作者:微信小助手
发布时间:2022-07-05T11:55:42
我们应该从 Redis 是如何保存数据的原理展开,分析键值对的存储结构和原理。 从而继续延展出每种数据类型底层的数据结构,针对不同场景使用更恰当的数据结构和编码实现更少的内存占用。 为了保存数据, Redis 需要先申请内存,数据过期或者内存淘汰需要回收内存,从而拓展出内存碎片优化。 最后,说下 key、value 使用规范和技巧、 Bitmap 等高阶数据类型,运用这些技巧巧妙解决有限内存去存储更多数据难题…… 这一套组合拳下来直接封神。 具体详情,且看「码哥」一一道来。 主要优化神技如下: 在优化之前,我们先掌握 Redis 是如何存储数据的。 Redis 以 Redis 使用「dict」结构来保存所有的键值对(key-value)数据,这是一个全局哈希表,所以对 key 的查询能以 O(1) 时间得到。 所谓哈希表,我们可以类比 Java 中的 dict 结构如下,源码在 key 的哈希值最终会映射到 ht_table 的一个位置,如果发生哈希冲突,则拉出一个哈希链表。 大家重点关注 码哥,Redis 支持那么多的数据类型,哈希桶咋保存? 哈希桶的每个元素的结构由 dictEntry 定义: 哈希桶并没有保存值本身,而是指向具体值的指针,从而实现了哈希桶能存不同数据类型的需求。 而哈希桶中,键值对的值都是由一个叫做 如下图是由 redisDb、dict、dictEntry、redisObejct 关系图: 「码哥」再唠叨几句,void *key 和 void *value 指针指向的是 redisObject,Redis 中每个对象都是用 知道了 Redis 存储原理以及不同数据类型的存储数据结构后,我们继续看如何做性能优化。
Redis 如何存储键值对
redisDb为中心存储,redis 7.0 源码在 https://github.com/redis/redis/blob/7.0/src/server.h: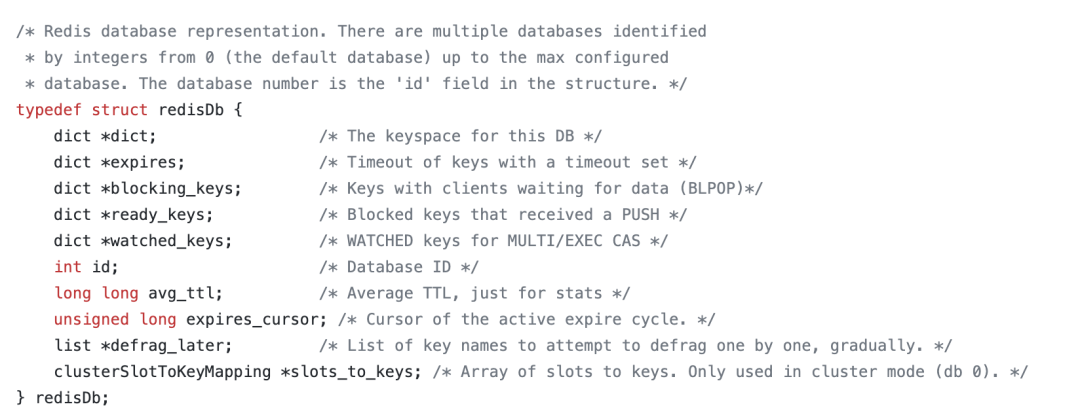
HashMap,其实就是一个数组,数组的每个元素叫做哈希桶。https://github.com/redis/redis/blob/7.0/src/dict.h:struct dict {
// 特定类型的处理函数
dictType *type;
// 两个全局哈希表指针数组,与渐进式 rehash 有关
dictEntry **ht_table[2];
// 记录 dict 中现有的数据个数。
unsigned long ht_used[2];
// 记录渐进式 rehash 进度的标志, -1 表示当前没有执行 rehash
long rehashidx;
// 小于 0 表示 rehash 暂停
int16_t pauserehash;
signed char ht_size_exp[2];
};
dictEntry 类型的 ht_table,ht_table 数组每个位置我们也叫做哈希桶,就是这玩意保存了所有键值对。
❝
typedef struct dictEntry {
// 指向 key 的指针
void *key;
union {
// 指向实际 value 的指针
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
// 哈希冲突拉出的链表
struct dictEntry *next;
} dictEntry;
redisObject 的对象定义,源码地址:https://github.com/redis/redis/blob/7.0/src/server.h。typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS;
int refcount;
void *ptr;
} robj;

redisObject 表示。1. 键值对优化