商,直接选择openai兼容的模型供应商。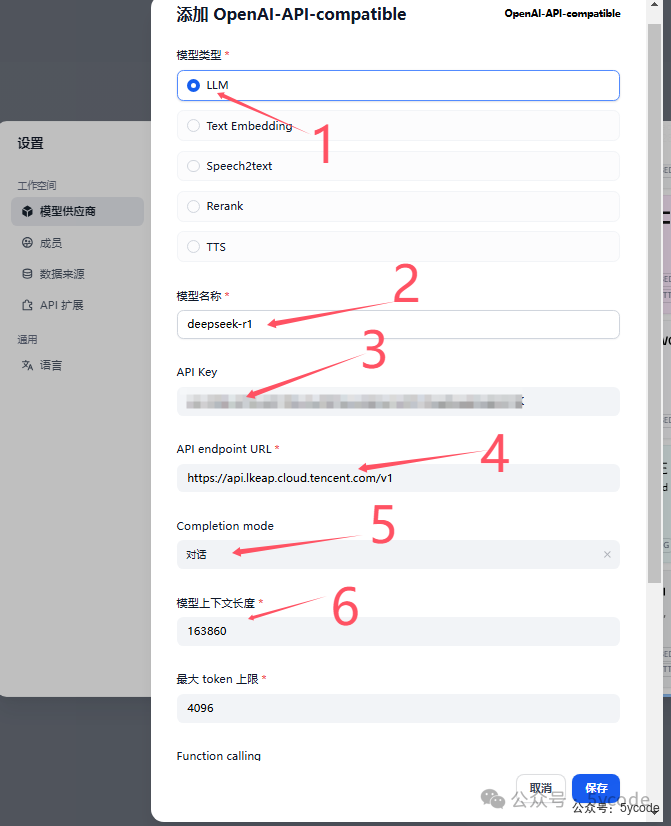 按步骤填写即可。
按步骤填写即可。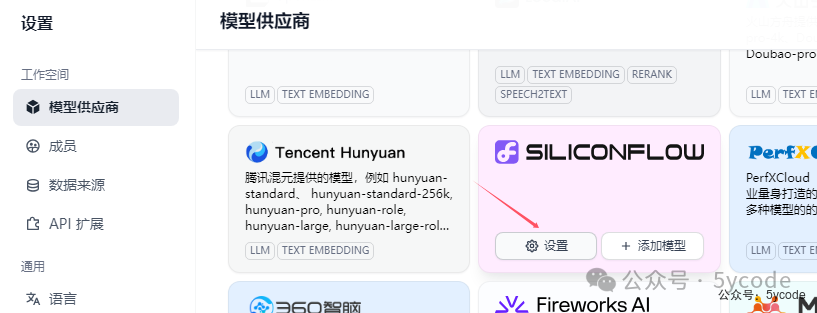 找到模型供应商,点击设置,配置下密钥就可以了。
找到模型供应商,点击设置,配置下密钥就可以了。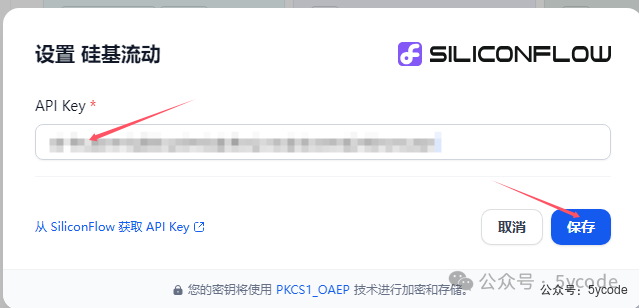
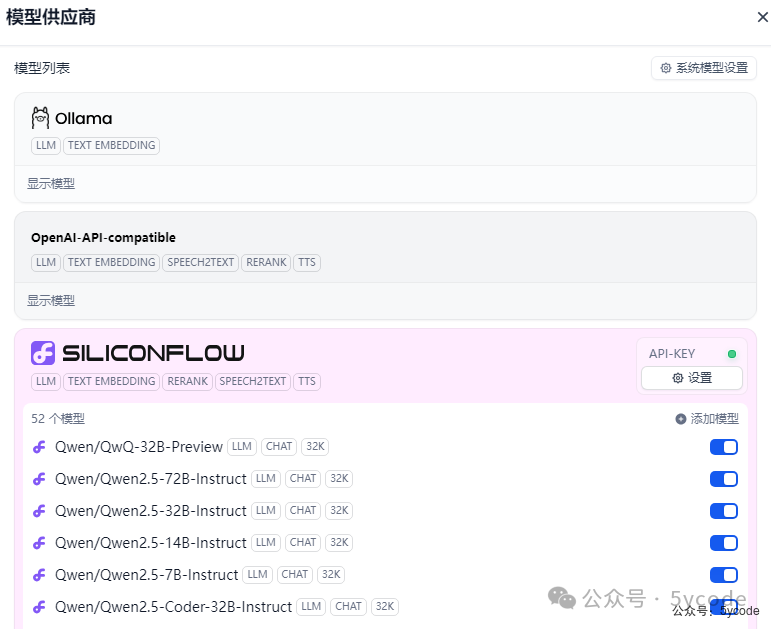
最终系统模型设置
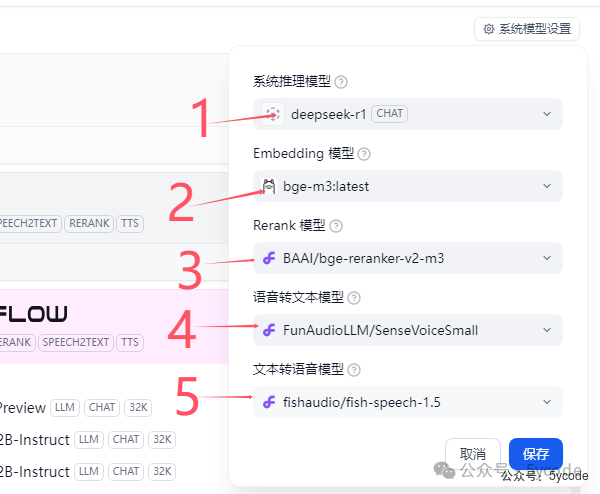
知识库设置
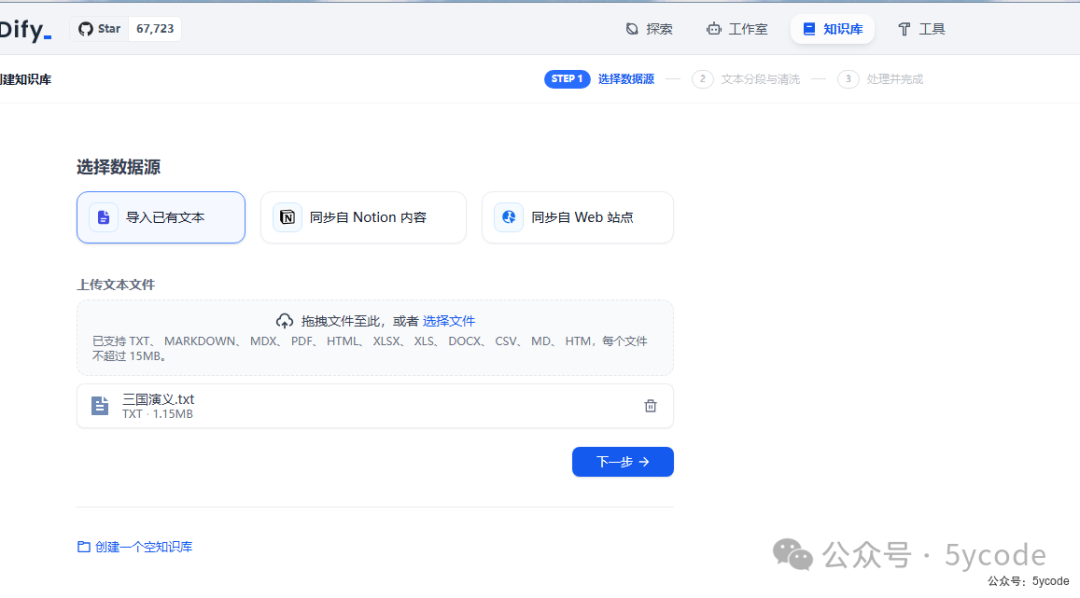
创建知识库
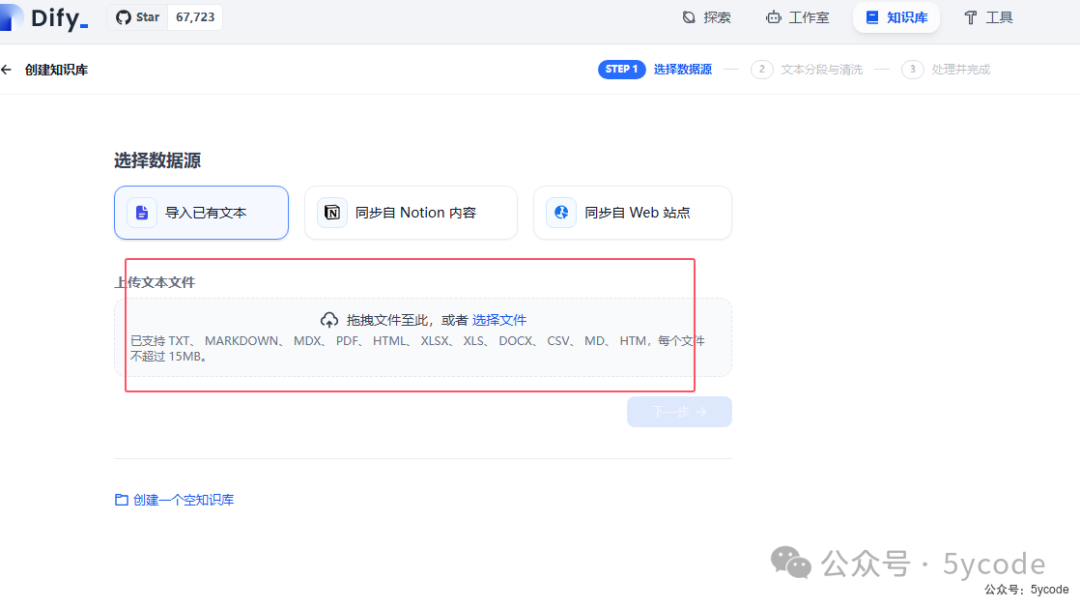
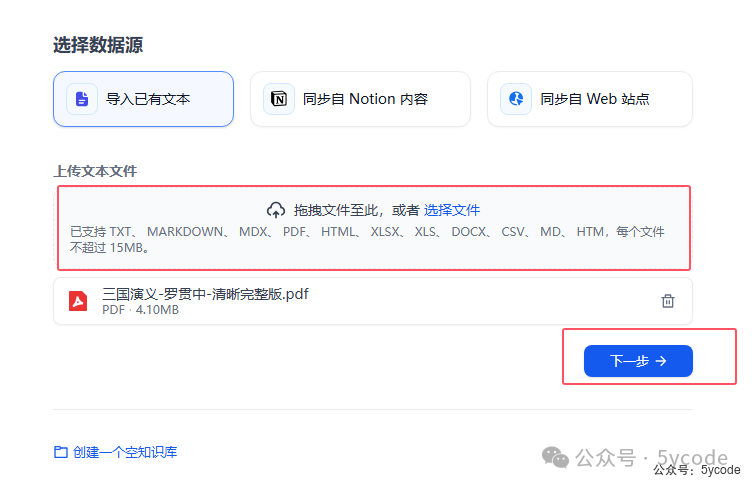
分段
dify建议首次创建知识库使用父子分段模式。通用分段(原自动分段与清洗)
\n作为分段标识适用于内容简单、结构清晰的文档(如FAQ列表)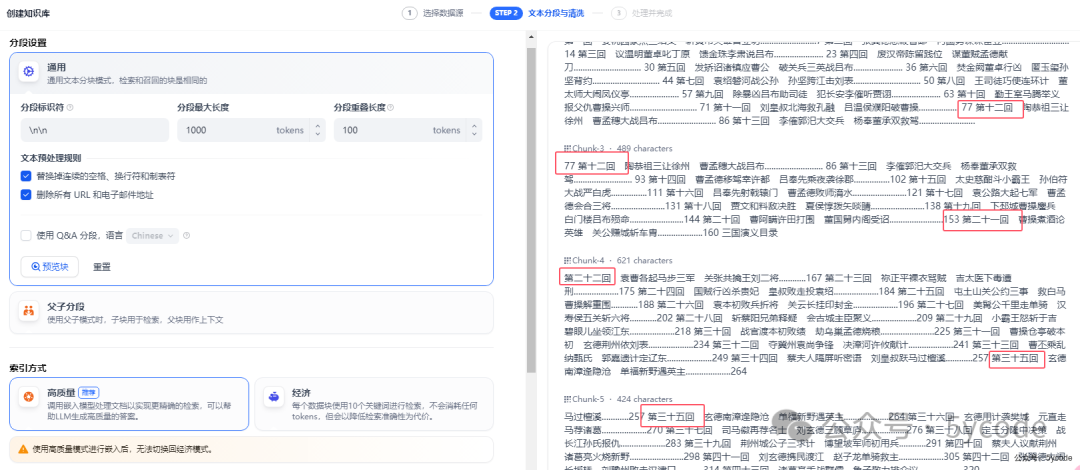
父子分段
\n\n为分段标识,如果知识不长,可以以整个作为父区块(超过1万个分段就直接被截断了)。\n为分段标识。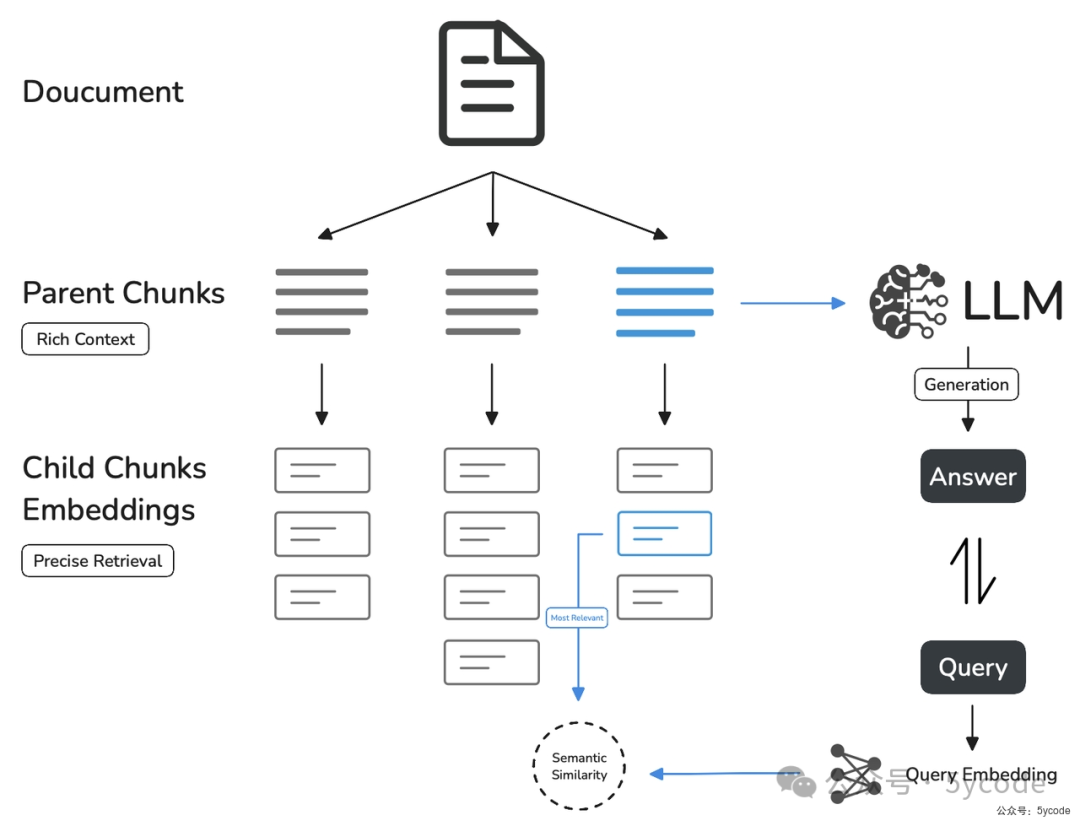
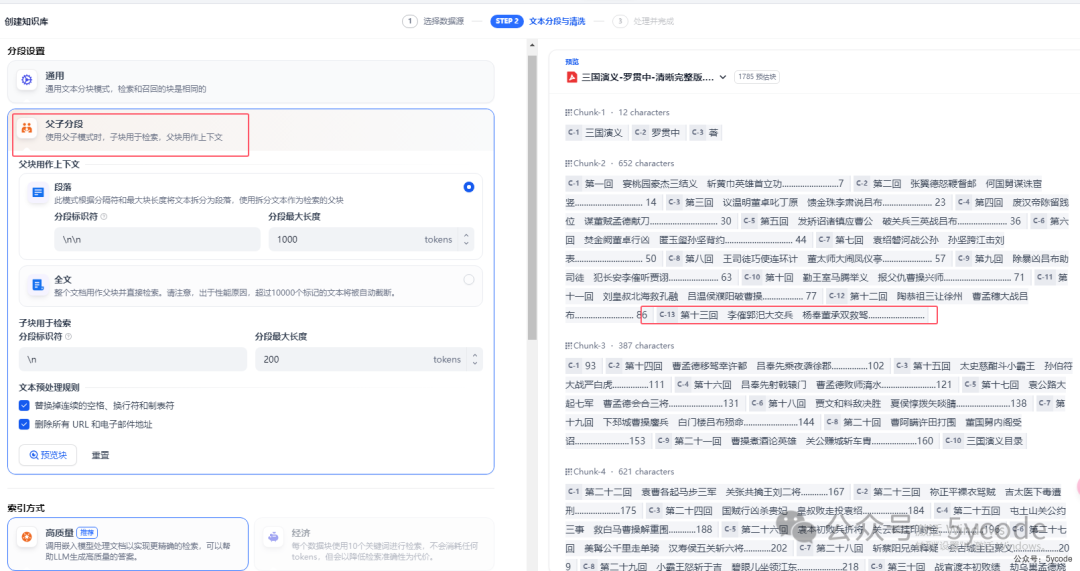 1,我们可以不断的调整参数,预览下,看下实际效果,
1,我们可以不断的调整参数,预览下,看下实际效果,索引模式
高质量索引
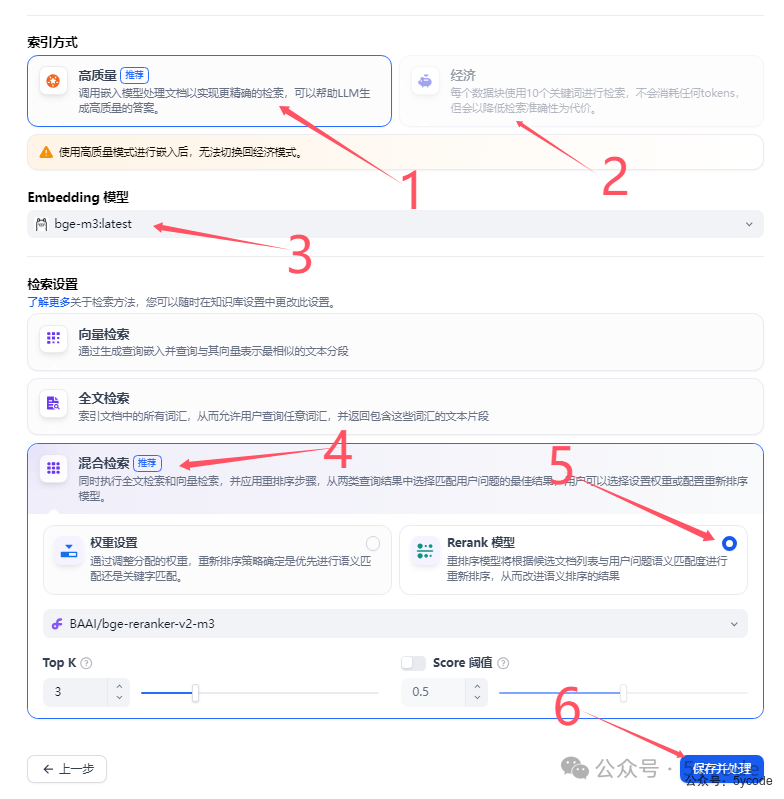 1,选择高质量
1,选择高质量经济索引
TopK(返回相似片段数量)和 Score 阈值(相似度过滤)平衡召回率与准确率。
使用
创建应用
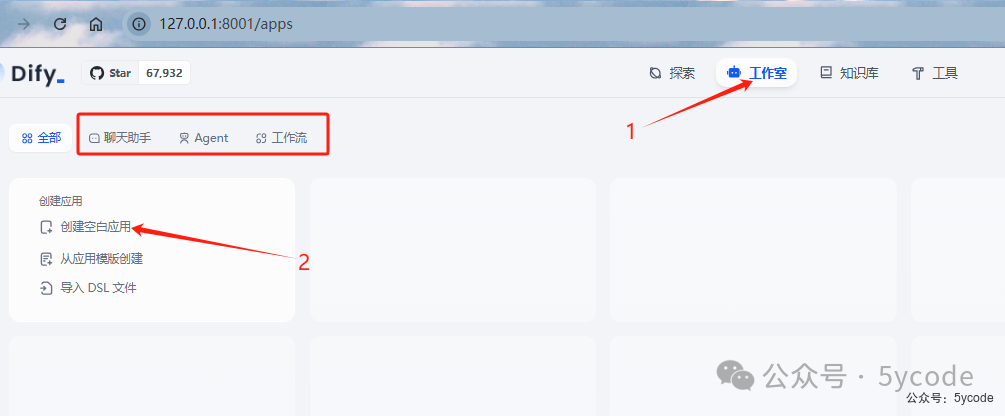
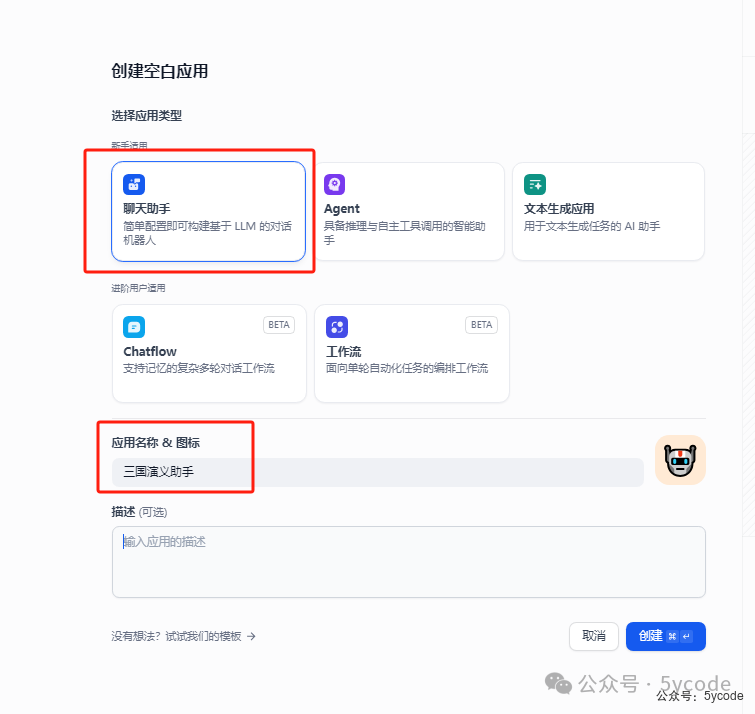
添加知识库
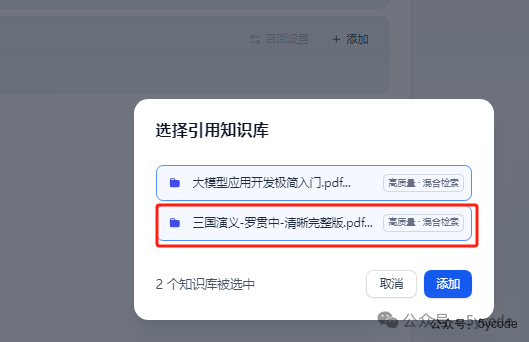 知识库可以一次选多个,我们只选择三国演义。
知识库可以一次选多个,我们只选择三国演义。召回设置
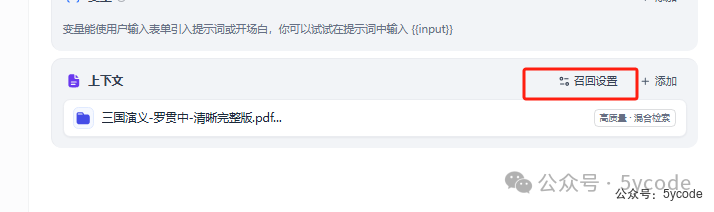
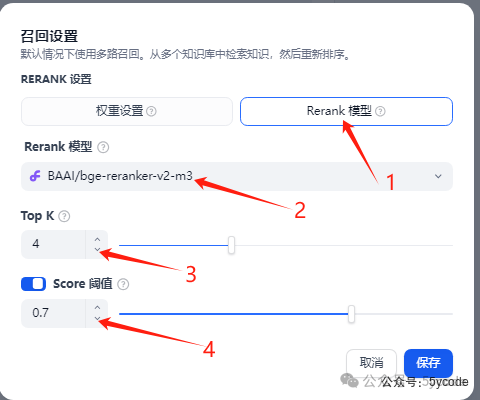 1,选择Rerank模型
1,选择Rerank模型调试与预览
 1,输入聊天内容
1,输入聊天内容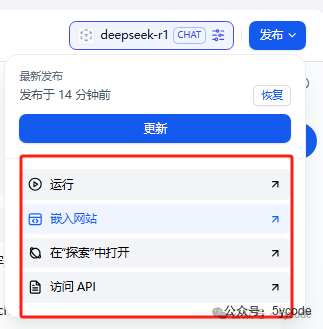 发布以后有多种适用方式。
发布以后有多种适用方式。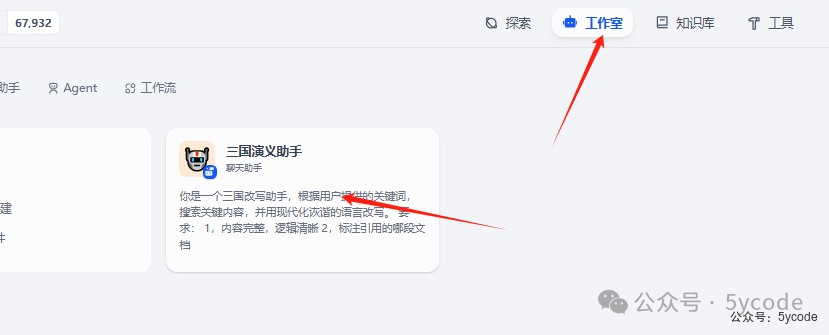 返回工作室以后,我们可以发现已经有对应的应用了。
返回工作室以后,我们可以发现已经有对应的应用了。后记
if 文章有用:
点赞() # 👍 小手一抖,bug没有
收藏() # 📂 防止迷路,代码永驻
关注() # 🔔 追更最新内容
else:
留言吐槽() # 💬 评论区等你来战