作者:微信小助手
发布时间:2021-04-04T17:55:12
(给ImportNew加星标,提高Java技能)
上一篇文章中 谈到了《吃透系列》的讲解思路:先找到每个技术栈最本质的东西,然后以此为出发点,逐渐延伸出其他核心知识。
所以,整个系列侧重于思考力的训练,不仅仅是讲清楚 What,而是更关注 Why 和 How,以帮助大家构建出牢固的知识体系。
回到正文,这是技术系列《吃透 MQ》的开篇。本文主要讲解 MQ 的通用知识,让大家先弄明白:如果让你来设计一个 MQ,该如何下手?需要考虑哪些问题?又有哪些技术挑战?
有了这个基础后,我相信后面几篇文章再讲 Kafka 和 RocketMQ 这两种具体的消息中间件时,大家能很快地抓住主脉络,同时分辨出它们各自的特点。
对于 MQ 来说,不管是 RocketMQ、Kafka 还是其他消息队列,它们的本质都是:一发一存一消费。下面我们以这个本质作为根,一起由浅入深地聊聊 MQ。
01 从 MQ 的本质说起
将 MQ 掰开了揉碎了来看,都是「一发一存一消费」,再直白点就是一个「转发器」。
生产者先将消息投递一个叫做「队列」的容器中,然后再从这个容器中取出消息,最后再转发给消费者,仅此而已。
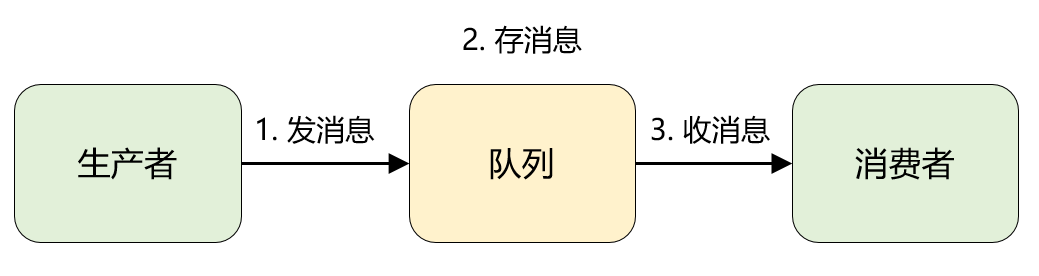
1、消息:就是要传输的数据,可以是最简单的文本字符串,也可以是自定义的复杂格式(只要能按预定格式解析出来即可)。
2、队列:大家应该再熟悉不过了,是一种先进先出数据结构。它是存放消息的容器,消息从队尾入队,从队头出队,入队即发消息的过程,出队即收消息的过程。
02 原始模型的进化
再看今天我们最常用的消息队列产品(RocketMQ、Kafka 等等),你会发现:它们都在最原始的消息模型上做了扩展,同时提出了一些新名词,比如:主题(topic)、分区(partition)、队列(queue)等等。
要彻底理解这些五花八门的新概念,我们化繁为简,先从消息模型的演进说起(道理好比:架构从来不是设计出来的,而是演进而来的)
2.1 队列模型
最初的消息队列就是上一节讲的原始模型,它是一个严格意义上的队列(Queue)。消息按照什么顺序写进去,就按照什么顺序读出来。不过,队列没有 “读” 这个操作,读就是出队,从队头中 “删除” 这个消息。
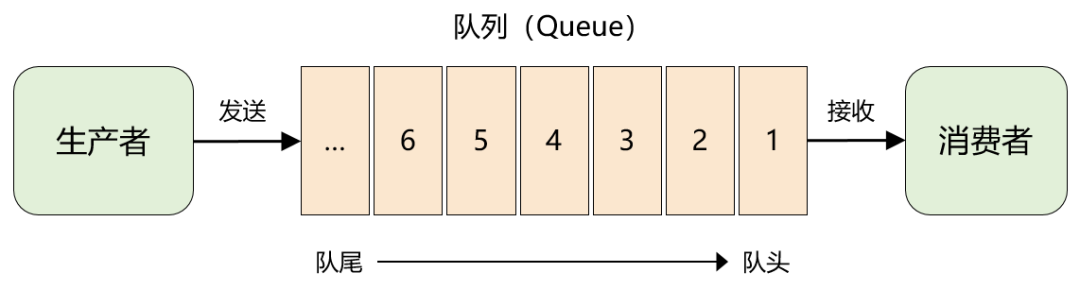
这便是队列模型:它允许多个生产者往同一个队列发送消息。但是,如果有多个消费者,实际上是竞争的关系,也就是一条消息只能被其中一个消费者接收到,读完即被删除。
2.2 发布-订阅模型
如果需要将一份消息数据分发给多个消费者,并且每个消费者都要求收到全量的消息。很显然,队列模型无法满足这个需求。
一个可行的方案是:为每个消费者创建一个单独的队列,让生产者发送多份。这种做法比较笨,而且同一份数据会被复制多份,也很浪费空间。
为了解决这个问题,就演化出了另外一种消息模型:发布-订阅模型。
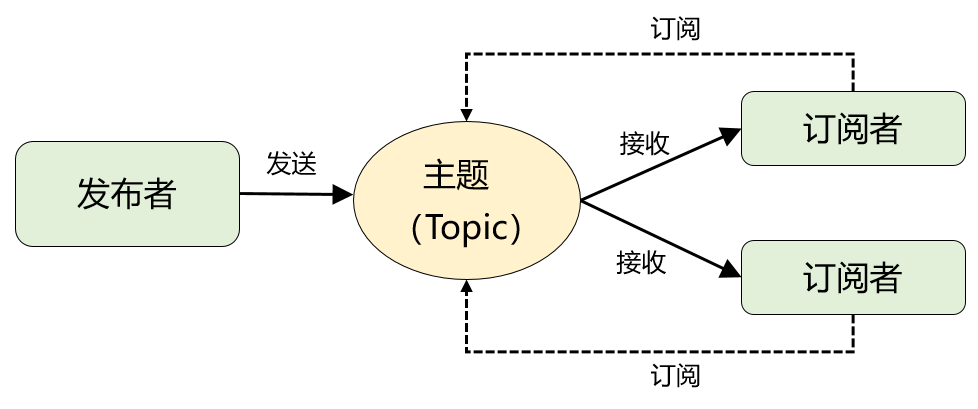
在发布-订阅模型中,存放消息的容器变成了 “主题”,订阅者在接收消息之前需要先 “订阅主题”。最终,每个订阅者都可以收到同一个主题的全量消息。
仔细对比下它和 “队列模式” 的异同:生产者就是发布者,队列就是主题,消费者就是订阅者,无本质区别。唯一的不同点在于:一份消息数据是否可以被多次消费。
2.3 小结
最后做个小结,上面两种模型说白了就是:单播和广播的区别。而且,当发布-订阅模型中只有 1 个订阅者时,它和队列模型就一样了,因此在功能上是完全兼容队列模型的。
这也解释了为什么现代主流的 RocketMQ、Kafka 都是直接基于发布-订阅模型实现的?此外,RabbitMQ 中之所以有一个 Exchange 模块?其实也是为了解决消息的投递问题,可以变相实现发布-订阅模型。
包括大家接触到的 “消费组”、“集群消费”、“广播消费” 这些概念,都和上面这两种模型相关,以及在应用层面大家最常见的情形:组间广播、组内单播,也属于此范畴。
所以,先掌握一些共性的理论,对于大家再去学习各个消息中间件的具体实现原理时,其实能更好地抓住本质,分清概念。
03 透过模型看 MQ 的应用场景
目前,MQ 的应用场景非常多,大家能倒背如流的是:系统解耦、异步通信和流量削峰。除此之外,还有延迟通知、最终一致性保证、顺序消息、流式处理等等。
那到底是先有消息模型,还是先有应用场景呢?答案肯定是:先有应用场景(也就是先有问题),再有消息模型,因为消息模型只是解决方案的抽象而已。
MQ 经过 30 多年的发展,能从最原始的队列模型发展到今天百花齐放的各种消息中间件(平台级的解决方案),我觉得万变不离其宗,还是得益于:消息模型的适配性很广。
我们试着重新理解下消息队列的模型。它其实解决的是:生产者和消费者的通信问题。那它对比 RPC 有什么联系和区别呢?