作者:微信小助手
发布时间:2020-11-18T19:10:10


作者 | 悟空聊架构
来源 | 悟空聊架构(ID:PassJava666)
本篇主要内容
这篇主要是理论 + 实践相结合。实践部分涉及到如何把链路追踪组件 Sleuth + Zipkin 加到我的 Spring Cloud 《佳必过》开源项目上。
本篇知识点:
-
链路追踪基本原理 -
如何在项目中轻松加入链路追踪中间件 -
如何使用链路追踪排查问题
一、为什么要用链路追踪?
1.1 因:拆分服务单元
微服务架构其实是一个分布式的架构,按照业务划分成了多个服务单元。
由于服务单元的数量是很多的,有可能几千个,而且业务也会更复杂,如果出现了错误和异常,很难去定位。
1.2 因:逻辑复杂
比如一个请求需要调用多个服务才能完成整个业务闭环,而内部服务的代码逻辑和业务逻辑比较复杂,假如某个服务出现了问题,是难以快速确定那个服务出问题的。
1.3 果:快速定位
而如果我们加上了分布式链路追踪,去跟踪一个请求有哪些服务参与其中,参与的顺序是怎样的,这样我们就知道了每个请求的详细经过,即使出了问题也能快速定位。
二、链路追踪的核心
链路追踪组件有 Twitter 的可视化链路追踪组件 Zipkin、Google 的 Dapper、阿里的 Eagleeye 等,而 Sleuth 是 Spring Cloud 的组件。Spring Cloud Sleuth 借鉴了 Dapper 的术语。
本文主要讲解 Sleuth + Zipkin 结合使用来更好地实现链路追踪。
为什么能够进行整条链路的追踪?其实就是一个 Trace ID 将 一连串的 Span 信息连起来了。根据 Span 记录的信息再进行整合就可以获取整条链路的信息。下面是链路追踪的核心概念:
2.1 Span(跨度)
-
大白话:远程调用和 Span
一对一。 -
基本的工作单元,每次发送一个远程调用服务就会产生一个 Span。
-
Span 是一个 64 位的唯一 ID。
-
通过计算 Span 的开始和结束时间,就可以统计每个服务调用所花费的时间。
2.2 Trace(跟踪)
-
大白话:一个 Trace 对应多个 Span,
一对多。 -
它由一系列 Span 组成,树状结构。
-
64 位唯一 ID。
-
每次客户端访问微服务系统的 API 接口,可能中间会调用多个微服务,每次调用都会产生一个新的 Span,而多个 Span 组成了 Trace
2.3 Annotation(注解)
链路追踪系统定义了一些核心注解,用来定义一个请求的开始和结束,注意是微服务之间的请求,而不是浏览器或手机等设备。注解包括:
-
cs- Client Sent:客户端发送一个请求,描述了这个请求调用的Span的开始时间。注意:这里的客户端指的是微服务的调用者,不是我们理解的浏览器或手机等客户端。 -
sr- Server Received:服务端获得请求并准备开始处理它,如果将其sr减去cs时间戳,即可得到网络传输时间。 -
ss- Server Sent:服务端发送响应,会记录请求处理完成的时间,ss时间戳减去sr时间戳,即可得到服务器请求的时间。 -
cr- Client Received:客户端接收响应,Span 的结束时间,如果cr的时间戳减去cs时间戳,即可得到一次微服务调用所消耗的时间,也就是一个Span的消耗的总时间。
2.4 链路追踪原理
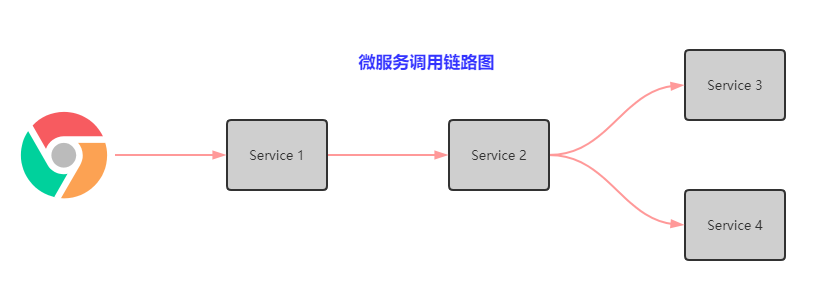
假定三个微服务调用的链路如下图所示:Service 1 调用 Service 2,Service 2 调用 Service 3 和 Service 4。
那么链路追踪会在每个服务调用的时候加上 Trace ID 和 Span ID。如下图所示:
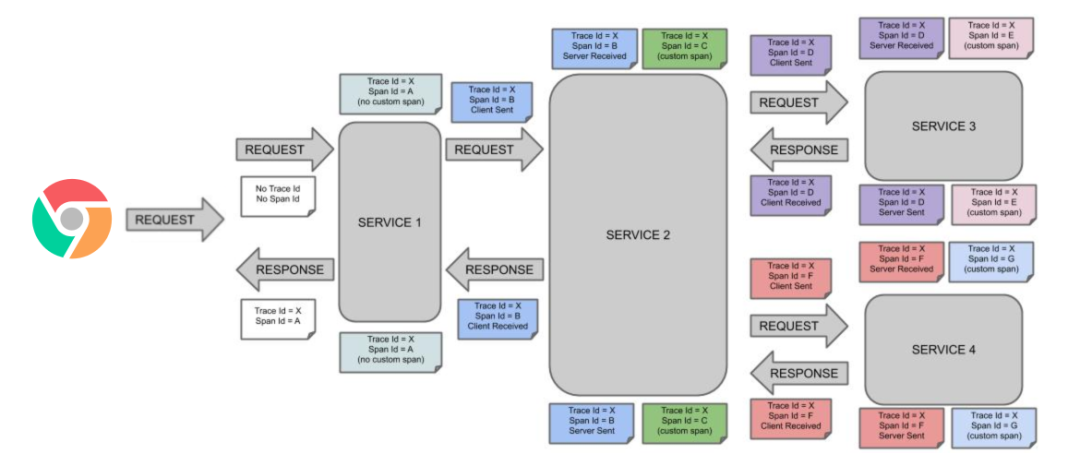
大白话解释:
-
大家注意上面的颜色,相同颜色的代表是同一个 Span ID,说明是链路追踪中的一个节点。
-
第一步:客户端调用
Service 1,生成一个Request,Trace ID和Span ID为空,那个时候请求还没有到Service 1。 -
第二步:请求到达
Service 1,记录了 Trace ID = X,Span ID 等于 A。 -
第三步:
Service 1发送请求给Service 2,Span ID 等于 B,被称作 Client Sent,即客户端发送一个请求。 -
第四步:请求到达
Service 2,Span ID 等于 B,Trace ID 不会改变,被称作 Server Received,即服务端获得请求并准备开始处理它。 -
第五步:
Service 2开始处理这个请求,处理完之后,Trace ID 不变,Span ID = C。 -
第六步:
Service 2开始发送这个请求给Service 3,Trace ID 不变,Span ID = D,被称作 Client Sent,即客户端发送一个请求。 -
第七步: