作者:微信小助手
发布时间:2025-01-02T20:50:32
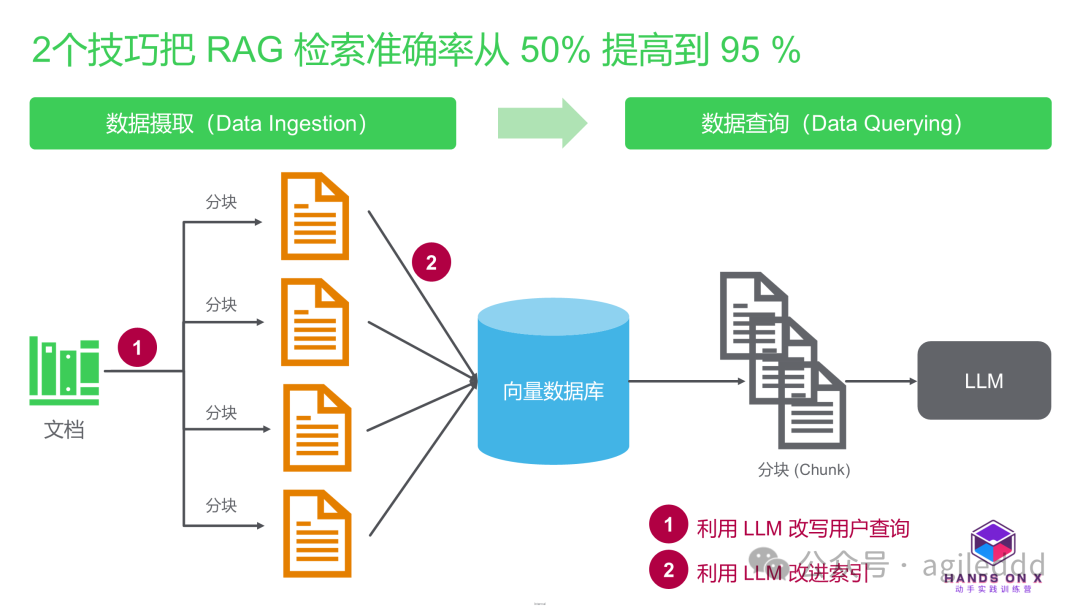
在讨论了 RAG 的 chunking、embedding、评估指标、评估流程等技术后,我们进一步探讨 RAG 系统的实际应用。在实际项目中,RAG(Retrieval-Augmented Generation)系统的检索阶段往往是影响生成效果的核心环节。RAG 系统的工作流程包括数据摄取(Data Ingestion)和数据查询(Data Querying),其中检索是至关重要的一步。本文介绍了在一个案例中,团队如何通过2个关键技巧把 RAG 检索准确率从 50% 提高到 95 % RAG 检索准确率(Recall)是衡量检索系统能否找到与用户查询相关的所有文档的指标。它在 RAG 系统中尤为重要,因为如果检索阶段无法提供足够的上下文,即使生成模型再强大,也难以输出高质量结果。高检索准确率是确保生成内容相关性的基础。 检索准确率(Recall)公式如下: 示例: 在这个案例中,我们通过两个关键改进,使系统的检索准确率从 50-60% 提升至 95% 以上。此项目的背景是为客户服务团队构建一个内部聊天机器人,以帮助客服人员更快地访问信息。 项目初始阶段包括: 数据包括有关地点(如水疗中心和健身房)和专家(如按摩治疗师和私人教练)的信息。数据通过将文本字段(描述、城市、地区)合并为一个内容字段,并为向量搜索创建 embeddings 来准备。 最初的搜索查询要么作为向量搜索,要么作为全文 BM25 搜索对内容字段运行。然而,系统仅在 50-60% 的时间内检索到正确的文档。 向量搜索不适合这个应用,因为它优先考虑模糊匹配和语义相似性,而我们的应用需要精确匹配。BM25 搜索也不够,因为它基于术语频率,导致包含更多匹配查询术语的文档优先显示,而不是匹配相关术语的文档。BM25 还存在芬兰语词形变化的问题,稍微的词形变化会阻止文档检索。 系统采用了向量搜索 和BM25 全文搜索 的组合,然而: 这些问题导致检索结果相关性不足,严重影响了用户体验。 通过以下两项关键改进,系统的检索准确率得以显著提升: 本案例的关键收获如下: 高效的检索不仅为生成阶段提供了坚实基础,也证明了技术优化应聚焦于用户需求,避免盲目追求复杂性。
1. 什么是 RAG 检索准确率?为什么它很重要?

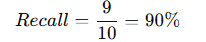
2. 案例背景
3. 初始方案的问题
4. 检索准确率从 50-60% 提升至 95% 的两个技巧
1.利用 LLM 改写用户查询
2.利用 LLM 改进索引
6. 总结