作者:微信小助手
发布时间:2022-06-15T13:24:19
大家好,我是捡田螺的小男孩。作为后端开发,不管是什么语言, 我们做后端开发工程师,主要工作就是:如何把一个接口设计好。所以,今天就给大家介绍,设计好接口的36个锦囊。本文就是后端思想专栏的第一篇哈。 入参出参校验是每个程序员必备的基本素养。你设计的接口,必须先校验参数。比如入参是否允许为空,入参长度是否符合你的预期长度。这个要养成习惯哈,日常开发中,很多低级bug都是不校验参数导致的。 比如你的数据库表字段设置为 出参也是,比如你定义的接口报文,参数是不为空的,但是你的接口返回参数,没有做校验,因为程序某些原因,直返回别人一个 很多bug都是因为修改了对外旧接口,但是却不做兼容导致的。关键这个问题多数是比较严重的,可能直接导致系统发版失败的。新手程序员很容易犯这个错误哦~ 所以,如果你的需求是在原来接口上修改,尤其这个接口是对外提供服务的话,一定要考虑接口兼容。举个例子吧,比如dubbo接口,原本是只接收A,B参数,现在你加了一个参数C,就可以考虑这样处理: 要根据实际业务场景设计接口,充分考虑接口的可扩展性。 比如你接到一个需求:是用户添加或者修改员工时,需要刷脸。那你是反手提供一个员工管理的提交刷脸信息接口?还是先思考:提交刷脸是不是通用流程呢?比如转账或者一键贴现需要接入刷脸的话,你是否需要重新实现一个接口呢?还是当前按业务类型划分模块,复用这个接口就好,保留接口的可扩展性。 如果按模块划分的话,未来如果其他场景比如一键贴现接入刷脸的话,不用再搞一套新的接口,只需要新增枚举,然后复用刷脸通过流程接口,实现一键贴现刷脸的差异化即可。 如果前端重复请求,你的逻辑如何处理?是不是考虑接口去重处理。 当然,如果是查询类的请求,其实不用防重。如果是更新修改类的话,尤其金融转账类的,就要过滤重复请求了。简单点,你可以使用Redis防重复请求,同样的请求方,一定时间间隔内的相同请求,考虑是否过滤。当然,转账类接口,并发不高的话,推荐使用数据库防重表,以唯一流水号作为主键或者唯一索引。 一些登陆、转账交易、下单等重要接口,考虑线程池隔离哈。如果你所有业务都共用一个线程池,有些业务出bug导致线程池阻塞打满的话,那就杯具了,所有业务都影响了。因此进行线程池隔离,重要业务分配多一点的核心线程,就更好保护重要业务。 如果你调用第三方接口,或者分布式远程服务的的话,需要考虑: 比如,你调别人的接口,如果异常了,怎么处理,是重试还是当做失败还是告警处理。 没法预估对方接口一般多久返回,一般设置个超时断开时间,以保护你的接口。之前见过一个生产问题,就是http调用不设置超时时间,最后响应方进程假死,请求一直占着线程不释放,拖垮线程池。 你的接口调失败,需不需要重试?重试几次?需要站在业务上角度思考这个问题 当前互联网系统一般都是分布式部署的。而分布式系统中经常会出现某个基础服务不可用,最终导致整个系统不可用的情况, 这种现象被称为服务雪崩效应。 比如分布式调用链路 如果服务C出现问题,比如是因为慢SQL导致调用缓慢,那将导致B也会延迟,从而A也会延迟。堵住的A请求会消耗占用系统的线程、IO等资源。当请求A的服务越来越多,占用计算机的资源也越来越多,最终会导致系统瓶颈出现,造成其他的请求同样不可用,最后导致业务系统崩溃。 为了应对服务雪崩, 常见的做法是熔断和降级。最简单是加开关控制,当下游系统出问题时,开关降级,不再调用下游系统。还可以选用开源组件 关键业务代码无论身处何地,都应该有足够的日志保驾护航。比如:你实现转账业务,转个几百万,然后转失败了,接着客户投诉,然后你还没有打印到日志,想想那种水深火热的困境下,你却毫无办法。。。 那么,你的转账业务都需要哪些日志信息呢?至少,方法调用前,入参需要打印需要吧,接口调用后,需要捕获一下异常吧,同时打印异常相关日志吧,如下: 之前写过一篇打印日志的15个建议,大家可以看看哈:工作总结!日志打印的15个建议 单一性是指接口做的事情比较单一、专一。比如一个登陆接口,它做的事情就只是校验账户名密码,然后返回登陆成功以及 其实这也是微服务一些思想,接口的功能单一、明确。比如订单服务、积分、商品信息相关的接口都是划分开的。将来拆分微服务的话,是不是就比较简便啦。 举个简单的例子,比如你实现一个用户注册的接口。用户注册成功时,发个邮件或者短信去通知用户。这个邮件或者发短信,就更适合异步处理。因为总不能一个通知类的失败,导致注册失败吧。 至于做异步的方式,简单的就是用线程池。还可以使用消息队列,就是用户注册成功后,生产者产生一个注册成功的消息,消费者拉到注册成功的消息,就发送通知。 不是所有的接口都适合设计为同步接口。比如你要做一个转账的功能,如果你是单笔的转账,你是可以把接口设计同步。用户发起转账时,客户端在静静等待转账结果就好。如果你是批量转账,一个批次一千笔,甚至一万笔的,你则可以把接口设计为异步。就是用户发起批量转账时,持久化成功就先返回受理成功。然后用户隔十分钟或者十五分钟等再来查转账结果就好。又或者,批量转账成功后,再回调上游系统。 假设我们设计一个APP首页的接口,它需要查用户信息、需要查banner信息、需要查弹窗信息等等。那你是一个一个接口串行调,还是并行调用呢? 如果是串行一个一个查,比如查用户信息200ms,查banner信息100ms、查弹窗信息50ms,那一共就耗时 在Java中有个异步编程利器: 数据库操作或或者是远程调用时,能批量操作就不要for循环调用。 一个简单例子,我们平时一个列表明细数据插入数据库时,不要在for循环一条一条插入,建议一个批次几百条,进行批量插入。同理远程调用也类似想法,比如你查询营销标签是否命中,可以一个标签一个标签去查,也可以批量标签去查,那批量进行,效率就更高嘛。 小伙伴们是否了解过 哪些场景适合使用缓存?读多写少且数据时效要求越低的场景。 缓存用得好,可以承载更多的请求,提升查询效率,减少数据库的压力。 比如一些平时变动很小或者说几乎不会变的商品信息,可以放到缓存,请求过来时,先查询缓存,如果没有再查数据库,并且把数据库的数据更新到缓存。但是,使用缓存增加了需要考虑这些点:缓存和数据库一致性如何保证、集群、缓存击穿、缓存雪崩、缓存穿透等问题。 一般用 瞬时间的高并发,可能会打垮你的系统。可以做一些热点数据的隔离。比如业务隔离、系统隔离、用户隔离、数据隔离等。 假如产品经理提了个红包需求,圣诞节的时候,红包皮肤为圣诞节相关的,春节的时候,为春节红包皮肤等。 如果在代码写死控制,可有类似以下代码:前言
Java、Go还是C++,其背后的后端思想都是类似的。后面打算出一个后端思想的技术专栏,主要包括后端的一些设计、或者后端规范相关的,希望对大家日常工作有帮助哈。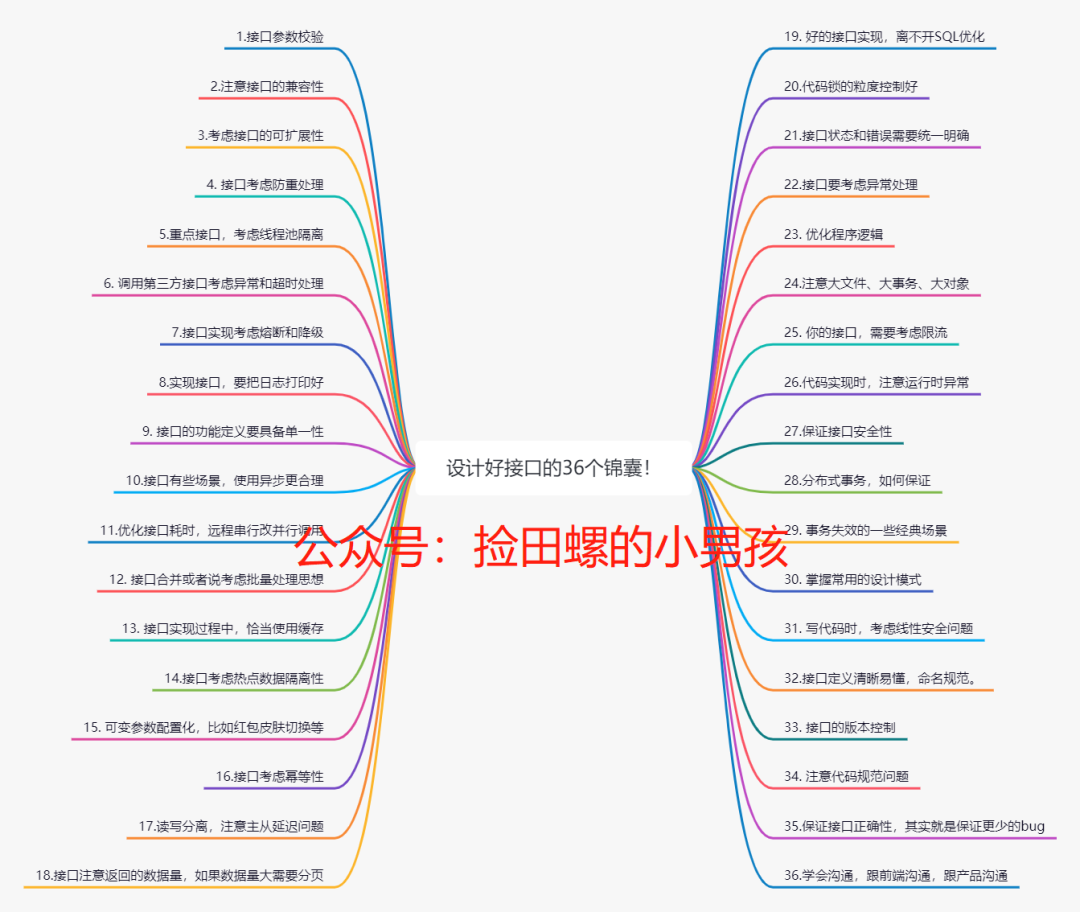
1. 接口参数校验
varchar(16),对方传了一个32位的字符串过来,如果你不校验参数,插入数据库直接异常了。null值。。。
2. 修改老接口时,注意接口的兼容性

//老接口
void oldService(A,B){
//兼容新接口,传个null代替C
newService(A,B,null);
}
//新接口,暂时不能删掉老接口,需要做兼容。
void newService(A,B,C){
...
}3. 设计接口时,充分考虑接口的可扩展性
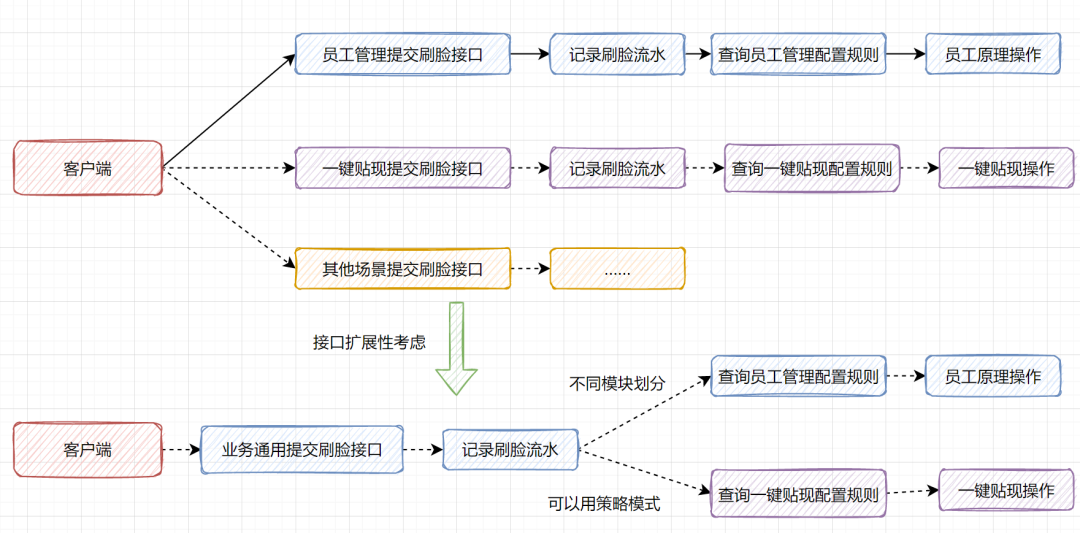
4.接口考虑是否需要防重处理

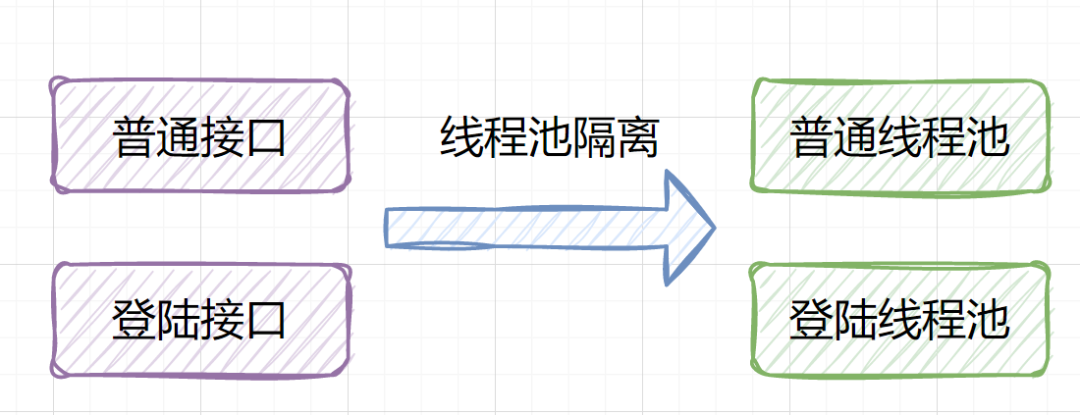
5. 重点接口,考虑线程池隔离。
6. 调用第三方接口要考虑异常和超时处理

7. 接口实现考虑熔断和降级
A->B->C....,下图所示: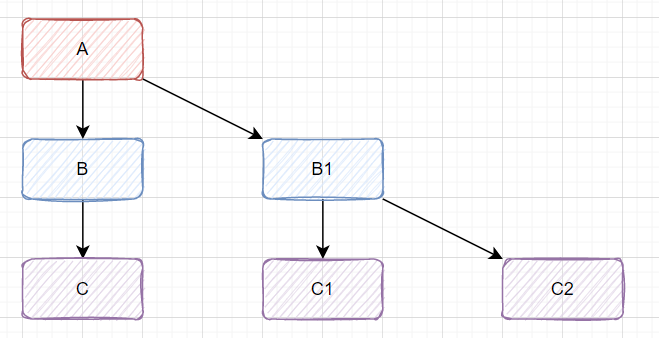
Hystrix。8. 日志打印好,接口的关键代码,要有日志保驾护航。
public void transfer(TransferDTO transferDTO){
log.info("invoke tranfer begin");
//打印入参
log.info("invoke tranfer,paramters:{}",transferDTO);
try {
res= transferService.transfer(transferDTO);
}catch(Exception e){
log.error("transfer fail,account:{}",
transferDTO.getAccount())
log.error("transfer fail,exception:{}",e);
}
log.info("invoke tranfer end");
}9. 接口的功能定义要具备单一性
userId即可。但是如果你为了减少接口交互,把一些注册、一些配置查询等全放到登陆接口,就不太妥。10.接口有些场景,使用异步更合理
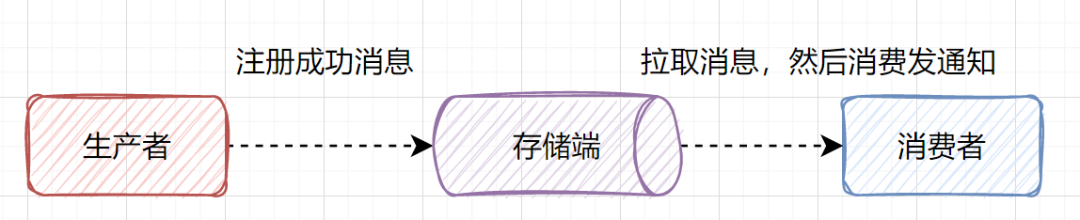
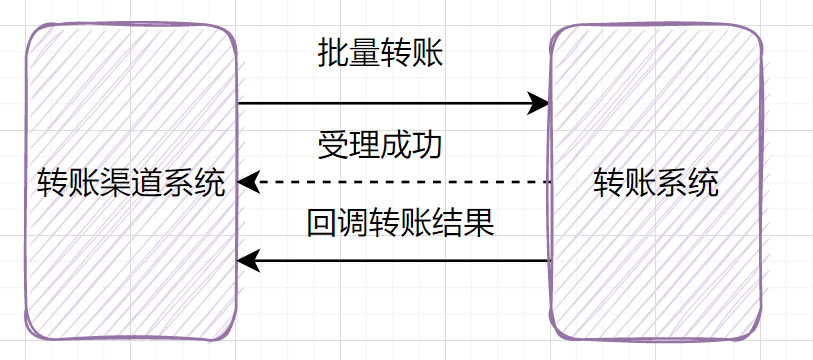
11. 优化接口耗时,远程串行考虑改并行调用
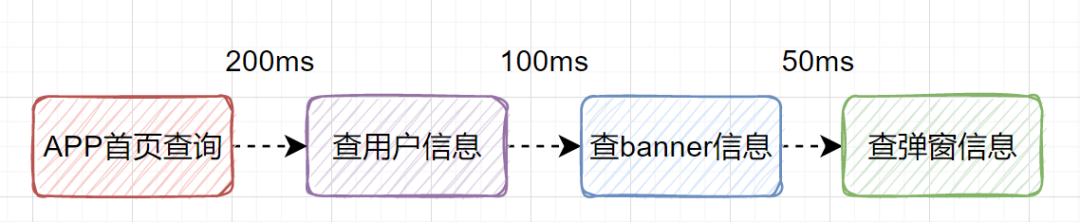
350ms了,如果还查其他信息,那耗时就更大了。这种场景是可以改为并行调用的。也就是说查用户信息、查banner信息、查弹窗信息,可以同时发起。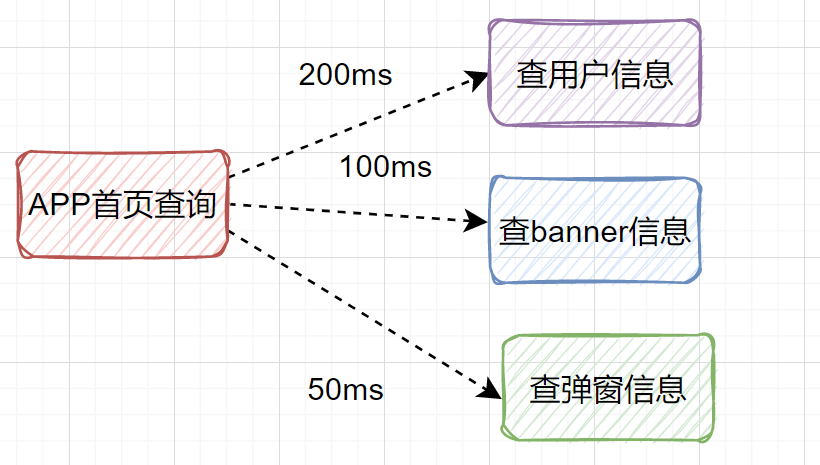
CompletableFuture,就可以很好实现这个功能。有兴趣的小伙伴可以看我之前这个文章哈:CompletableFuture详解12. 接口合并或者说考虑批量处理思想

//反例
for(int i=0;i<n;i++){
remoteSingleQuery(param)
}
//正例
remoteBatchQuery(param);kafka为什么这么快呢?其实其中一点原因,就是kafka使用批量消息提升服务端处理能力。13. 接口实现过程中,恰当使用缓存
Redis分布式缓存,当然有些时候也可以考虑使用本地缓存,如Guava Cache、Caffeine等。使用本地缓存有些缺点,就是无法进行大数据存储,并且应用进程的重启,缓存会失效。14. 接口考虑热点数据隔离性
15. 可变参数配置化,比如红包皮肤切换等