作者:微信小助手
发布时间:2022-09-17T09:02:06
vivo官网商城开发团队 - Zhou Longjian
一、背景
随着O2O线上线下业务的不断扩展,电商平台也在逐步完善交易侧相关的产品功能。在最近的需求版本中,业务方为进一步提升用户的使用体验,规划了取货码生成及订单核销相关逻辑,目的是让线上的用户在付完款之后能够到店取货或者安排导购派送。
日常生活中,我们对取货码、核销这类功能使用的经历大部分都来自:看电影前取票、吃饭后出示券码、快递柜取包裹等等,它们都有一些类似的特点,比如:
取货码长度相对较短,比起动辄十几二十位订单号,几位的数字码更方便记忆和输入;
除了数字取货码,还提供二维码,方便终端进行扫描并核销。
取货码使用起很简单,然而像“冰山”一样,隐藏在简单外表下面却需要严谨的设计和细致的逻辑,可以说麻雀虽小五脏俱全。本文介绍的设计也比较有趣,而且按此思路可以实现市面上大多数核销类券码的生成,同时也能满足业务的SaaS化,算是一个相对通用的能力,在此把整个设计分享给大家。

(图片来源:pixabay.com)
二、简单系统的单表业务
如果业务的体量不大,店铺流量比较小,未形成平台的规模,比如给个体经营者使用的系统。那么取货码或券码的实现就比较简单,跟订单共享一张大横表或者使用扩展表跟订单进行关联就行了,这个阶段也无需做过度设计。
表的设计如下图:
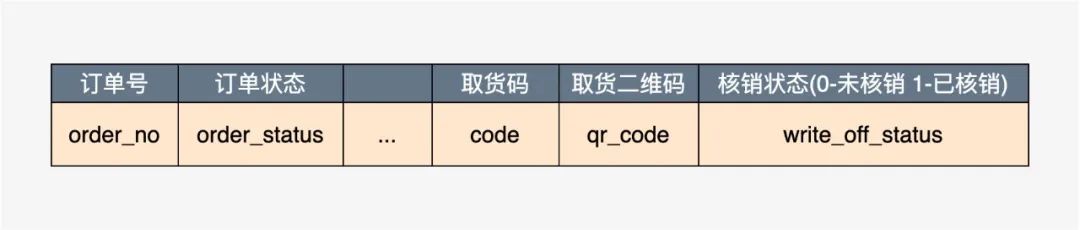
不过需要注意的是一般订单号都是比较长的,通常都在十几二十位(当然也有比较短的订单号,如果订单号比较短,取货码也可采用订单号)我们假设订单号18位,取货码8位,即订单号的取值范围远大于取货码,那么在订单号的生命周期内,取货码是有很大几率存在重复的。解决起来相对简单,我们只需要保证在任意条件下,未核销状态的数字码不重复即可,也即已核销的数字码可以回收利用。
那么取货码的生成逻辑就很清晰了,下面用伪代码模拟真实的实现逻辑:
伪代码实现
for (;;) {step1 获取随机码:String code = this.getRandomCode();step2 执行SQL:SELECT COUNT(1) FROM order_main WHERE code = ${code} AND write_off_status = 0;step3 判断是否可以插入:if ( count > 0) { continue; }step4 执行数据写入:UPDATE order_main SET code = ${code}, qr_code = ${qrCode}, write_off_status = 0 WHERE order_no = ${orderNo}}
*注意:这里step2和step4不是原子操作,存在并发问题,实际应用中最好使用分布式锁,把操作锁住。
三、 复杂平台的分库分表业务
通过简单的单表设计,我们能管窥一斑,了解取货码大致的实现逻辑。不过我们在把简单方案往大型项目上进行落地的时候,就需要考虑很多方面,设计也需要更精巧。SaaS化的电商平台会比简单的单表业务复杂很多,重点体现在:
SaaS 产品涉及的店铺很多且订单量大,需要设计大容量存储,所以订单表基本使用分库分表,显然作为订单附属的取货码表也得使用相同的策略;
B端和C端用户的体验非常重要,服务端接口的设计需要充分考虑鲁棒性,完善最基本的重试及容错能力;
不同业务方对于取货码的要求可能不太一样,取货码的设计需要具有通用性以及个性化的配置属性。
3.1 详细设计
取货码表的设计推荐使用和订单一致的分库分表策略,好处是:
和订单一样,支撑海量订单行的存储;
方便利用同样的分库分表因子进行查询(例如:open_id、member_id)。
在考虑落地实现上,我们遇到了第一个讨论的点,那就是取货码是做到“门店唯一”还是“全局唯一”?
3.2 门店唯一方案
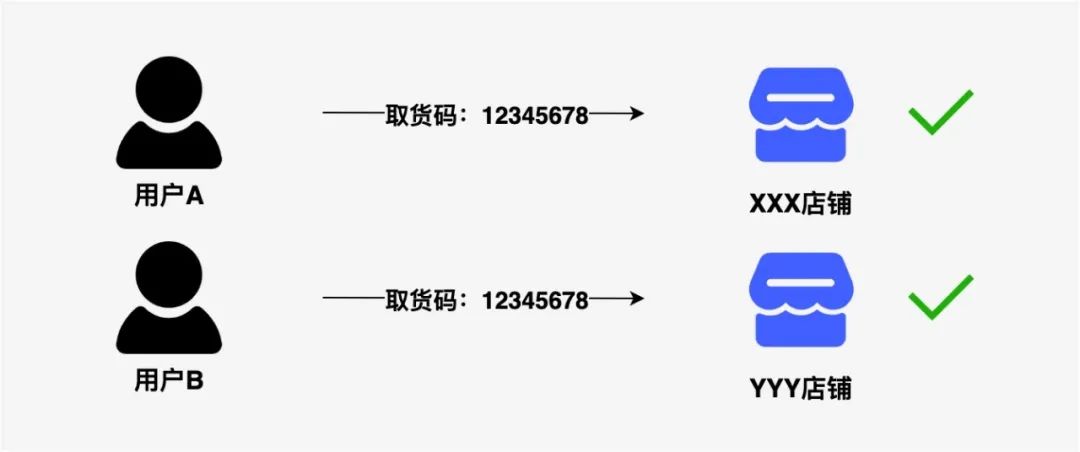
刚开始考虑使用类似饭馆取餐码类似的逻辑,保证取货码在各自门店保持唯一就行了。类似如下图交互,图中用户A和用户B持有相同的取货码,用户A、B分别去他们对应的店铺完成核销,整个交易过程就结束了。但是这得保证用户A和B能正确地在各自订单归属的店铺完成核销,显然这个方案是带有风险的!
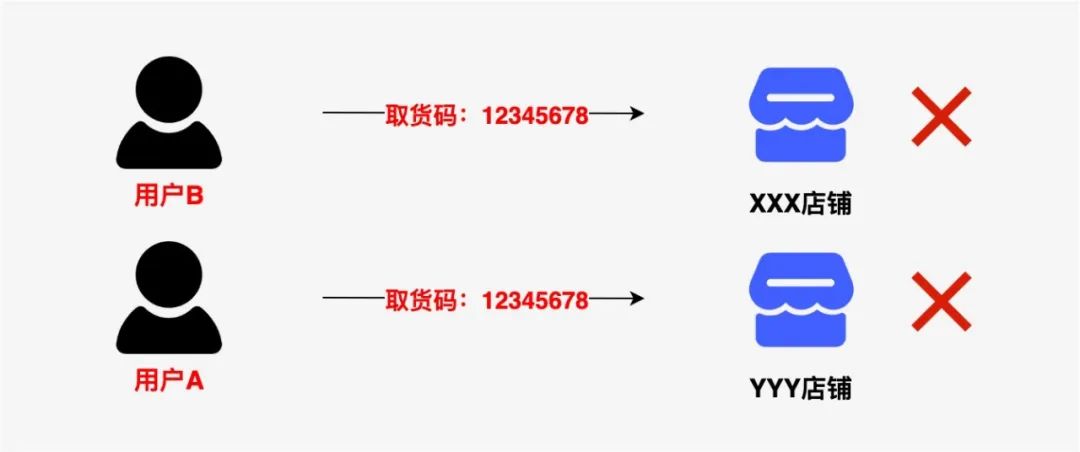
下图所示的这种情况下,用户A、B也能正常核销,不过串单了,原本属于用户A的订单被用户B核销了。这种问题出现的本质原因在于纯粹的数字码无法带有用户的标识,虽然可以在核销前做人为的核验身份来避免,但依然属于高风险的系统设计,所以门店唯一方案不可取!
3.3 全局唯一方案
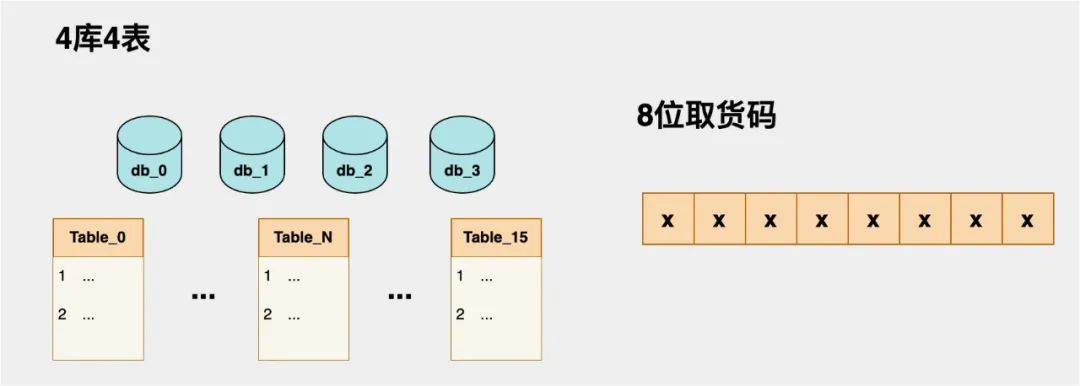
全局唯一方案风险小,但实现难度稍高一点。核心问题在于如何判定随机生成的取货码是全局唯一的,当然如果系统本身依赖ES这类存储介质,可以在插入前先查询ES,不过查询和写入ES对于实时性接口来说稍微有点重,没有直接查库表来得直接。假设某业务方分成了4个库4张表,总计16表,取货码的长度确定为8位,那如何在多库多表的Mysql中查询并保证全局唯一呢?遍历表的方式肯定不可取!
为解决上述的疑问,我们在设计的时候可以在取货码的编排上做点文章,如下步骤做具体详解:
步骤①: 可以将8位的取货码分成两个区域,“随机码区域”+“库表位置”,下图示例:
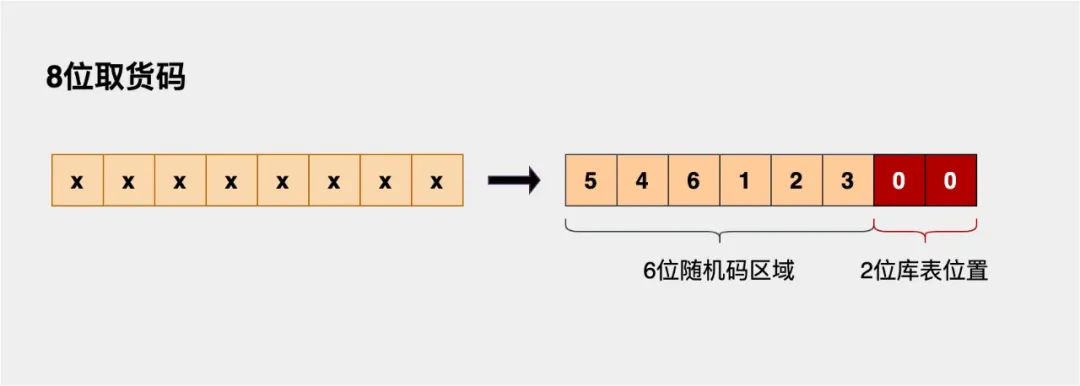
步骤②: 随机码区域暂不介绍,我们来看下2位库表如何映射到4库4表组成的16张表中。
这里也有两套方案:
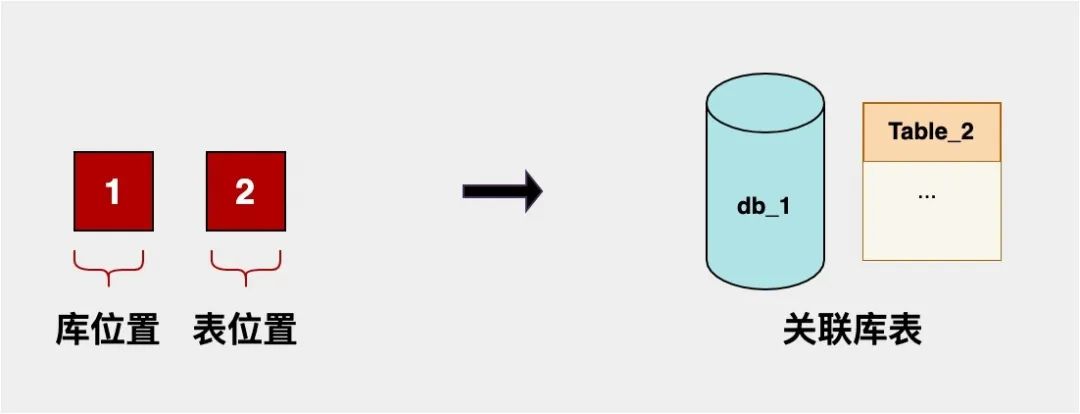
【方案一】可以选择2位库表的首位作为库编号,末位作为表编号。好处是映射较为简单,但是容量不够大,如果分的库或表>9,扩展就会有点麻烦。如下图,我们把末尾“12”逻辑映射到了“1库的编号为2的表”;
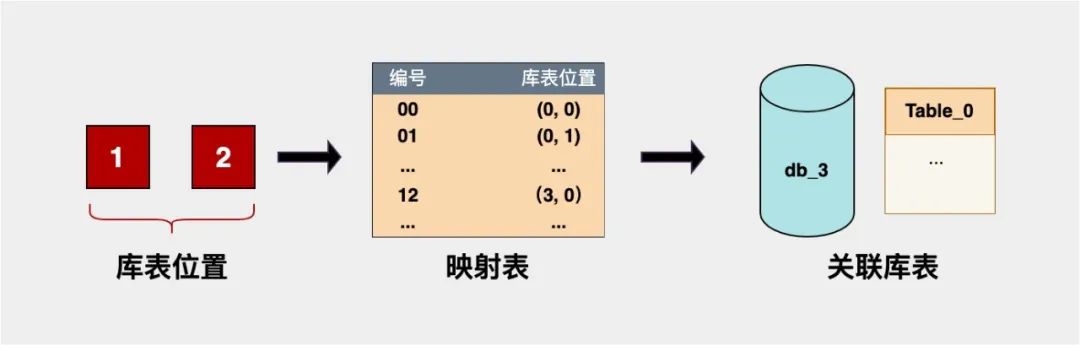
【方案二】将4库4表二维结构转成一维,以0为初始值进行递增,(0库, 0表) → 00, (0库, 1表) → 01... , (3库, 3表) → 15。好处是容量变大了,最大支持99张表,不受库或表单一条件的限制,缺点就是映射逻辑写起来麻烦点,不过这不是问题。
取货码经过简单编排,我们完成了取货码的到库表的映射逻辑,解决了取货码存取的问题。其实仔细想想,关于全局唯一的问题其实也解决掉了,我们只要保证前6位随机码在单表里保证唯一即可,理论上支持单表在未核销状态下范围为:000000 ~ 999999条记录,容量是足够的。关键我们把多库多表的查询就简化成了只跑一个SQL,效率大大提升。
3.4 方案落地遇到的问题
既然本篇是介绍SaaS化的完整方案,在落地的时候或多或少会遇到一些问题,这边介绍三个实际遇到的典型问题,并给出一些解决方案:
【问题一】使用Math.random()生成的6位随机码和表里的重复了,如何处理?
【解决】其实重复的情况有两种:
可能是表里已经存在数字相同未核销的取货码;
另外一种情况就是别的事务在正在操作,正好有个分布式事务锁住了一样的数字码(概率很低,但是是有可能的)。
这两种情况的出现就需要我们进行优雅地重试了!大致思路如下伪代码:
// step1 根据分库分表因子获取库表编号,userCode-用户编号、tenantId-租户编号String suffix = getCodeSuffix(userCode, tenantId);// step2 批量获取6位随机码for (int i=1; i<=5; i++) {// 批量获取随机数。每次重试,取2的指数级量进行过滤,相比暴力执行for循环,这种方式能减少和DB的交互List<String> tempCodes = getRandomCodes(2 << i);// 过滤掉分布式锁filterDistributeLock(tempCodes);// 过滤掉数据库存在的随机码filterExistsCodes(tempCodes);return tempCodes;}// step3 处理随机码,随机码入库for (String code : codes) {// 加锁,判断加锁是否成功。推荐使用Redis分布式锁boolean hasLockd = isLocked(code);try {// 执行入库insert(object);} finally {// 解锁}}// step4 执行后置二维码图片等逻辑
【注意】
推荐使用指数级重试的方式(2 << i),逐次递增random的数量,减少和DB的交互;
建议数字码生成完毕后加锁并执行INSERT,生成图片地址等耗时严重的动作可以后置UPDATE上去。
【问题二】项目中使用了分库分表的组件(比如:ShardingSphere-JDBC),怎么动态修改数据源?也就是同时支持分库分表因子(比如:member_id、open_id等)以及根据取货码计算的库表动态查询。
【解决】我们以ShardingSphere-JDBC作为为案例来给出一些配置及伪代码,具体可以参考:《强制路由::ShardingSphere》,其他开源的分库分表组件或者自研产品不做赘述,可以自己手动写个插件,别怕,即使再难,也要相信有光!
配置及伪代码
ShardingSphere-JDBC依赖的配置文件jdbc-sharding.yaml...shardingRule:tables:...# 取货码表order_code:actualDataNodes: DS00$->{0..3}.order_pick_up_0$->{0..3}# 配置库的计算逻辑databaseStrategy:hint:algorithmClassName: com.xxx.xxxxx.xxx.service.impl.DbHintShardingAlgorithm# 配偶之表的计算逻辑tableStrategy:hint:algorithmClassName: com.xxx.xxxxx.xxx.service.impl.DbHintShardingAlgorithm...java代码try (HintManager hintManager = HintManager.getInstance()) {取货码表 */, DbHintShardingAlgorithm.calDbShardingValue(tenantId, code));取货码表 */, DbHintShardingAlgorithm.calTabShardingValue(tenantId, code));Object xxx = xxxMapper.selectOne(queryDTO);}
【注意】
这里介绍一种编程式的解决方案,好处是配置简单、比较灵活,缺点就是代码稍微多一点。其实ShardingSphere还支持注解的方式,可以自己研究下;
第一条说了比较灵活,体现在自己实现的 “DbHintShardingAlgorithm.calDbShardingValue(tenantId, code)” 方法上,这个方法可以自己定义,所以我们的入参可以是通用的分库分表因子,也可以是自定义的取货码的“库表位置”字段,非常灵活。
【问题三】如何做到更强的扩展性,适用SaaS平台以及不同的业务场景?
【解决】细心的小伙伴应该注意到了 "tenantId" 这个字段,这是个租户的编码,在实际编码会进行透传。我们可以利用这个字段针对不同的租户(或叫业务方)来做不同的配置,比如:取货码的长度、取货码编排的方式、取货码映射库表位置的策略等等做成可配,只要把主干逻辑进一步抽象,并使用策略模式进行个性化编码。
四、总结
实现取货码逻辑的时候,发现网上券码这块的方案、技术文章比较少,当时萌生了写篇文章抛砖引玉做个分享的想法。事实上,我相信大多数公司可能或多或少也是这么做的,哪怕采取了别的方案也能殊途同归。本篇文章整体只是介绍了一个思路,而这个思路类似一个简化版的订单分库分表,但这就是神奇所在,事实上我们还可以将一些常用的技术方案落地到不同的应用场景,大胆地做一些尝试,多走一些未曾设想过的道路!
END
猜你喜欢