1.背景和历史
Apache NiFi
(Niagara Files) 是由美国国家安全局(NSA)开发,并于2014年捐赠给Apache软件基金会的一个开源项目。它的设计初衷是为了简化和自动化数据在不同系统之间的传输和处理,解决数据集成中的挑战。随着数据量和数据源的不断增加,NiFi 被设计为一个高效、灵活且可扩展的平台,以应对复杂的数据流需求。
2.核心概念和架构
定义:
FlowFile 是 NiFi 中的基本数据单元,包含实际的数据内容和元数据。每个FlowFile 由内容和属性两部分组成。
属性:
键值对形式的元数据,用于描述内容或控制处理逻辑。
定义:
处理器是执行数据处理任务的组件。NiFi 提供了丰富的处理器库,用于执行各种操作,如数据过滤、转换、路由、聚合等。
类型:
包括数据输入/输出处理器、转换处理器、路由处理器等。
定义:
连接器用于将处理器连接起来,定义数据流路径。连接器可以在处理器之间缓冲数据,控制数据流速率和优先级。
定义:
处理组是用于组织和管理一组相关处理器和连接器的容器,可以嵌套,实现数据流的模块化和层次化管理。
作用:
支持复杂数据流的结构化设计,提高可维护性和重用性。
定义:
控制器服务是共享的资源服务,如数据库连接池、分布式缓存等,供多个处理器使用。
定义:
报告任务用于生成和发送系统运行报告,包括统计信息、监控指标等。
作用:
提供系统运行状态的可见性,支持运维和优化。
3.主要功能
通过拖放式界面创建和管理数据流,降低复杂数据集成任务的门槛。
支持实时监控和调试,提供数据流的全生命周期管理。
支持实时数据采集、处理和传输,确保数据的及时性和一致性。
内置丰富的实时处理器,如Kafka、MQTT、HTTP等,支持各种数据源和协议。
支持基于内容、属性和规则的数据路由,实现复杂的流控制和分支。
提供强大的条件判断和决策功能,动态调整数据流路径。
内置多种数据转换处理器,支持数据格式转换、清洗、聚合和增强。
支持自定义脚本(如Groovy、Jython)进行复杂的数据处理。
基于插件架构,支持自定义处理器、控制器服务和报告任务的扩展。
提供丰富的API和SDK,支持二次开发和集成。
提供细粒度的用户认证和权限控制,确保数据访问的安全性。
支持数据加密、审计和溯源,满足企业级安全和合规要求。
支持分布式集群部署,提高系统的可扩展性和容错能力。
提供自动负载均衡和故障恢复,确保高可用性。
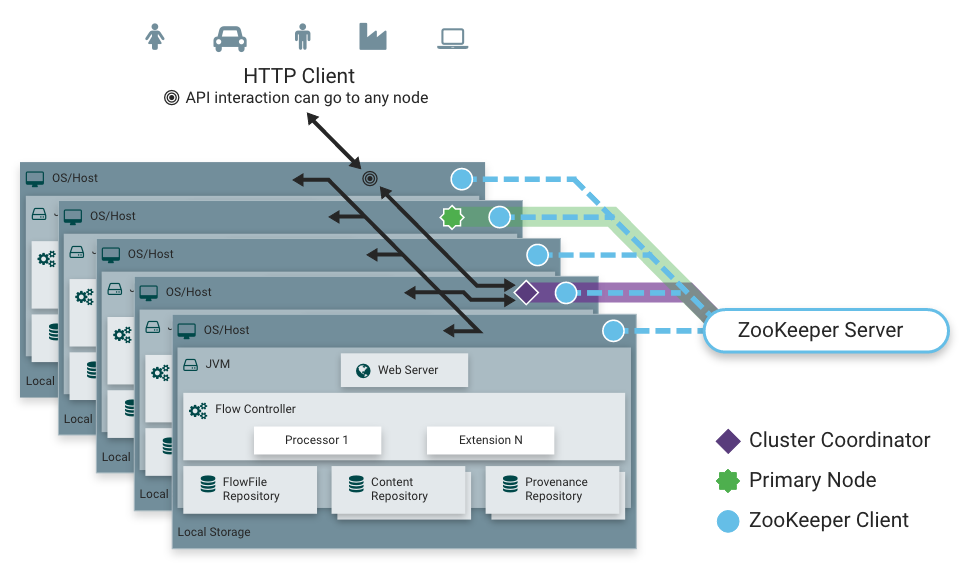
4.架构深度解析
用户界面,通过浏览器访问,用于创建、管理和监控数据流。
提供可视化的设计和调试工具,支持实时数据流的操作和监控。
数据流控制器,负责协调NiFi实例中的数据流和任务调度。
管理处理器的执行顺序和资源分配,确保数据流的高效运行。
扩展系统,支持通过插件扩展NiFi的功能,如自定义处理器、控制器服务和报告任务。
提供高效的数据存储和访问机制,支持大规模数据的持久化和检索。
FlowFile存储库,用于存储FlowFile的元数据和状态信息。
管理FlowFile的生命周期和状态变迁,支持数据流的可靠传输。
5.使用案例
实现设备数据的实时监控和智能分析,支持预测性维护和优化。
处理和传输实时数据流,如日志数据、点击流数据和金融交易数据。
提供高效的数据处理和分析能力,支持实时决策和响应。
从各种数据源采集数据并存储到数据湖中,为后续分析和处理提供支持。
实现数据的集中存储和管理,支持大数据分析和机器学习。
提供高效的数据转换和加载能力,支持复杂的数据集成任务。
在不同云平台和本地环境之间集成数据,确保数据的一致性和可用性。
支持跨平台的数据流管理和监控,实现云资源的优化利用。
6.系统要求
在安装Apache NiFi之前,请确保您的系统满足以下要求:
操作系统:Linux, macOS, 或 Windows
7.安装步骤
访问Apache NiFi官网下载最新版本的NiFi压缩包。
https://archive.apache.org/dist/nifi/
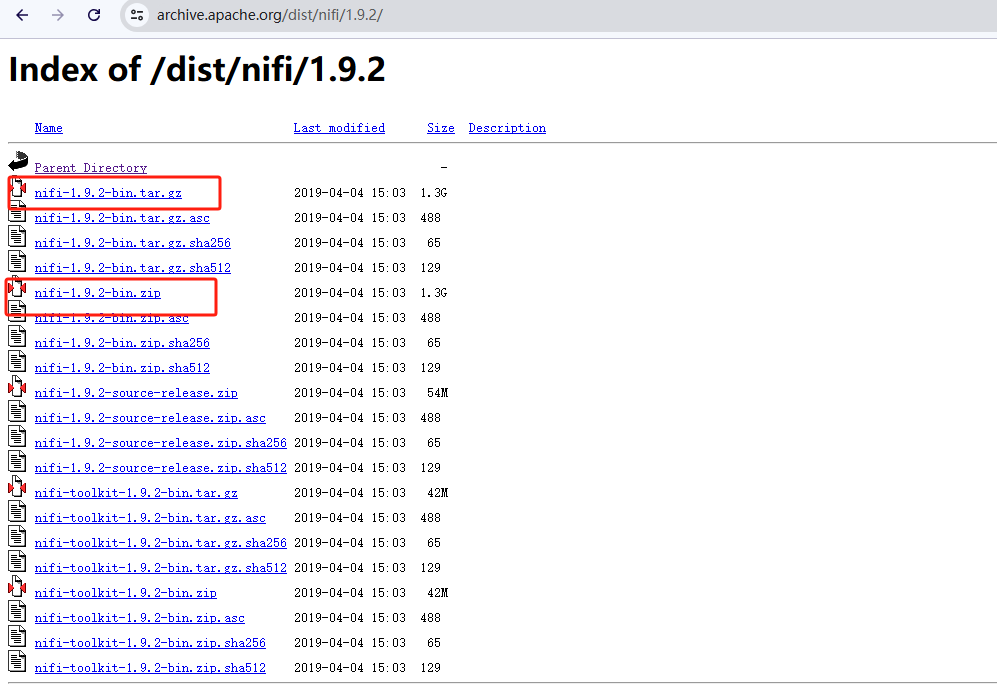
Windows选择nifi-x.x.x-bin.zip
Linux选择nifi-x.x.x-bin.tar.gz
选择合适的二进制分发(如 nifi-
-bin.tar.gz 或 nifi-
-bin.zip)。
tar -xvzf nifi--bin.tar.gz
配置 JAVA_HOME 环境变量,确保指向正确的Java安装目录。bash
export JAVA_HOME=/path/to/java
将 NiFi 的 bin 目录添加到 PATH 环境变量中(可选)。
export PATH=$PATH:/path/to/nifi-/bin
进入 NiFi 解压目录下的 bin 目录,运行启动脚本:bash
打开浏览器,访问 http://localhost:8080/nifi。如果一切正常,您将看到NiFi的Web用户界面。
8.配置和使用教程
在浏览器中打开 http://localhost:8080/nifi,您将看到NiFi的图形化用户界面。
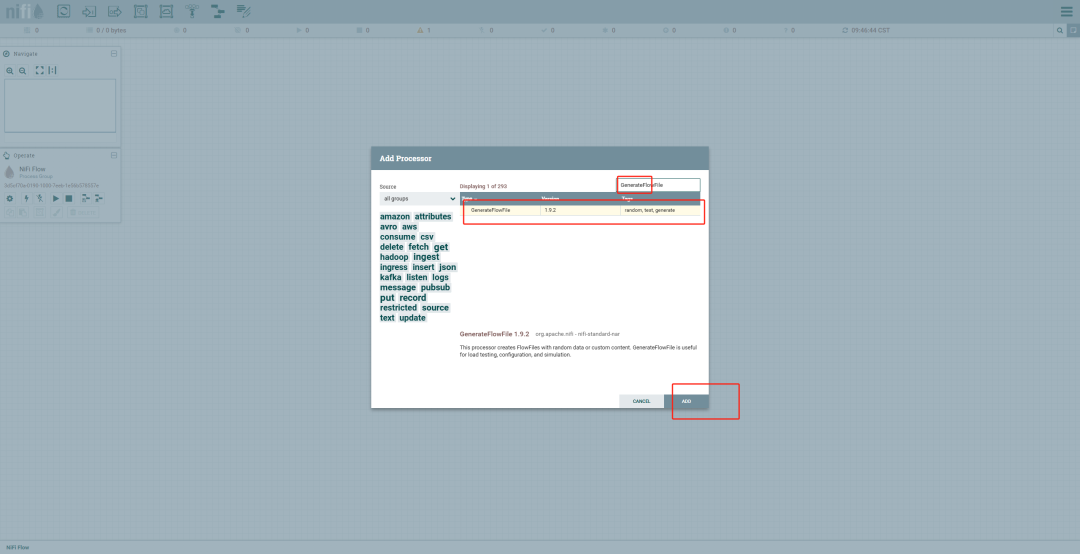
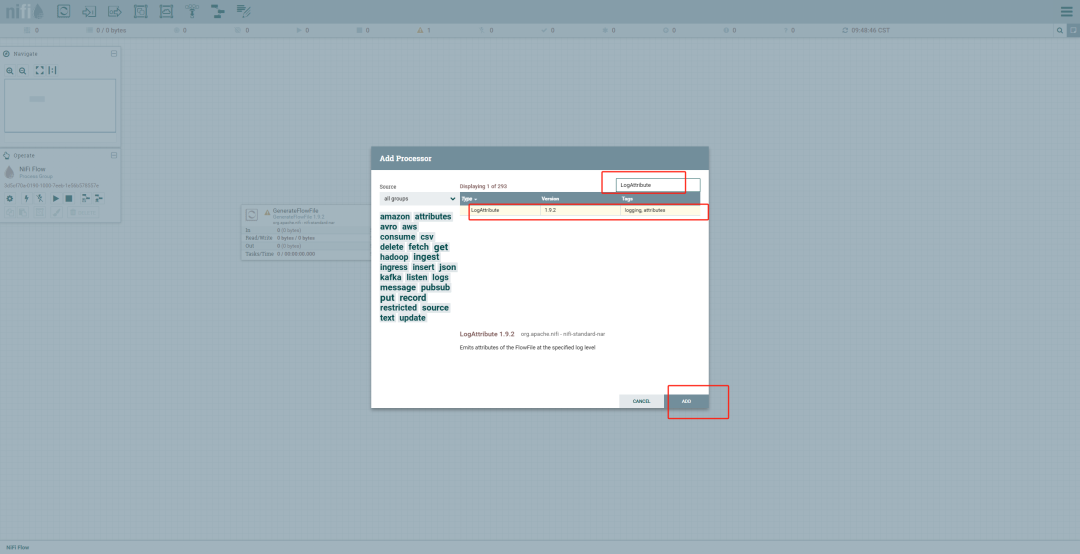
添加处理器:
在画布上右键单击,选择 Add Processor,从列表中选择一个处理器(如 GenerateFlowFile)。
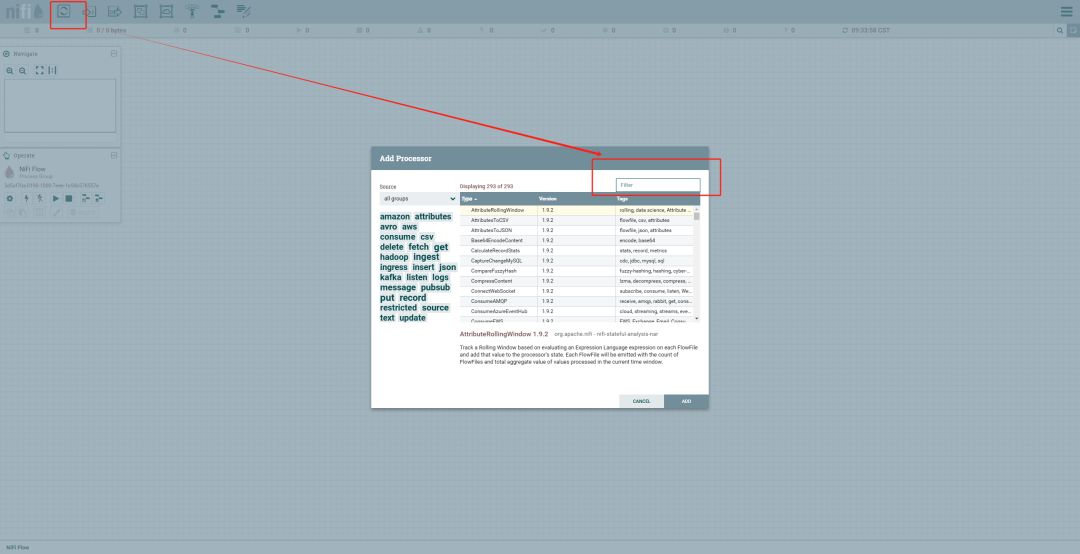
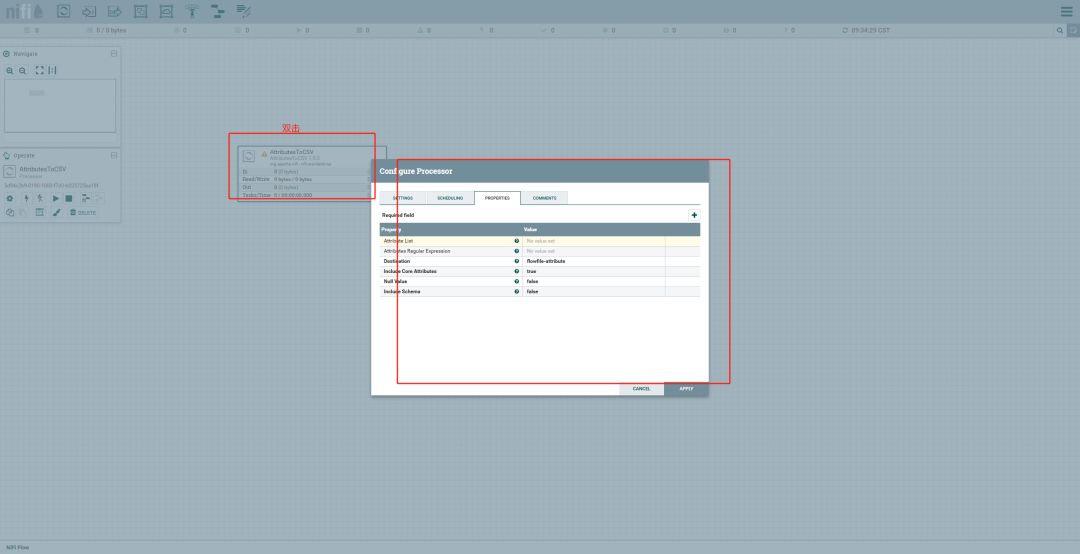
配置处理器:
双击处理器图标,打开配置窗口。根据需要配置处理器参数。
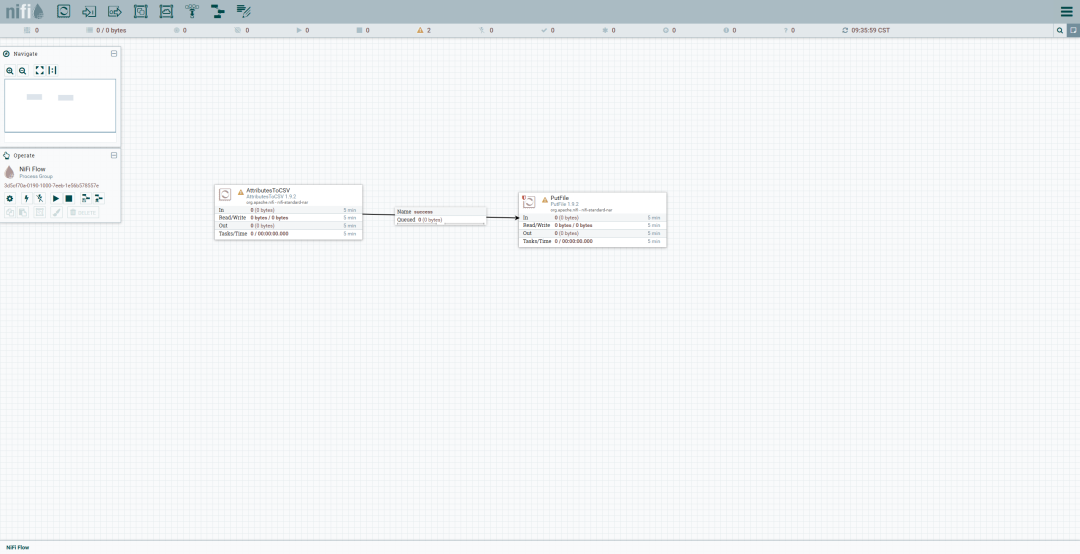
连接处理器:
选择一个处理器,点击箭头图标,将其连接到另一个处理器,配置连接属性。
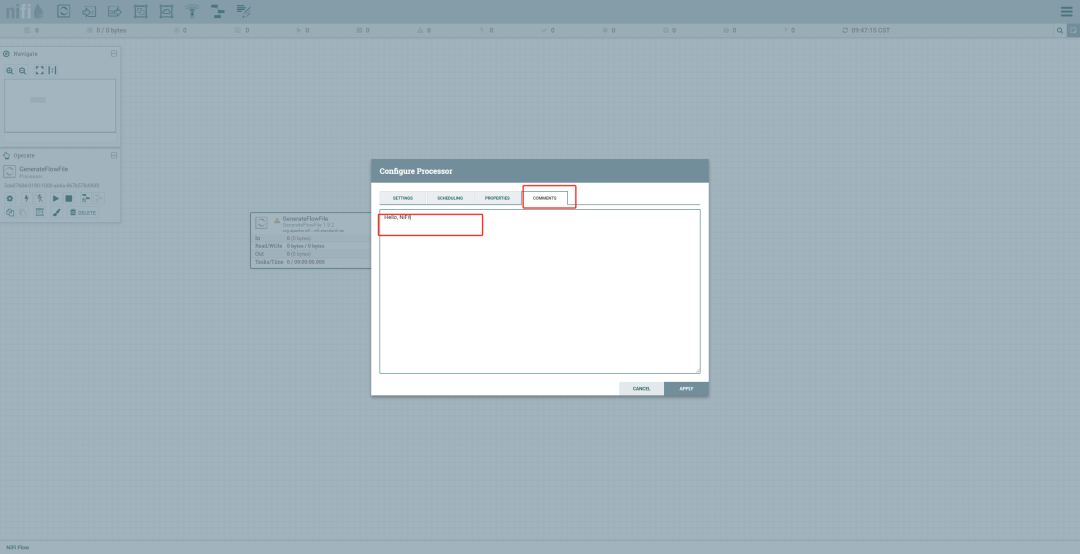
生成测试数据:添加一个 GenerateFlowFile 处理器,配置 Custom Text 属性为 Hello, NiFi!。
添加一个 LogAttribute 处理器,将 GenerateFlowFile 处理器输出连接到 LogAttribute 处理器。
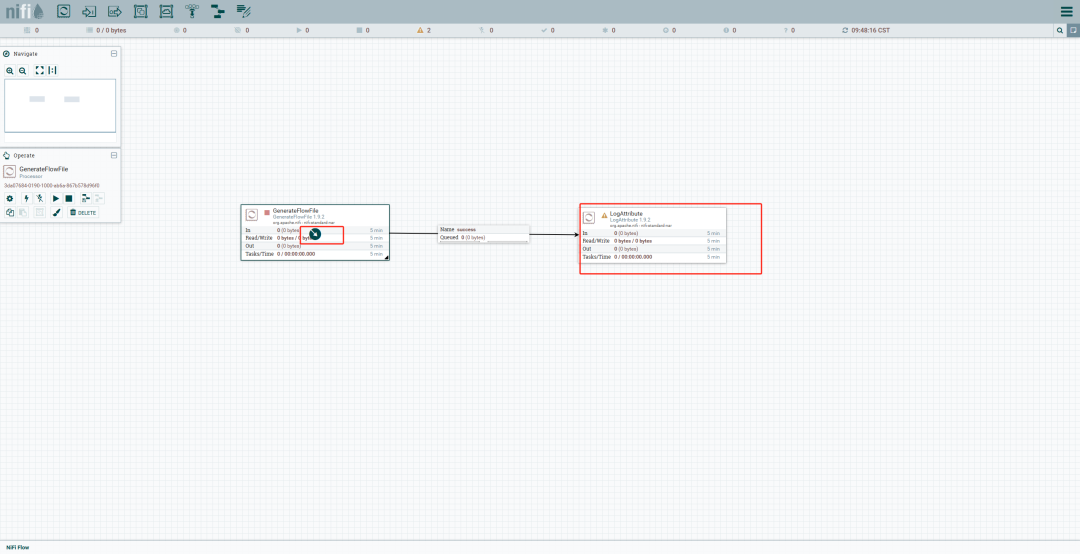
启动数据流:点击工具栏中的启动按钮,启动所有处理器。您将在 LogAttribute 的日志中看到生成的测试数据。
监控数据流:
在NiFi UI中,您可以实时查看数据流的状态、处理速率和流量。
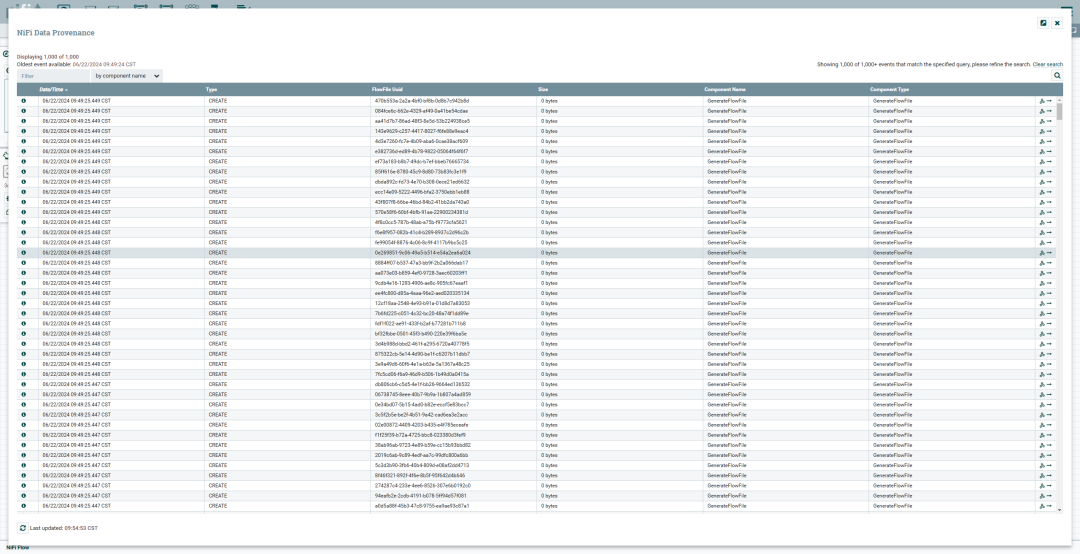
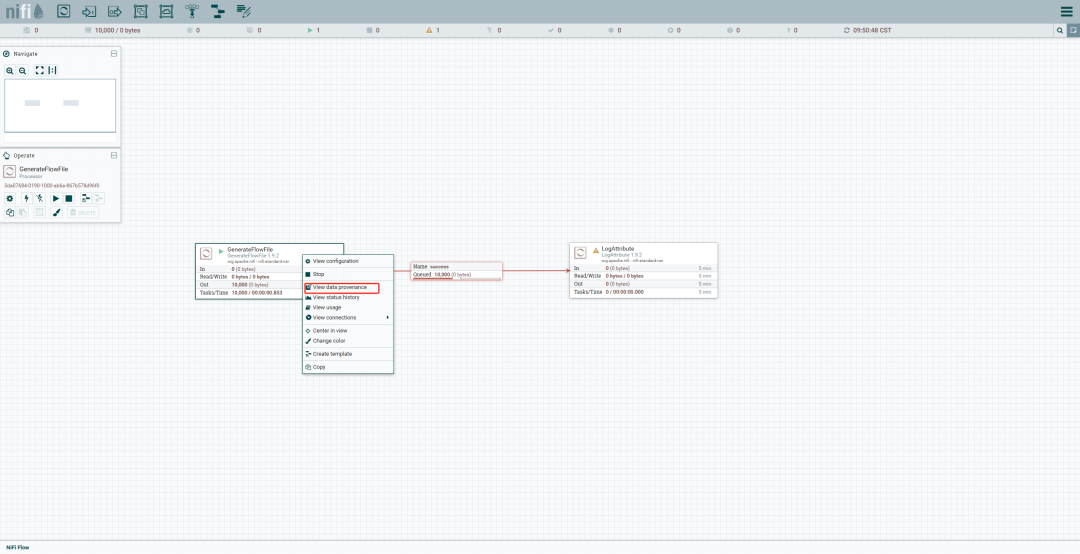
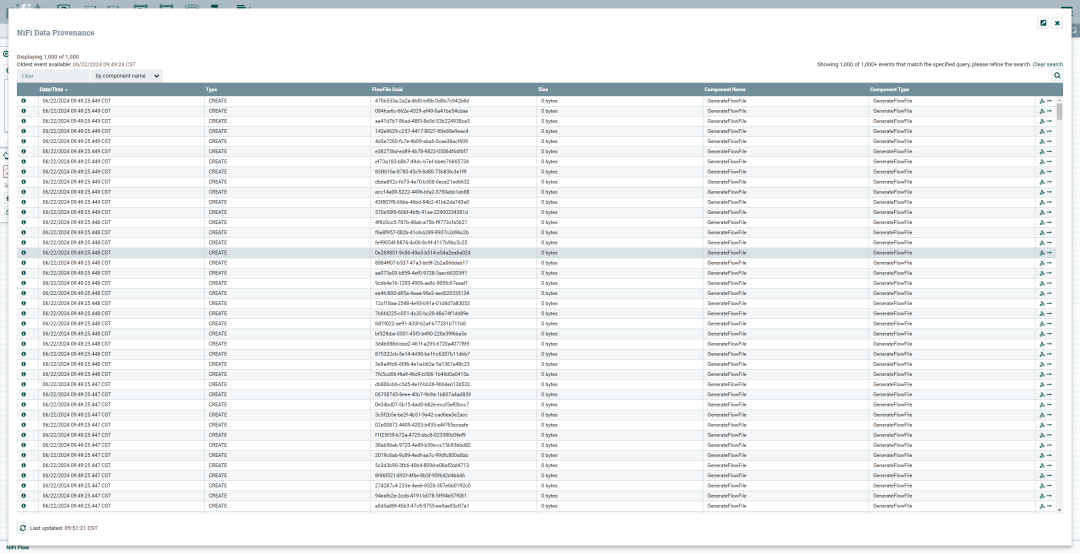
查看数据溯源:
右键单击处理器,选择 View data provenance,可以查看数据流的详细历史记录和变更信息。
停止 NiFi:在 bin 目录下运行停止脚本:bash
9.高级配置
用户认证:NiFi 支持LDAP、Kerberos和单点登录(SSO)等多种用户认证方式。可以在 conf/nifi.properties 文件中配置相关参数。
数据加密:NiFi 支持传输层加密(TLS/SSL)和内容加密。在 conf/nifi.properties 和 conf/bootstrap.conf 文件中配置加密参数。
配置集群节点:在 conf/nifi.properties 文件中,配置集群节点的主机名和端口。
启用集群模式:在 conf/nifi.properties 文件中,设置 nifi.cluster.is.node 为 true,并配置 nifi.cluster.node.address 和 nifi.cluster.node.protocol.port。
管理集群:使用集群管理工具(如 Apache Ambari)监控和管理NiFi集群。
自定义处理器:NiFi 提供了丰富的API和SDK,支持开发自定义处理器、控制器服务和报告任务。
插件安装:将自定义的NiFi组件打包成NAR(NiFi Archive)文件,放置到 lib 目录下,重启NiFi即可加载新组件。
感谢阅读,共同进步

