作者:微信小助手
发布时间:2023-08-11T15:20:19
Elasticsearch 是一个实时的分布式搜索与分析引擎,在使用过程中,有一些典型的使用场景,比如分页、遍历等。 在使用关系型数据库中,我们被告知要注意甚至被明确禁止使用深度分页,同理,在 Elasticsearch 中,也应该尽量避免使用深度分页。 这篇文章主要介绍 Elasticsearch 中分页相关内容! 在ES中,分页查询默认返回最顶端的10条匹配hits。 如果需要分页,需要使用from和size参数。 一个基本的ES查询语句是这样的: 上面的查询表示从搜索结果中取第100条开始的10条数据。 那么,这个查询语句在ES集群内部是怎么执行的呢? 在ES中,搜索一般包括两个阶段,query 和 fetch 阶段,可以简单的理解,query 阶段确定要取哪些doc,fetch 阶段取出具体的 doc。 Query阶段 如上图所示,描述了一次搜索请求的 query 阶段:· 在上面的例子中,coordinating node 拿到 另外,各个分片返回给 coordinating node 的数据用于选出前 coordinating node 计算好自己的优先级队列后,query 阶段结束,进入 fetch 阶段。 Fetch阶段 query 阶段知道了要取哪些数据,但是并没有取具体的数据,这就是 fetch 阶段要做的。 上图展示了 fetch 过程: coordinating node 的优先级队列里有 需要取的数据可能在不同分片,也可能在同一分片,coordinating node 使用 multi-get 来避免多次去同一分片取数据,从而提高性能。 这种方式请求深度分页是有问题的: 我们可以假设在一个有 5 个主分片的索引中搜索。当我们请求结果的第一页(结果从 1 到 10 ),每一个分片产生前 10 的结果,并且返回给 协调节点 ,协调节点对 50 个结果排序得到全部结果的前 10 个。 现在假设我们请求第 1000 页—结果从 10001 到 10010 。所有都以相同的方式工作除了每个分片不得不产生前10010个结果以外。然后协调节点对全部 50050 个结果排序最后丢弃掉这些结果中的 50040 个结果。 对结果排序的成本随分页的深度成指数上升。 注意1: size的大小不能超过 如果搜索size大于10000,需要设置From/Size参数
POST /my_index/my_type/_search
{
"query": { "match_all": {}},
"from": 100,
"size": 10
}
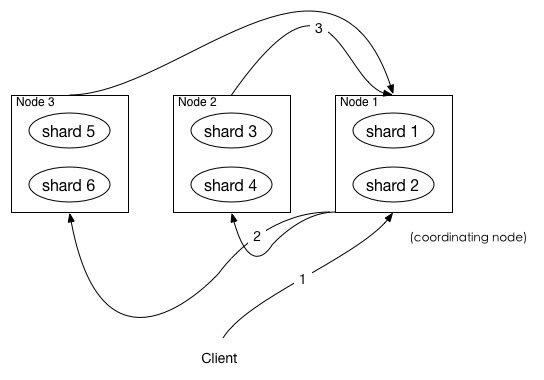
from + size的优先级队列用来存结果,我们管 node1 叫 coordinating node。
from + size 的优先级队列里,可以把优先级队列理解为一个包含
top N结果的列表。
(from + size) * 6条数据,然后合并并排序后选择前面的from + size条数据存到优先级队列,以便 fetch 阶段使用。from + size条数据,所以,只需要返回唯一标记 doc 的_id以及用于排序的_score即可,这样也可以保证返回的数据量足够小。
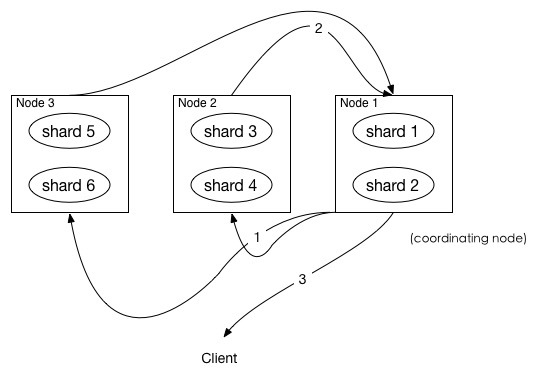
_id取到数据详情,然后返回给 coordinating node。
from + size 个_doc _id,但是,在 fetch 阶段,并不需要取回所有数据,在上面的例子中,前100条数据是不需要取的,只需要取优先级队列里的第101到110条数据即可。index.max_result_window这个参数的设置,默认为10000。i