作者:微信小助手
发布时间:2022-02-09T21:52:36
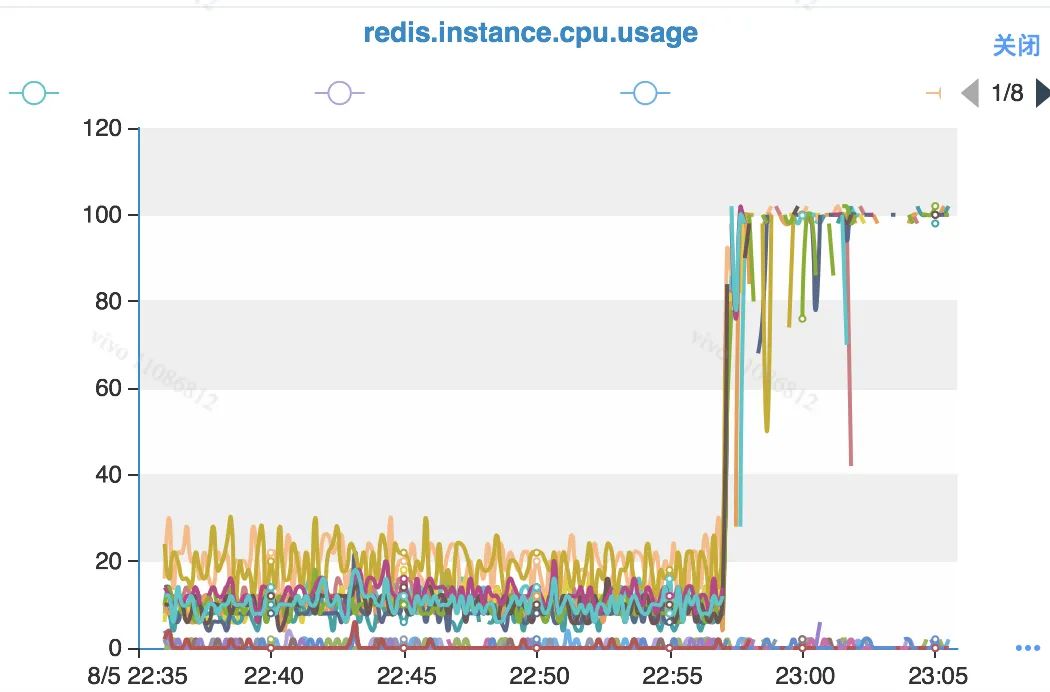
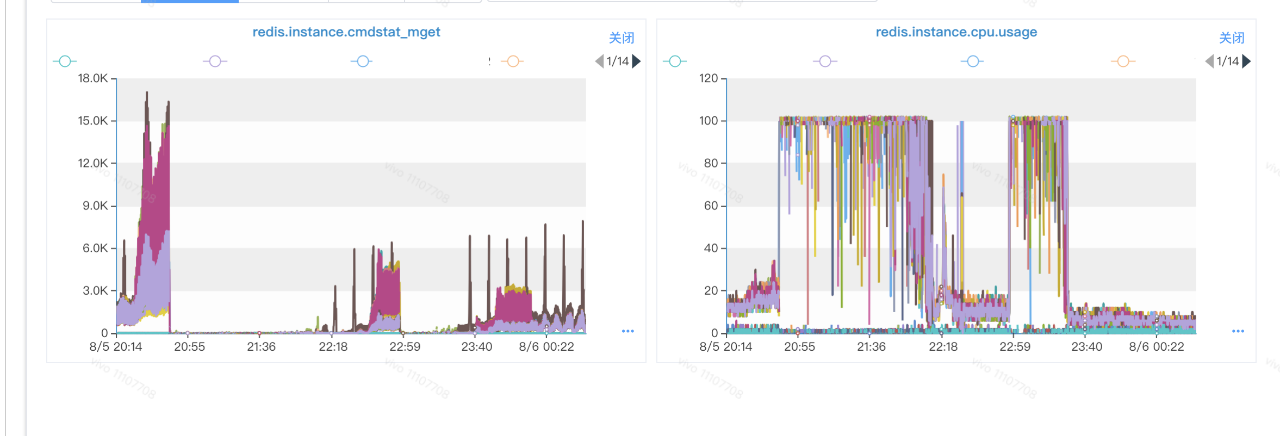
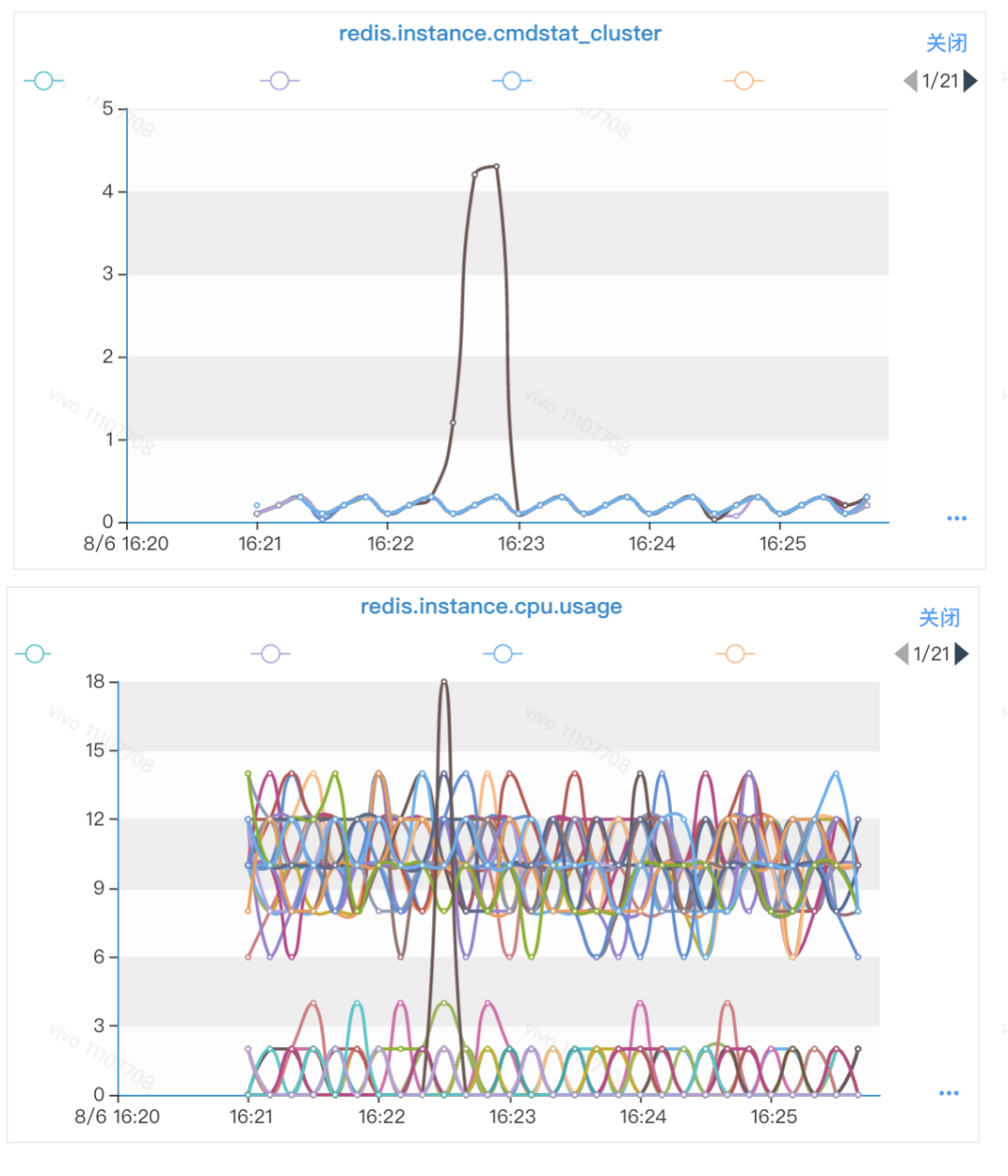
一、背景 在现网环境,一些使用Redis集群的业务随着业务量的上涨,往往需要进行节点扩容操作。 之前有了解到运维同学对一些节点数比较大的Redis集群进行扩容操作后,业务侧反映集群性能下降,具体表现在访问时延增长明显。 某些业务对Redis集群访问时延比较敏感,例如现网环境对模型实时读取,或者一些业务依赖读取Redis集群的同步流程,会影响业务的实时流程时延。业务侧可能无法接受。 为了找到这个问题的根因,我们对某一次的Redis集群迁移操作后的集群性能下降问题进行排查。 1.1 问题描述 这一次具体的Redis集群问题的场景是:某一个Redis集群进行过扩容操作。业务侧使用Hiredis-vip进行Redis集群访问,进行MGET操作。 业务侧感知到访问Redis集群的时延变高。 1.2 现网环境说明 目前现网环境部署的Redis版本多数是3.x或者4.x版本; 业务访问Redis集群的客户端品类繁多,较多的使用Jedis。本次问题排查的业务使用客户端Hiredis-vip进行访问; Redis集群的节点数比较大,规模是100+; 集群之前存在扩容操作。 1.3 观察现象 因为时延变高,我们从几个方面进行排查: 带宽是否打满; CPU是否占用过高; OPS是否很高; 通过简单的监控排查,带宽负载不高。但是发现CPU表现异常: 1.3.1 对比ops和CPU负载 观察业务反馈使用的MGET和CPU负载,我们找到了对应的监控曲线。 从时间上分析,MGET和CPU负载高并没有直接关联。业务侧反馈的是MGET的时延普遍增高。此处看到MGET的OPS和CPU负载是错峰的。 此处可以暂时确定业务请求和CPU负载暂时没有直接关系,但是从曲线上可以看出:在同一个时间轴上,业务请求和cpu负载存在错峰的情况,两者间应该有间接关系。 1.3.2 对比Cluster指令OPS和CPU负载 由于之前有运维侧同事有反馈集群进行过扩容操作,必然存在slot的迁移。 考虑到业务的客户端一般都会使用缓存存放Redis集群的slot拓扑信息,因此怀疑Cluster指令会和CPU负载存在一定联系。 我们找到了当中确实有一些联系: 此处可以明显看到:某个实例在执行Cluster指令的时候,CPU的使用会明显上涨。 根据上述现象,大致可以进行一个简单的聚焦: 业务侧执行MGET,因为一些原因执行了Cluster指令; Cluster指令因为一些原因导致CPU占用较高影响其他操作; 怀疑Cluster指令是性能瓶颈。 同时,引申几个需要关注的问题: 为什么会有较多的Cluster指令被执行? 为什么Cluster指令执行的时候CPU资源比较高? 为什么节点规模大的集群迁移slot操作容易“中招”? 二、问题排查 2.1 Redis热点排查 我们对一台现场出现了CPU负载高的Redis实例使用perf top进行简单的分析: 从上图可以看出来,函数(ClusterReplyMultiBulkSlots)占用的CPU资源高达 51.84%,存在异常。 2.1.1 ClusterReplyMultiBulkSlots实现原理 我们对clusterReplyMultiBulkSlots函数进行分析:

void clusterReplyMultiBulkSlots(client *c) { /* Format: 1) 1) start slot * 2) end slot * 3) 1) master IP * 2) master port * 3) node ID * 4) 1) replica IP * 2) replica port * 3) node ID * ... continued until done */ int num_masters = 0; void *slot_replylen = addDeferredMultiBulkLength(c); dictEntry *de; dictIterator *di = dictGetSafeIterator(server.cluster->nodes); while((de = dictNext(di)) != NULL) { /*注意:此处是对当前Redis节点记录的集群所有主节点都进行了遍历*/ clusterNode *node = dictGetVal(de); int j = 0, start = -1; /* Skip slaves (that are iterated when producing the output of their * master) and masters not serving any slot. */ /*跳过备节点。备节点的信息会从主节点侧获取。*/ if (!nodeIsMaster(node) || node->numslots == 0) continue; for (j = 0; j < CLUSTER_SLOTS; j++) { /*注意:此处是对当前节点中记录的所有slot进行了遍历*/ int bit, i; /*确认当前节点是不是占有循环终端的slot*/ if ((bit = clusterNodeGetSlotBit(node,j)) != 0) { if (start == -1) start = j; } /*简单分析,此处的逻辑大概就是找出连续的区间,是的话放到返回中;不是的话继续往下递归slot。 如果是开始的话,开始一个连续区间,直到和当前的不连续。*/ if (start != -1 && (!bit || j == CLUSTER_SLOTS-1)) { int nested_elements = 3; /* slots (2) + master addr (1). */ void *nested_replylen = addDeferredMultiBulkLength(c); if (bit && j == CLUSTER_SLOTS-1) j++; /* If slot exists in output map, add to it's list. * else, create a new output map for this slot */ if (start == j-1) { addReplyLongLong(c, start); /* only one slot; low==high */ addReplyLongLong(c, start); } else