作者:微信小助手
发布时间:2023-02-08T15:58:42
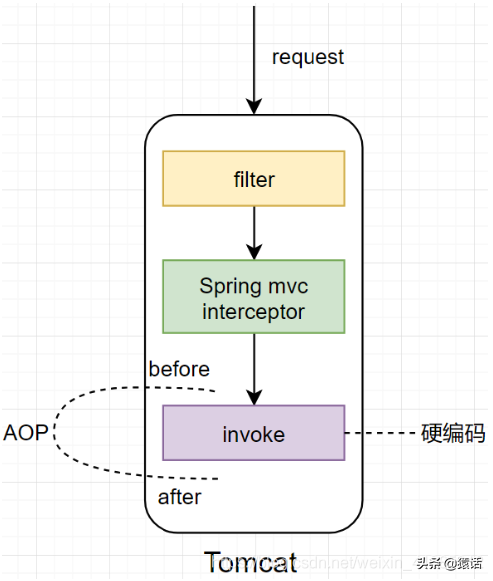
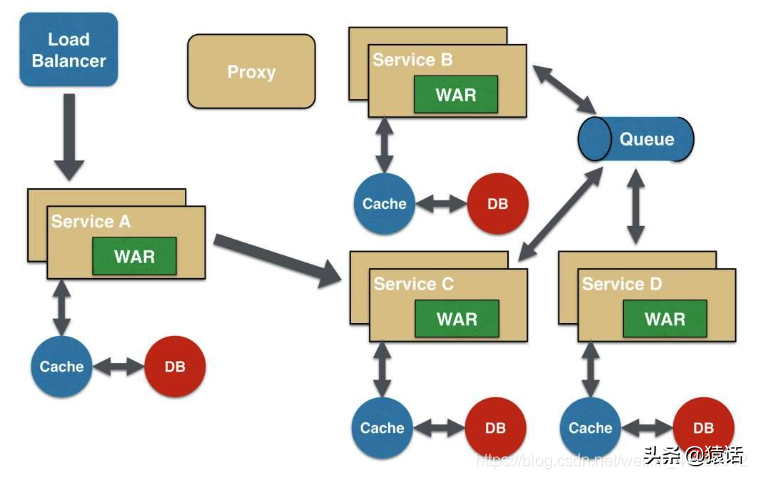
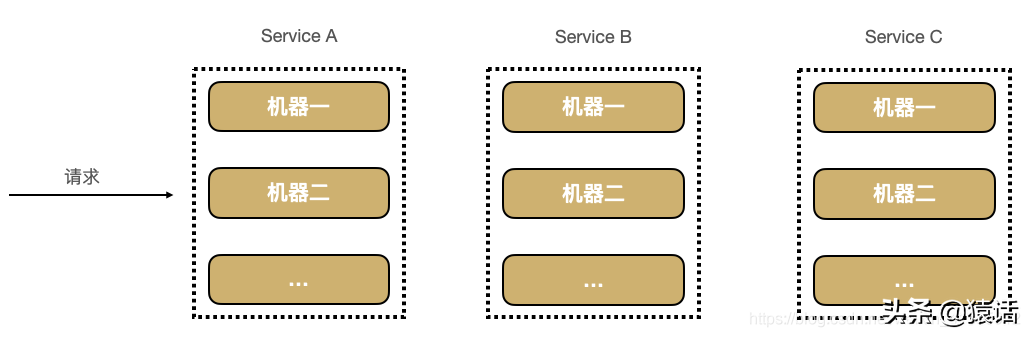
在分布式系统,尤其是微服务系统中,一次外部请求往往需要内部多个模块,多个中间件,多台机器的相互调用才能完成。在这一系列的调用中,可能有些是串行的,而有些是并行的。在这种情况下,我们如何才能确定这整个请求调用了哪些应用?哪些模块?哪些节点?以及它们的先后顺序和各部分的性能如何呢? 这就是涉及到链路追踪。 什么是链路追踪? 链路追踪是分布式系统下的一个概念,它的目的就是要解决上面所提出的问题,也就是将一次分布式请求还原成调用链路,将一次分布式请求的调用情况集中展示,比如,各个服务节点上的耗时、请求具体到达哪台机器上、每个服务节点的请求状态等等。 链路追踪的原理 衡量一个接口,我们一般会看三个指标: 1、接口的 RT(Route-Target)你怎么知道? 1、单体架构时代 在创业初期,我们的系统一般是单体架构,如下: 对于单体架构,我们可以使用 AOP(切面编程)来统计这三个指标,如下: 使用 AOP(切面编程),对原本的逻辑代码侵入更少,我们只需要在调用具体的业务逻辑前后分别打印一下时间即可计算出整体的调用时间。另外,使用 AOP(切面编程)来捕获异常也可知道是哪里的调用导致的异常。 2、微服务架构 随着业务的快速发展,单体架构越来越不能满足需要,我们的系统慢慢会朝微服务架构发展,如下: 在微服务架构下,当有用户反馈某个页面很慢时,虽然我们知道这个请求可能的调用链是 A -----> C -----> B -----> D,但服务这么多,而且每个服务都有好几台机器,怎么知道问题具体出在哪个服务?哪台机器呢? 这也是微服务这种架构下的几个痛点: 1、排查问题难度大,周期长 分布式调用链就是为了解决以上几个问题而生,它主要的作用如下: 1、自动采取数据 通过分布式追踪系统,我们能很好地定


2、接口是否有异常响应?
3、接口请求慢在哪里?
2、特定场景难复现
3、系统性能瓶颈分析较难
2、分析数据,产生完整调用链:有了请求的完整调用链,问题有很大概率可复现
3、数据可视化:每个组件的性能可视化,能帮助我们很好地定位系统的瓶颈,及时找出问题所在