作者:微信小助手
发布时间:2022-01-25T14:38:55
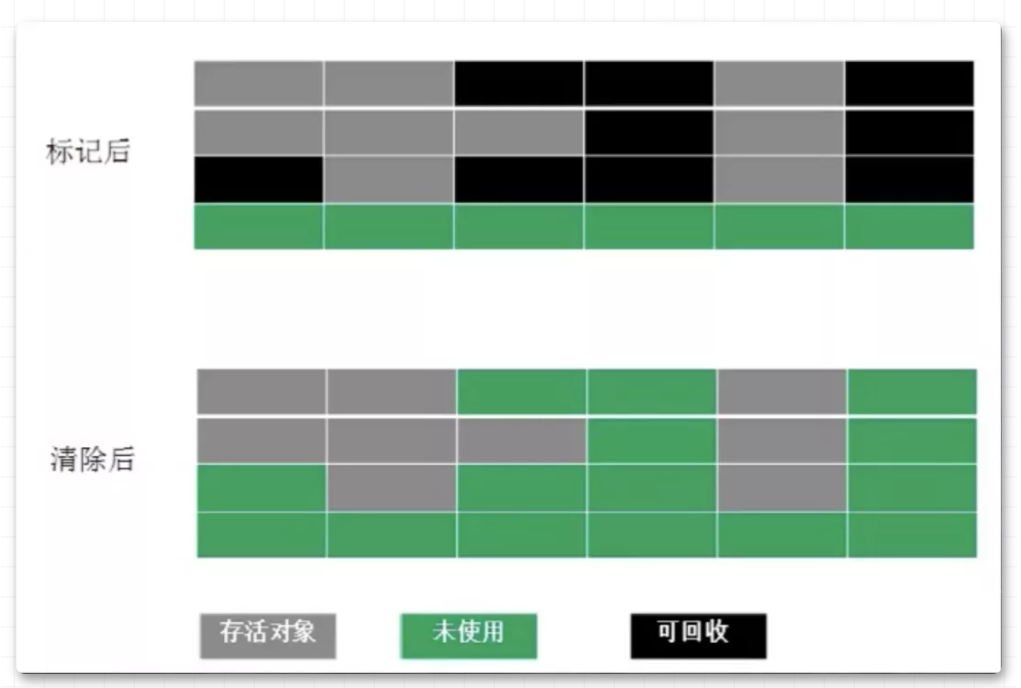
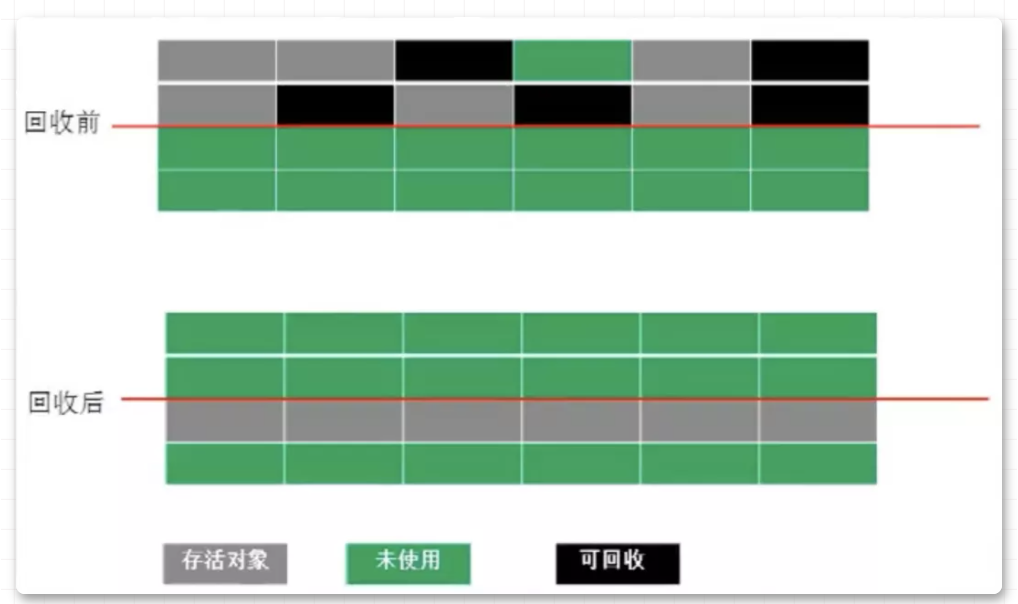
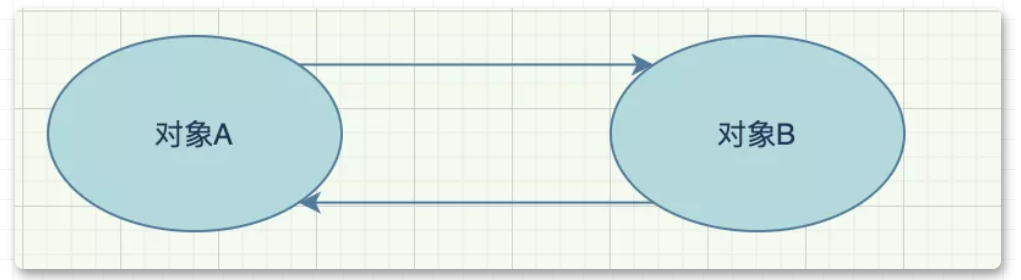
大家好,我是飘渺。 这张图就是一个 JVM 运行时数据图, 紫色区域代表是线程共享的区域 ,JAVA 程序在运行的过程中会把他管理的内存划分为若干个不同的数据区域, 每一块儿的数据区域所负责的功能都是不同的,他们也有不同的创建时间和销毁时间 。 1.程序计数器 2.虚拟机栈 3.本地方法栈 本地方法栈的概念很好理解,我们知道,java底层用了很多c的代码去实现,而其调用c端的方法上都会有native,代表本地方法服务,而本地方法栈就是为其服务的。 4.堆 堆可以说是jvm中最大的一块儿内存区域了,它是所有线程共享的,不管你是初学者还是资深开发,多少都会听说过堆,毕竟几乎所有的对象都会在堆中分配。 5.方法区 6.直接内存 就是给对象添加一个计数器 当计数器的值为0的时候,那么该对象就是垃圾了 这种方案的原理很简单,而且判定的效率也非常高,但是却可能会有其他的额外情况需要考虑。 比如两个对象循环引用 ,a 对象引用了 b 对象,b 对象也引用了 a 对象,a、b 对象却没有再被其他对象所引用了,其实正常来说这两个对象已经是垃圾了,因为没有其他对象在使用了,但是计数器内的数值却不是 0,所以引用计数算法就无法回收它们。这种算法是比较直接的找到垃圾 ,然后去回收,也被称为"直接垃圾收集"。 这也是 JVM 默认使用 的寻找垃圾算法它的原理就是定义了一系列的根,我们把它称为 "GC Roots" ,从 "GC Roots" 开始往下进行搜索,走过的路径我们把它称为 "引用链" ,当一个对象到 "GC Roots" 之间没有任何引用链相连时,那么这个对象就可以被当做垃圾回收了。 如图, 根可达算法 就可以 避免 计数器算法不好解决的 循环引用问题 ,Object 6、Object 7、Object 8彼此之前有引用关系,但是 没有与"GC Roots" 相连,那么就会被当做垃圾所回收 。 在java中,有固定的GC Roots 对象 和 不固定的临时GC Roots对象 : 固定的GC Roots: 临时GC Roots: "Object o = new Object()" 就是一种强引用关系,这也是我们在代码中最常用的一种引用关系。无论任何情况下,只要强引用关系还存在,垃圾回收器就不会回收掉被引用的对象。 当内存空间不足时,就会回收软引用对象。 软引用用来描述那些有用但是没必要的对象。 弱引用要比软引用更弱一点,它 只能够存活到下次垃圾回收之前 。也就是说,垃圾回收器开始工作,会回收掉所有只被弱引用关联的对象。 在 ThreadLocal 中就使用了弱引用来防止内存泄漏。 虚引用是最弱的一种引用关系,它的唯一作用是用来作为一种通知。如零拷贝(Zero Copy),开辟了堆外内存,虚引用在这里使用,会将这部分信息存储到一个队列中,以便于后续对堆外内存的回收管理。 大多数的垃圾回收器都遵循了分代收集的理论进行设计,它建立在两个分代假说之上: 这两种假说的设计原则都是相同的:垃圾收集器 应该将jvm划分出不同的区域 ,把那些较难回收的对象放在一起(一般指老年代),这个区域的垃圾回收频率就可以降低,减少垃圾回收的开销。剩下的区域(一般指新生代)可以用较高的频率去回收,并且只需要去关心那些存活的对象,也不用标记出需要回收的垃圾,这样就能够以较低的代价去完成垃圾回收。 由于跨代引用是很少的,所以我们不应该为了少量的跨代引用去扫描整个老年代的数据,只需要在新生代对象建立一个 记忆集 来记录引用信息。记忆集: 将老年代分为若干个小块,每块区域中有 N 个对象 ,在对象引用信息发生变动的时候来维护记忆集数据的准确性,这样每次发生了 "Minor GC" 的时候只需要将记忆集中的对象添加到 "GC Roots" 中就可以了。 总共有三种 这种算法的实现是很简单的,有两种方式 这种算法有两个缺点 1.随着对象越来越多,那么所需要消耗的时间就会越来越多 2.标记清除后会导致碎片化,如果有大对象分配很有可能分配不下而出发另一次的垃圾收集动作 2.标记复制算法 这种算法解决了第一种算法碎片化的问题。就是 开辟两块完全相同的区域 ,对象只在其中一篇区域内分配,然后 标记 出那些 存活的对象,按顺序整体移到另外一个空间 ,如下图,可以看到回收后的对象是排列有序的,这种操作只需要移动指针就可以完成,效率很高, 之后就回收移除前的空间 。 这种算法的缺点也是很明显的 浪费过多的内存,使现有的 可用空间变为 原先的 一半 3.标记整理算法
马上过完年又到了面试的高峰期,而一般情况下JVM在面试中是跑不掉的,所以特意给大家整理了一份JVM的常见面试题,刚好趁着过年的时候卷起来。话不多说,咱们直接开卷。1.说说 JVM 内存区域
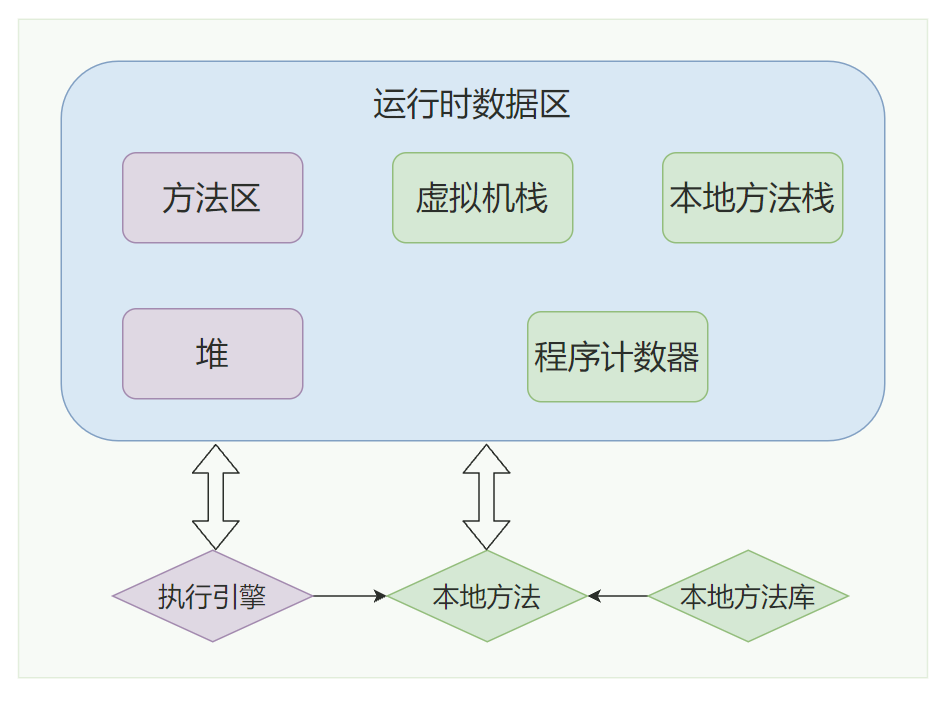
2.垃圾对象是怎么找到的?
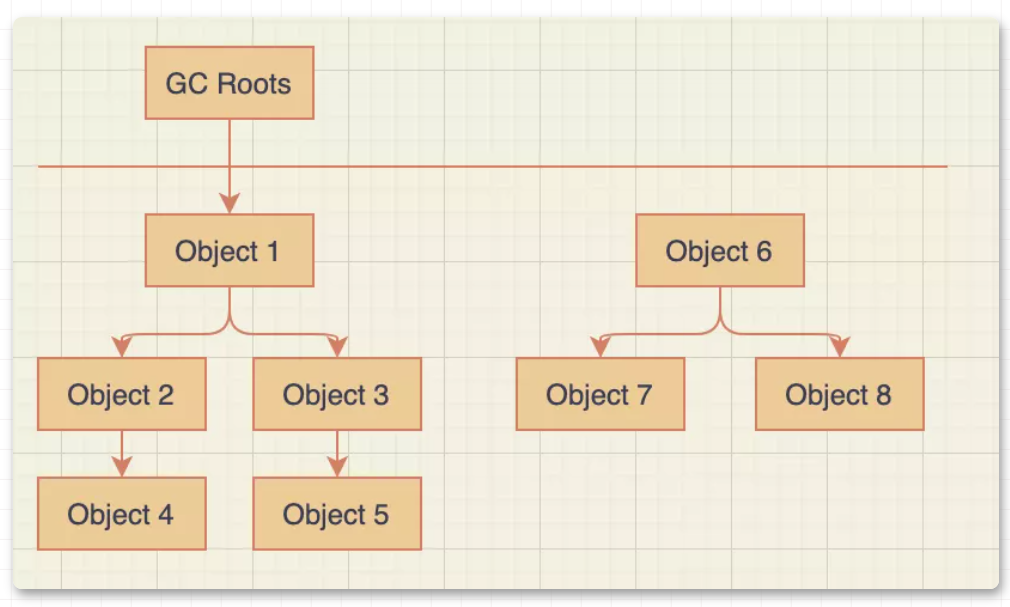
3.GC Roots 有哪些?
4.java 有哪四种引用类型?
// 软引用
SoftReference<String> softRef = new SoftReference<String>(str);
WeakReference<String> weakRef = new WeakReference<String>(str);
5.说一说分代收集理论
6.垃圾收集算法有哪些?