本文目录
- 尼恩说在前面
- 1 回表查询(table lookup)是什么?
- 1.1 MySQL大概的架构
- 1.2 回表(table lookup) 的简单介绍
- 1.3 由浅入深,一步一步理解回表查询(table lookup)
- 基本概念:聚集索引(Clustered Index):
- 基本概念:非聚集索引(Non-Clustered Index):
- 使用案例介绍:回表查询
- 1.4 回表查询带来的 巨大的问题
- 1.5 怎样避免回表查询?
- 2 索引下推的底层原理是什么?优势是什么?
- 2.1 通俗易懂,介绍一下 索引下推的简单案例
- 最左匹配原则 中的第4条:范围匹配规则
- 2.2 没有索引下推场景下 的联合索引范围查询 执行流程
- 2.3 图解一下:什么是索引下推?
- 索引下推优化的原理
- 2.4 索引下推 场景下的联合索引范围查询 执行流程
- 2.5 通过 explain 演示一下 索引下推工作原理
- 案例分析
- 2.6 索引下推配置
- 2.7 通过 explain 演示一下:未启用索引下推 的效果
- 2.8 通过 explain 演示一下:启用索引下推 的效果
- 2.9 索引下推使用条件和效果
- 索引下推优化效果
- 索引下推应用范围
- 索引下推适用场景
- 3 来一张Explain执行计划详解图:
- 4 mysql调优的相关系统参数
-其返回值为如下的形式:
- 4.1 表访问优化参数
- 4.2 表关联优化参数
- 4.3 子查询优化参数
- 4.4 其他优化参数
- 说在最后:有问题找老架构取经
1 什么是 回表(table lookup)?
再由浅入深,一步一步理解回表查询(table lookup)
然后介绍,回表(table lookup)查询带来的 巨大的问题
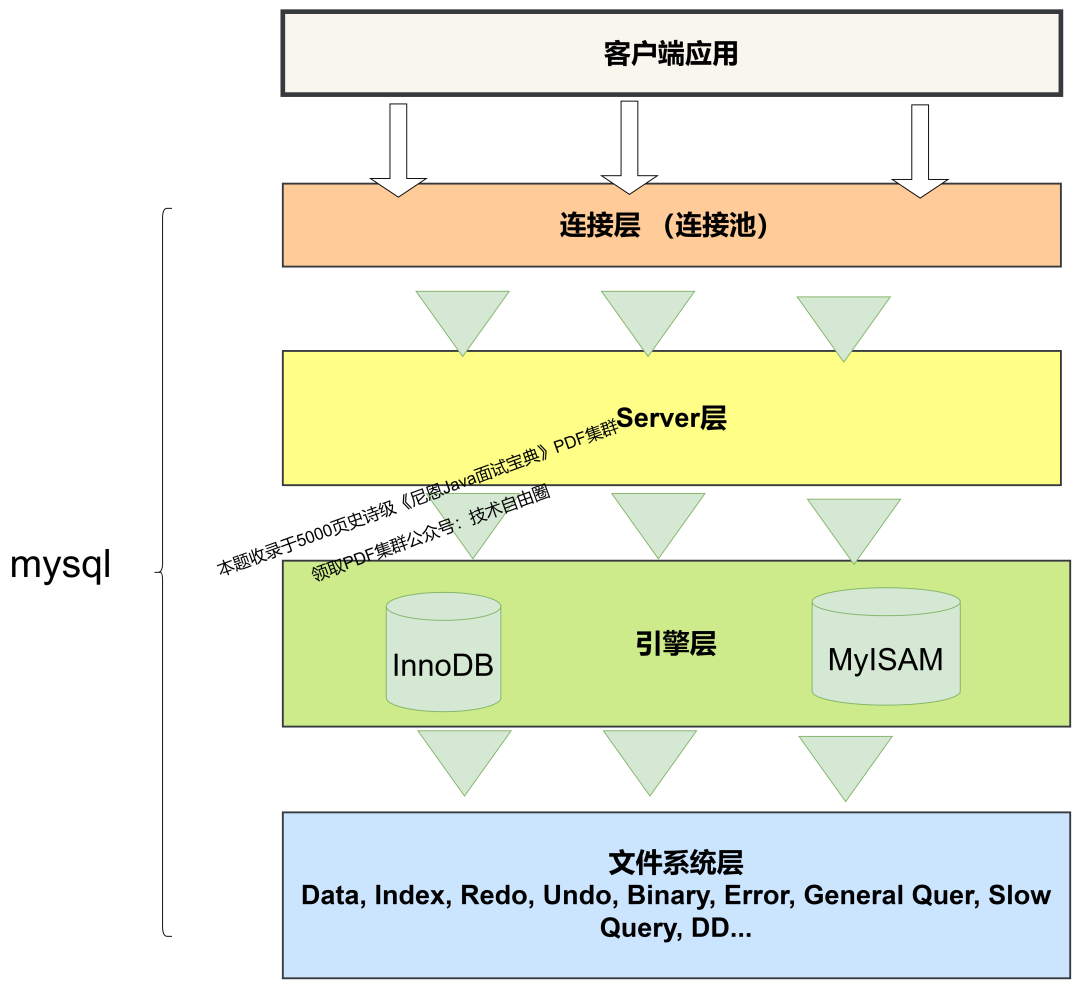
1.1 MySQL大概的架构
对来自客户端的连接进行权限验证并将相关的连接信息维护到连接池中,以便于下次连接。
提供NoSQL,SQL的API,SQL解析,SQL语句优化,SQL语句缓存等相关组件。
提供了一系列可插拔的存储引擎,我们可以通过存储引擎来进行数据的写入与读取,
通过存储引擎,我们可以真正的与硬盘中的数据和日志进行交互,
该层包含了具体的日志文件和数据文件以及MySQL相关的程序。
1.2 回表(table lookup) 的简单介绍
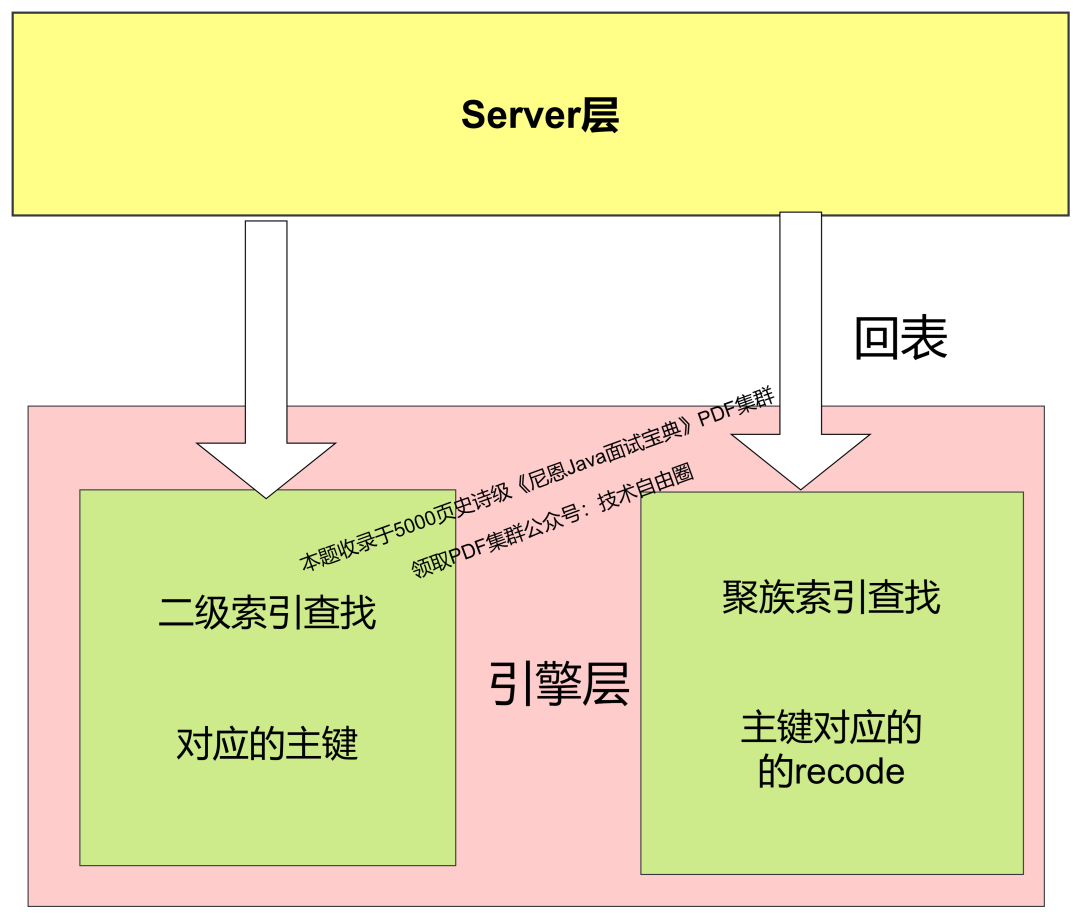
回表(table lookup)通常是指数据库查询过程中,需要从索引层查找到某条记录的主键,再通过这个主键回到数据表中获取完整的记录。
回表操作在数据库系统中的不同层次上实现,而这主要取决于数据库的架构设计。
-
查询优化器会决定是否需要进行回表操作。通过二级索引 查找到记录的主键后,查询层会发出回表的请求。
-
Engine 存储层:回表的实际数据读取是在存储层完成的。
一旦查询层决定需要回表,存储层负责根据主键从存储介质(例如硬盘或内存)中提取相应的完整记录。
存储层负责处理物理数据读取、缓存管理、磁盘 I/O 等操作。
总结来说,回表的决策是在 Server 层(查询层)做出的,而实际的记录读取则是在 存储层 完成的。
1.3 由浅入深,一步一步理解回表查询(table lookup)
在理解回表查询之前,我们需要先了解两个重要的概念:聚集索引和非聚集索引。
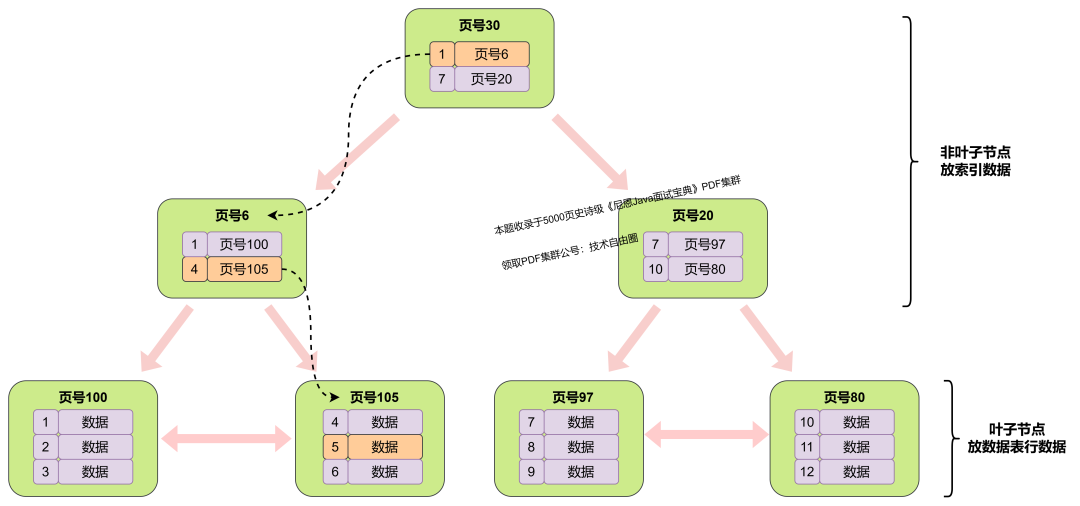
基本概念:聚集索引(Clustered Index):
-
存储方式:聚集索引决定了数据表中数据行的物理存储顺序。索引的顺序与数据行的顺序一致,实际上是直接嵌入到数据表中的一种排序结构。
-
影响查询:由于数据行的存储顺序与聚集索引的顺序一致,当通过聚集索引进行查询时,数据库引擎可以更快地定位到所需的数据,因为它知道数据的物理存储位置。适用于范围查询和排序操作。
-
唯一性:一个表只能有一个聚集索引,通常是主键,因为主键的值是唯一的。
-
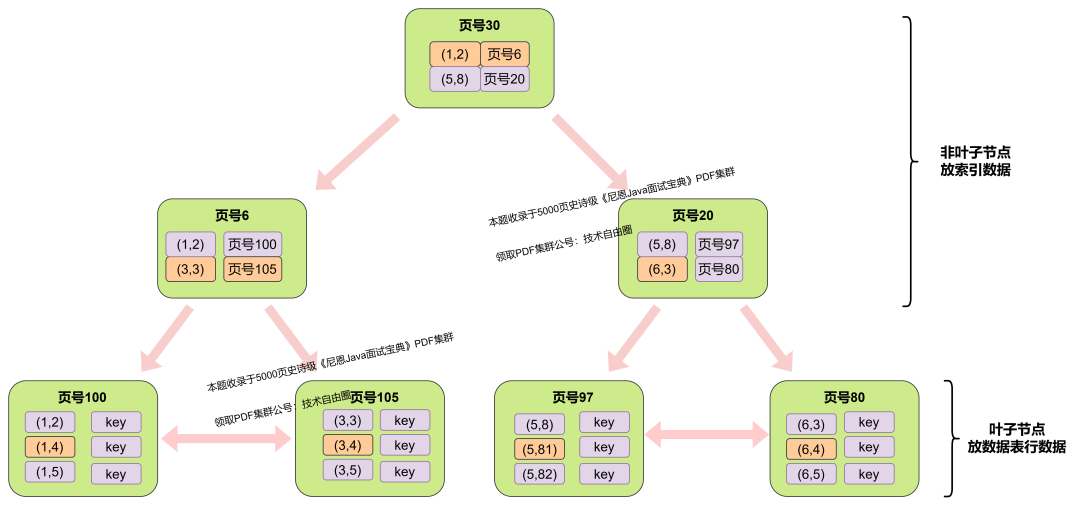
基本概念:非聚集索引(Non-Clustered Index):
-
存储方式:非聚集索引维护了索引键值和指向实际数据行的指针之间的映射关系。
索引键值与数据行的物理存储顺序无关,数据行的实际内容可能分散存储在磁盘上。
-
影响查询:通过非聚集索引进行查询时,数据库引擎首先根据索引键值找到对应的 指针或引用,然后再根据指针或引用去检索相应的数据行。适用于频繁的搜索和查询,但可能需要额外的IO操作。
-
唯一性:一个表可以有多个非聚集索引,不要求索引键值是唯一的。
-
存储数据:当前字段的值和指向数据行的指针或引用(通俗的说就是当前字段的主键值 Primary Key)
使用案例介绍:回表查询
回表查询是数据库中常见的一个概念,指的是server层无法直接从索引中获取所需数据,而需要回到原始数据表中进行额外的查找操作。
为了更好地理解回表查询,让我们通过SQL语句的方式来演示一下。
假设我们有一个包含员工信息的表 employees,其中包括:
这边把 employee_id 作为ID 主键,也就是 聚集索引,以加快根据员工编号进行查询的速度。
现在,假设我们需要查询员工编号为 1001 的员工的薪水,我们可能会编写如下的SQL查询语句:
SELECT salary FROM employees WHERE employee_id = 100;
在这个查询中,server层 通过 Engine 利用 employee_id 上的聚集索引,快速地找到对应的员工corde记录,并返回薪水信息,这时候,就不会发生回表查询。
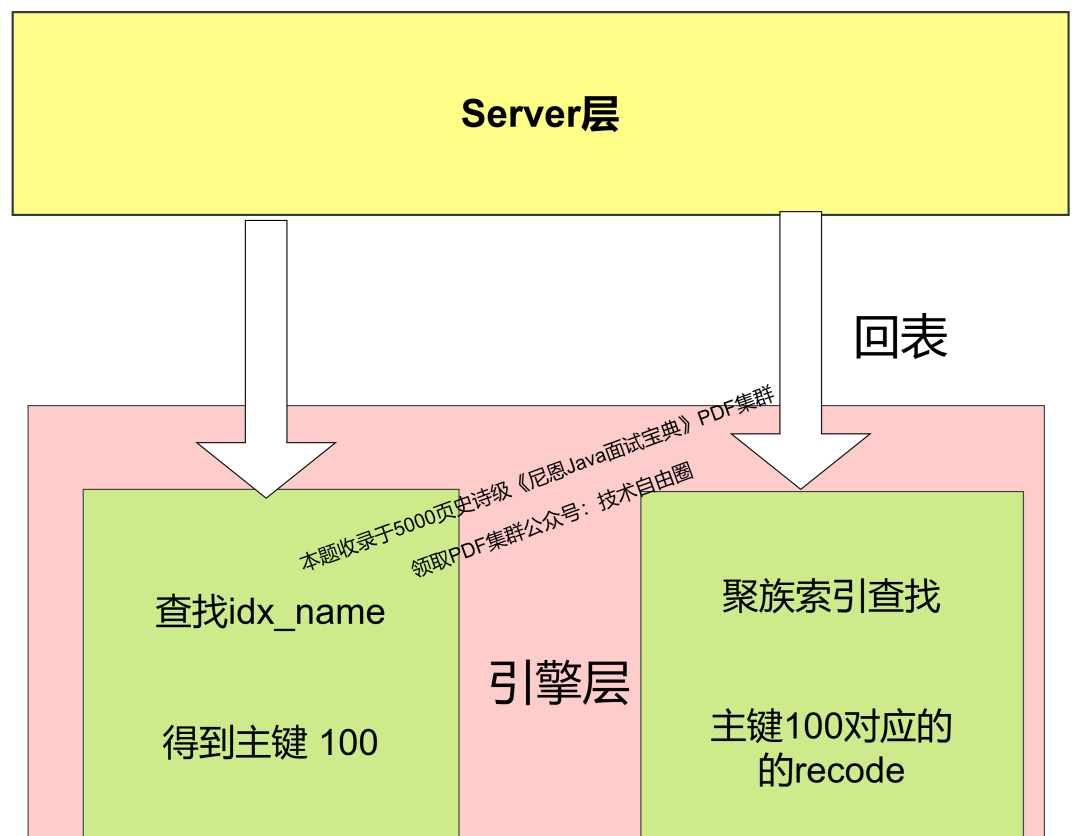
如果我们需要在name列查询员工姓名为 令狐冲 的薪水,并且假设 name 存在一个idx_name 的非聚集索引 :
SELECT salary FROM employees WHERE name= '令狐冲';
那么数据库server层 通过 Engine 利用 idx_name 非聚集索引,查到 令狐冲的id 为100。server层 再通过 Engine 利用 employee_id 上的聚集索引,快速地找到100 对应的员工recode记录,这就导致了回表查询。
1.4 回表查询带来的 巨大的问题
回表查询通常出现在使用非聚簇索引或二级索引的场景中,它带来的一些问题主要集中在性能和效率上。