作者:微信小助手
发布时间:2021-11-17T16:31:27
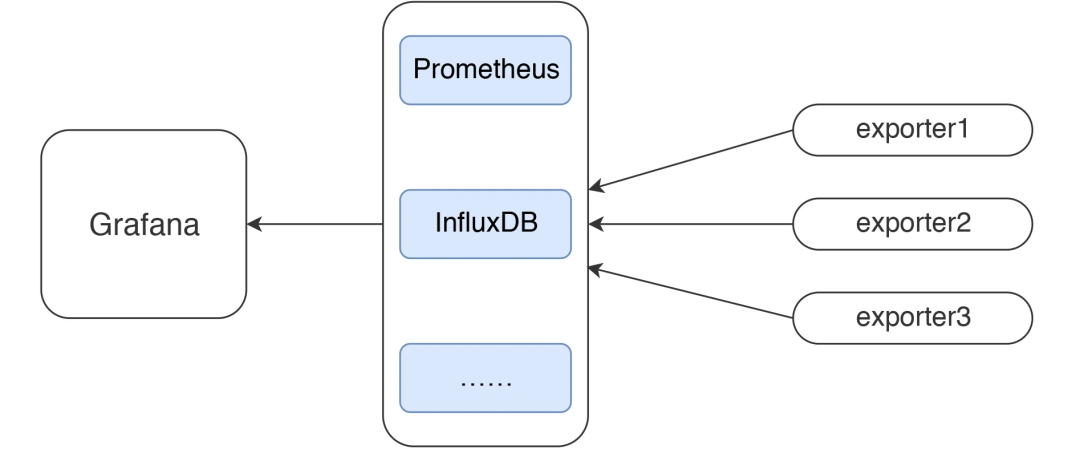
在本文中,我将把几个常用的监控部分给梳理一下。前面我们提到过,在性能监控图谱中,有操作系统、应用服务器、中间件、队列、缓存、数据库、网络、前端、负载均衡、Web 服务器、存储、代码等很多需要监控的点。显然这些监控点不能在一个专栏中全部覆盖并一一细化,我只能找最常用的几个,做些逻辑思路的说明,同时也把具体的实现描述出来。如果你遇到了其他的组件,也需要一一实现这些监控。 在本篇中,主要想说明白下图的这个监控逻辑。 这应该是现在最流行的一套监控逻辑了吧。我今天把常见的使用 Grafana、Prometheus、InfluxDB、Exporters 的数据展示方式说一下,如果你刚进入性能测试领域,也能有一个感性的认识。 有测试工具,有监控工具,才能做后续的性能分析和瓶颈定位,所以有必要把这些工具的逻辑跟你摆一摆。 所有做性能的人都应该知道一点,不管数据以什么样的形式展示,最要紧的还是看数据的来源和含义,以便做出正确的判断。 我先说明一下 JMeter 和 node_exporter 到 Grafana 的数据展示逻辑。至于其他的 Exporter,我就不再解释这个逻辑了,只说监控分析的部分。 整理结果时比较浪费时间。 在 GUI 用插件看曲线,做高并发时并不现实。