作者:微信小助手
发布时间:2023-10-09T16:36:25
目录导读

HydraQL 简介
HydraQL中的 SQL 语法更轻量,无需引入额外的组件和配置即可使用,且对 HBase 无倾入性,但目前还不支持聚合查询、表关联、以及二级索引等高阶功能。
HBase 简介和应用场景
HBase 是 Apache 的顶级项目之一,是一款开源的、分布式的、面向列的 NoSQL 数据库系统。它基于 Hadoop 的分布式文件系统(HDFS)构建,并且在 Hadoop 生态系统中充当高可靠、高性能和可伸缩性的实时数据存储和处理解决方案。
-
存储海量实时数据,如社交网络的消息、实时日志数据、在线游戏的玩家数据等。 -
适用于需要高可靠性的应用,HBase 的设计使得数据可以以冗余的方式存储在分布式环境中,从而保证数据的持久性和可靠性。 -
用于在线分析处理(OLAP)和实时查询分析(OLTP)的场景。唔,OLAP 还是不太适合 -
HBase 提供对大规模数据的低延迟随机读写操作,使得它成为处理实时分析和查询的理想选择。
-
分布式架构:HBase 以集群的方式部署,数据分布在多个节点上,从而实现数据的高可用性和负载均衡。 -
列式存储:HBase 将数据存储在列族中,每个列族可以包含单独定义的列,并将数据按照列进行存储,从而提高查询效率。 -
强一致性:HBase 通过强一致性保证数据的正确性,即在写入和读取操作过程中,始终保证数据的一致性。 -
高可扩展性:HBase 支持水平扩展,即可以通过添加更多的节点来增加存储容量和处理能力。关于数据量规模,HBase 可以存储海量级别的数据。它可以通过添加更多的 RegionServer 节点来水平扩展,以存储和处理更大规模的数据。
-
Facebook:Facebook 使用 HBase 来存储和处理用户的消息、通知、实时新闻源等实时数据,提供实时的社交网络服务。
-
Twitter:Twitter 使用 HBase 作为其实时分析和查询引擎的后端存储,用于存储和处理大规模的社交网络数据、实时推文和用户行为数据等。
-
Airbnb:Airbnb 使用 HBase 来存储和处理其大规模的实时用户数据,包括订房信息、用户行为数据和实时推荐。
-
Yahoo:Yahoo 使用 HBase 作为其广告平台的后端存储,用于存储和处理广告投放相关的海量数据。
-
Spotify:Spotify 使用 HBase 来存储和处理音乐流媒体服务中的海量用户数据,包括播放历史、音乐推荐和用户互动数据等。
HydraQL 尝鲜示例
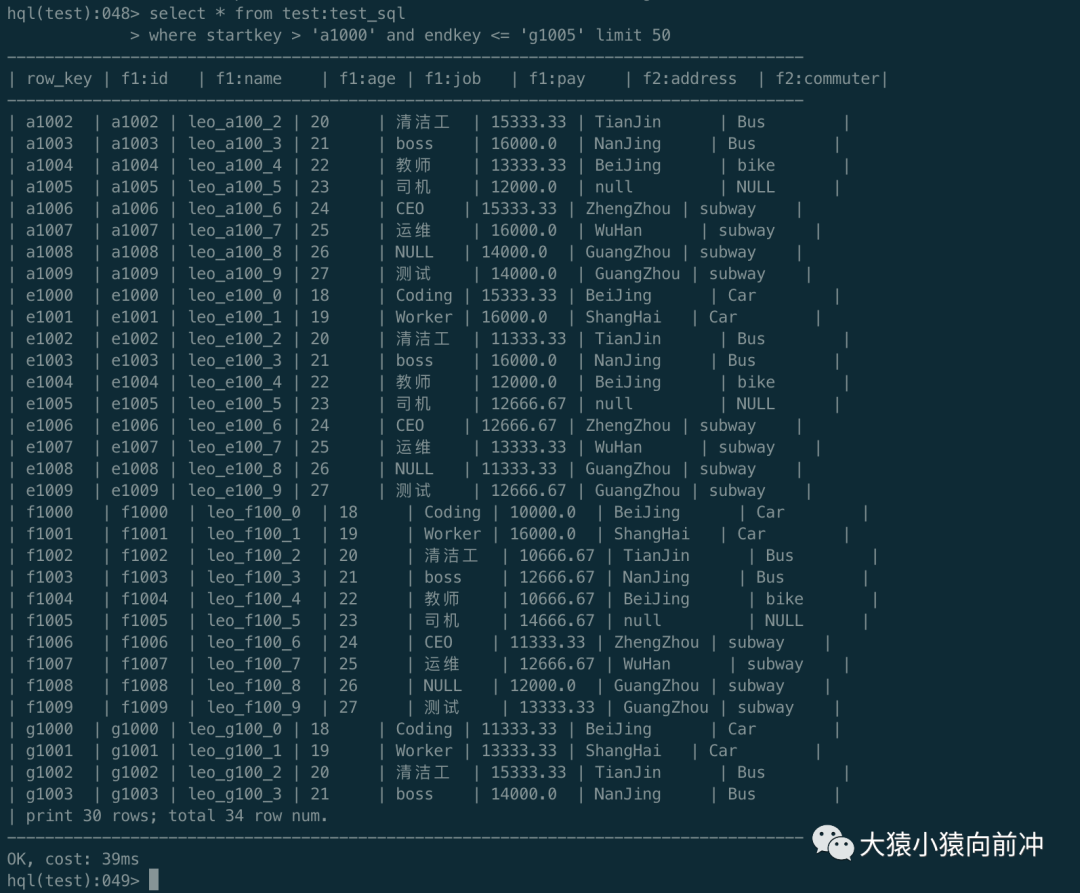
筛选 rowKey 范围在('a1000', 'g1005'],年龄>=18 岁,得有工作或者薪酬大于 1 万,有交通工具,而且交通工具不能是公交、自行车和地铁的人员信息。