作者:微信小助手
发布时间:2024-12-08T20:37:17


01
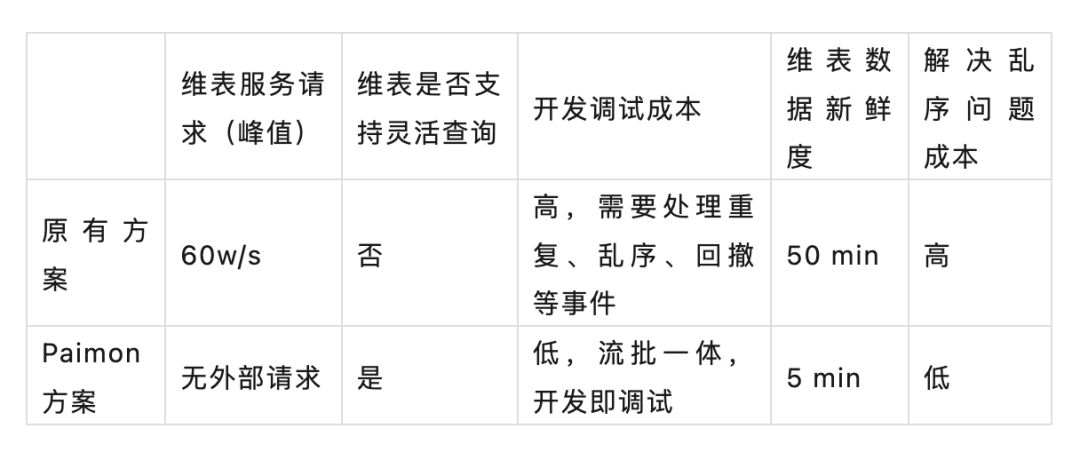
场景一:游戏视频指标上卷
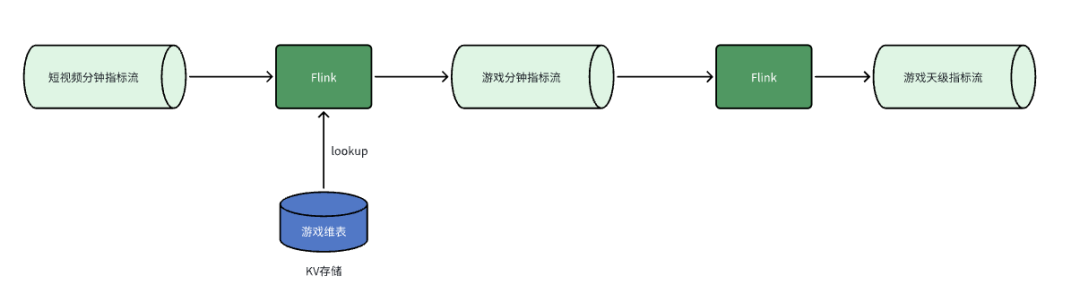


CREATE VIEW view_01 ASSELECT id,f1,f2,MAX(f3) AS f3,f4,f5,MAX(f6) AS f6,MAX(f7) AS f7,LAST_VALUE(f8, f5) AS f8FROM source_tableGROUP BYid,f1,f2,f4,f5;INSERT INTO sink_tableSELECT id,f1,SUM(f3) AS f3,CAST(f2 AS BIGINT) AS f2,MAX(f4) AS f4,MAX(f5) AS f5,MAX(f6) AS f6,MAX(f7) AS f7,LAST_VALUE(f8, f5) AS f8FROM view_01GROUP BYid,f1,f2;
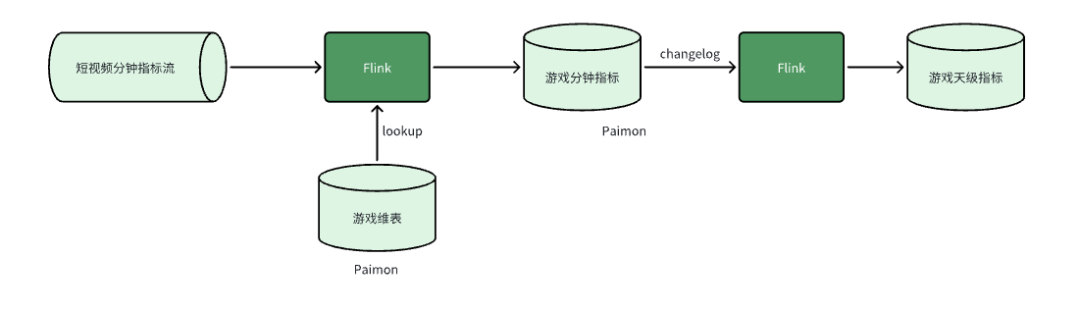
--维表模型DDLcreate table dim_table01 (`id` BIGINT,`f1` STRING,`f2` BIGINTPRIMART KEY (f1) NOT ENFORCED) WITH ('changelog-producer'='lookup','changelog-producer.row-deduplicate'='true','sequence.field'='f2',...)create table dim_table02 (`id` BIGINT,`f1` STRING,`f2` BIGINTPRIMART KEY (f1) NOT ENFORCED) WITH('changelog-producer'='lookup','changelog-producer.row-deduplicate'='true','sequence.field'='f2',...)--分钟指标流关联维度SELECTAA.id,BB.f1 as bb_f1,CC.f1 as cc_f1FROM source_table AALEFT JOINpaimon.db_name.dim_table01 /*+ OPTIONS('lookup.async'='true', 'lookup.async-thread-number'='8') */FOR SYSTEM_TIME AS OF proctime AS BBON AA.id = BB.idLEFT JOINpaimon.db_name.dim_table02 /*+ OPTIONS('lookup.async'='true', 'lookup.async-thread-number'='8') */FOR SYSTEM_TIME AS OF proctime AS CCON AA.id = CC.id;
--分钟指标模型DDLcreate table `db_name`.`table_name` (`id` BIGINT,`f1` STRING,`f2` BIGINT,`f3` BIGINT,`f4` BIGINT,`f5` STRING,`f6` BIGINT,`f7` STRING,`f8` map<STRING, STRING>PRIMARY KEY (id, f1, f2, f4, f5, date, hour) NOT ENFORCED) PARTITIONED by (`date` STRING comment '日期',`hour` STRING comment '小时') WITH ('changelog-producer'='lookup','partition.expiration-time'='30 d','partition.timestamp-pattern'='$date','partition.expiration-check-interval'='3h','sequence.field'='f8,f3',...);--分钟指标上卷INSERT INTO sink_tableSELECT id,f1,SUM(f3) AS f3,f2,MAX(f4) AS f4,MAX(f5) AS f5,MAX(f6) AS f6,MAX(f7) AS f7,LAST_VALUE(f8, f7) AS f8FROM paimon.db_name.table_nameGROUP BYid,f1,f2;
02
场景二:财经多流拼接
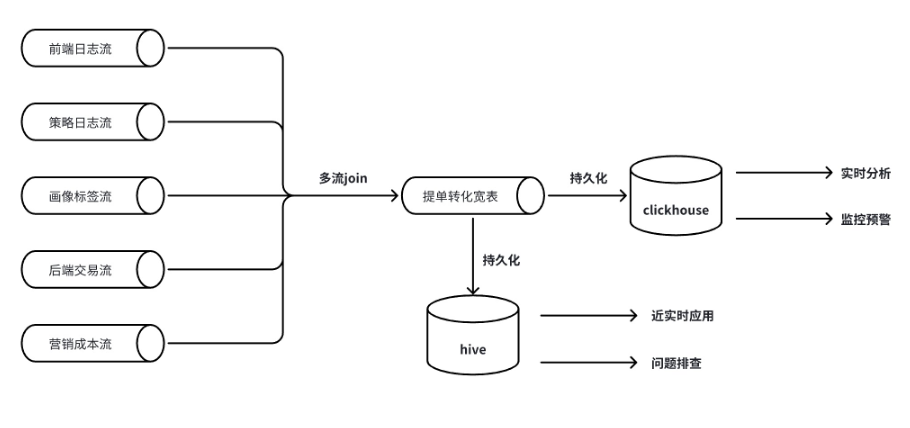
insert into sinkselect id,last_value(f1) as f1,last_value(f2) as f2,last_value(f3) as f3,last_value(f4) as f4,...from (select id,f1,f2,cast(null as STRING) as f3,cast(null as STRING) as f4,...from table1union allselect id,cast(null as STRING) as f1,cast(null as STRING) as f2,f3,f4,...from table2union all......)group by id;
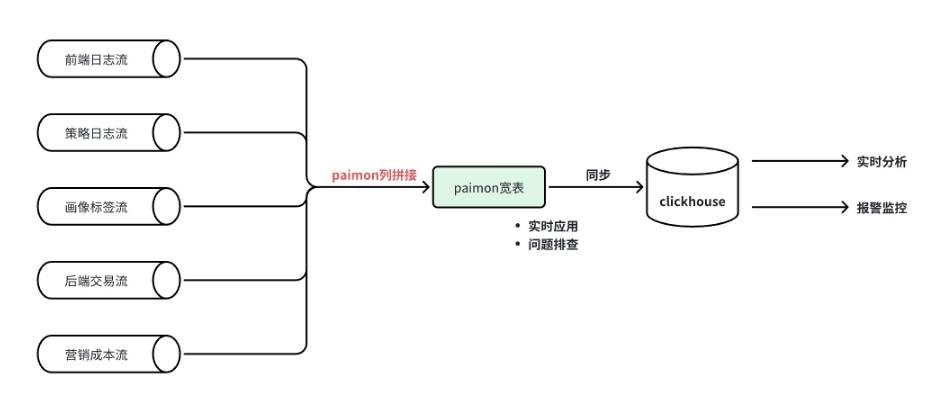
CREATE TABLE t (trace_id BIGINT,f1 STRING,f2 STRING,g_1 BIGINT,f3 STRING,f4 STRING,g_2 BIGINT,PRIMARY KEY (trace_id) NOT ENFORCED) WITH ('merge-engine'='partial-update','fields.g_1.sequence-group'='f1,f2', -- f1,f2字段根据 g_1 排序'fields.g_2.sequence-group'='f3,f4' -- f3,f4字段根据 g_2 排序);insert into tselect trace_id,f1,f2,g_1,f3,f4,g_2,...from (select trace_id,f1,f2,g_1,cast(null as STRING) as f3,cast(null as STRING) as f4,cast(null as BIGINT) as g_2,xxxfrom table1union allselect trace_id,cast(null as STRING) as f1,cast(null as STRING) as f2,cast(null as BIGINT) as g_1,f3,f4,g_2,xxxfrom table2union all......)
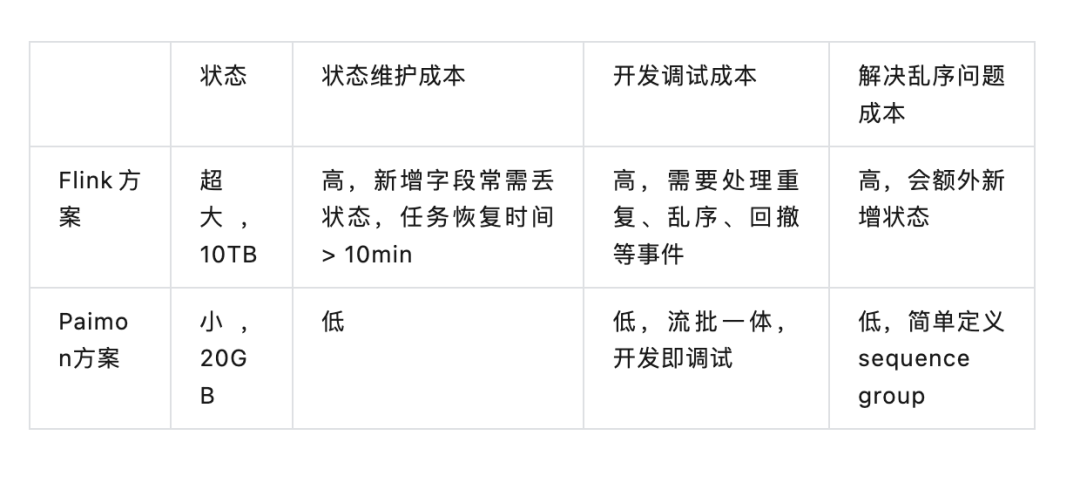
03
未来展望