作者:微信小助手
发布时间:2023-11-27T05:14:02
实时数据同步是现代数据处理中非常重要的一环。在常见的数据同步工具中,Flume、Flink CDC和DataX都是非常受欢迎的选择。它们各自有自己的工作原理、优势和劣势。
Flume主要用于日志传输,简单易用但对特定数据源可能有限;Flink CDC基于CDC技术实现了实时的数据同步,性能高但在复杂场景下可能需要额外的工作;DataX CDC则是基于CDC技术的实时数据同步工具,具备实时同步、高性能和精确同步的优势,但需要对不同的数据源进行适配,并对数据库性能产生一定影响。选择适合自己场景的工具,能够更好地满足数据同步的需求。

01
—
Flume
一、Flume的工作原理和优势
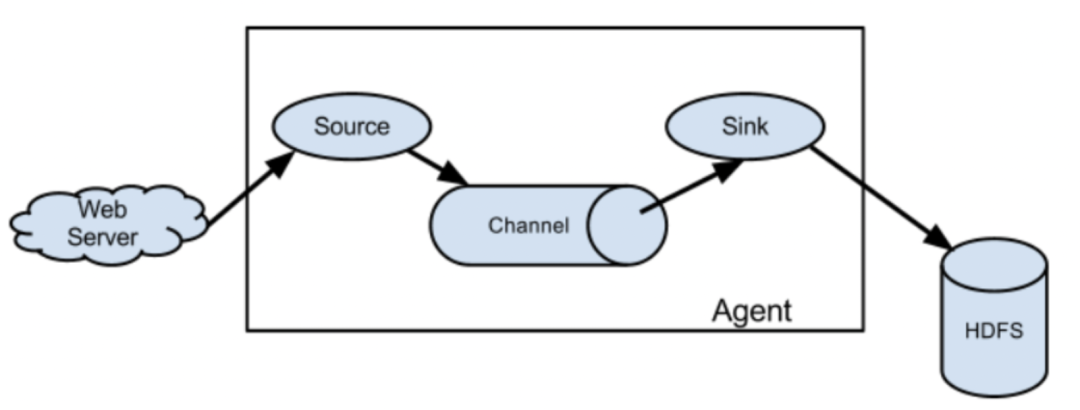
Flume的原理是将数据从源头(source)采集,经过一个或多个中间节点(channel)进行传输,最终发送到目的地(sink)。下面是Flume的工作原理的详细解释:
1、Source(数据源):Source负责从数据源(如日志文件、网络流、消息队列等)采集数据,并将数据发送到Channel。
2、Channel(通道):Channel是数据传输的中间节点,它负责暂存Source采集到的数据。Channel可以是内存、磁盘或者其他存储介质,可以按照事务或批量的方式传输数据。
3、Sink(数据目的地):Sink从Channel中获取数据,并将数据发送到指定的目的地(如HDFS、关系型数据库、消息队列等)进行存储和分析。
4、Agent(代理):Agent是Flume的一个独立运行实例,它由Source、Channel和Sink组成,负责管理整个数据流的采集、传输和存储。
Flume的可靠性和容错性体现在以下几个方面:
1、消息确认:Channel会对消息进行确认,确保数据在传输过程中不会丢失。
2、事务机制:Flume使用事务机制来确保数据的可靠传输,如果发送失败,会进行回滚和重试操作。
3、失败处理:Flume提供了失败处理机制,可以配置重试策略、错误日志记录等来处理发送失败的情况。
总的来说,Flume通过源头采集数据,经过中间节点传输,最后发送到目的地实现数据的收集和传输。通过可靠的机制和丰富的配置选项,可以保证数据的安全和可靠传输。
Flume支持的实时采集数据源类型:
| 数据源类型 | 说明 |
AvroSource |
Flume中使用最多的一种数据源类型,它能够将消息数据在不同节点之间进行安全可靠地传输,可以从另一个AvroSource或AvroSink中接收消息 |
SpoolingDirectorySource |
它会监控特定目录下的新文件,它会将这些新文件中的信息读取出来,然后将其数据转换成消息体,传输到指定的sink。
|
SyslogTcpSource |
专门用于接收syslog方式协议的日志流量,并将其内容转换为消息体进行采集。 |
JMS source |
专门用于接收JMS(Java Messaging Service) 方式协议的消息流量,并将其内容转换为消息体进行采集,用于数据中心之间的数据传输。
|
Kafka Source |
专门用于接收Kafka 协议的消息,并将其内容转换为消息体进行采集,Kafka是一种分布式发布-订阅消息系统,它能够很好地解决大规模消息传输的需求。 |
02
—
Flink CDC
一、Flink CDC的工作原理和优势
Flink CDC通过与数据库进行交互,实时捕获数据库中的变更操作。它的工作原理可以分为以下几个步骤:
1. 数据库连接和监控:首先,Flink CDC需要与目标数据库建立连接,并监控数据库的变更操作。它可以通过监听数据库的事务日志或者使用数据库引擎的内部机制来实现。
2. 变更事件解析:一旦数据库发生变更操作,Flink CDC会解析这些变更事件。它会将变更事件转化为对应的数据结构,例如INSERT、UPDATE或DELETE操作。
3. 数据转换和格式化:解析后的变更事件需要经过数据转换和格式化,以便能够被Flink进行处理。Flink CDC会将变更事件转化为Flink支持的数据格式,例如JSON、Avro等。
4. 事件流生成:经过转换和格式化后,Flink CDC会将变更事件转化为数据流。这个数据流可以被Flink的流处理任务进行消费和处理。
5. 数据同步和传输:生成的数据流可以被传输到不同的目的地,例如Flink的流处理任务、消息队列或者其他外部系统。这样,我们就可以对变更事件进行实时分析和处理。