作者:微信小助手
发布时间:2022-09-09T11:18:59
背景

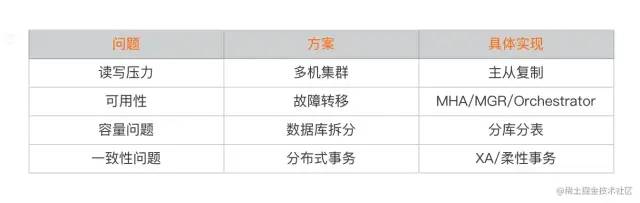
业务飞速发展导致数据规模急速膨胀,单机的数据库已经无法满足互联网业务的发展。
传统的将数据集中存储单一数据结节的方案,在容量、性能、可用性和可维护性方面已经难以满足互联网海量数据的场景。
从容量方面考虑,单机数据库容量有限,难以扩容。
从性能方面来说,由于关系型数据库大多数采用B+树类型索引,在数据量超过一定的阈值后,索引的深度增加导致对磁盘的随机IO次数增加,进而导致性能问题。
从可用性方面来说,服务通常设计成无状态的,这必然导致系统的存储压力都集中在数据库层面,而单一的数据节点,或者简单的主从架构,已经越来越难以承担。
从运维角度来看,当数据都集中在一个节点上时,数据备份和恢复的时间成本也随之数据量上升变得不可控。同时数据丢失导致影响的范围也会被放大。