作者:微信小助手
发布时间:2022-07-26T23:27:30
不知不觉,面渣逆袭系列已经肝了差不多十篇,每一篇都是上万字,几十图,基本上涵盖了面试的主要知识点,这期MySQL结束之后,这个系列可能会暂时告一段落,作为面渣逆袭系列第一阶段的收官之作,大家多多点赞、收藏哦! 作为SQL Boy,基础部分不会有人不会吧?面试也不怎么问,基础掌握不错的小伙伴可以跳过这一部分。当然,可能会现场写一些SQL语句,SQ语句可以通过牛客、LeetCode、LintCode之类的网站来练习。 MySQL的连接主要分为内连接和外连接,外连接常用的有左连接、右连接。 三大范式的作用是为了控制数据库的冗余,是对空间的节省,实际上,一般互联网公司的设计都是反范式的,通过冗余一些数据,避免跨表跨库,利用空间换时间,提高性能。 char: varchar: 日常的设计,对于长度相对固定的字符串,可以使用char,对于长度不确定的,使用varchar更合适一些。 相同点: 区别: 日期范围:DATETIME 的日期范围是 存储空间:DATETIME 的存储空间为 8 字节;TIMESTAMP 的存储空间为 4 字节 时区相关:DATETIME 存储时间与时区无关;TIMESTAMP 存储时间与时区有关,显示的值也依赖于时区 默认值:DATETIME 的默认值为 null;TIMESTAMP 的字段默认不为空(not null),默认值为当前时间(CURRENT_TIMESTAMP) MySQL中的in语句是把外表和内表作hash 连接,而exists语句是对外表作loop循环,每次loop循环再对内表进行查询。我们可能认为exists比in语句的效率要高,这种说法其实是不准确的,要区分情景: 货币在数据库中MySQL常用Decimal和Numric类型表示,这两种类型被MySQL实现为同样的类型。他们被用于保存与货币有关的数据。 例如salary DECIMAL(9,2),9(precision)代表将被用于存储值的总的小数位数,而2(scale)代表将被用于存储小数点后的位数。存储在salary列中的值的范围是从-9999999.99到9999999.99。 DECIMAL和NUMERIC值作为字符串存储,而不是作为二进制浮点数,以便保存那些值的小数精度。 之所以不使用float或者double的原因:因为float和double是以二进制存储的,所以有一定的误差。 MySQL可以直接使用字符串存储emoji。 但是需要注意的,utf8 编码是不行的,MySQL中的utf8是阉割版的 utf8,它最多只用 3 个字节存储字符,所以存储不了表情。那该怎么办? 需要使用utf8mb4编码。 三者都表示删除,但是三者有一些差别: 因此,在不再需要一张表的时候,用drop;在想删除部分数据行时候,用delete;在保留表而删除所有数据的时候用truncate。 执行效果: count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略列值为NULL count(1)包括了忽略所有列,用1代表代码行,在统计结果的时候,不会忽略列值为NULL count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空(这里的空不是只空字符串或者0,而是表示null)的计数,即某个字段值为NULL时,不统计。 执行速度: FROM:对FROM子句中的左表<left_table>和右表<right_table>执行笛卡儿积(Cartesianproduct),产生虚拟表VT1 ON:对虚拟表VT1应用ON筛选,只有那些符合<join_condition>的行才被插入虚拟表VT2中 JOIN:如果指定了OUTER JOIN(如LEFT OUTER JOIN、RIGHT OUTER JOIN),那么保留表中未匹配的行作为外部行添加到虚拟表VT2中,产生虚拟表VT3。如果FROM子句包含两个以上表,则对上一个连接生成的结果表VT3和下一个表重复执行步骤1)~步骤3),直到处理完所有的表为止 WHERE:对虚拟表VT3应用WHERE过滤条件,只有符合<where_condition>的记录才被插入虚拟表VT4中 GROUP BY:根据GROUP BY子句中的列,对VT4中的记录进行分组操作,产生VT5 CUBE|ROLLUP:对表VT5进行CUBE或ROLLUP操作,产生表VT6
基础

1. 什么是内连接、外连接、交叉连接、笛卡尔积呢?
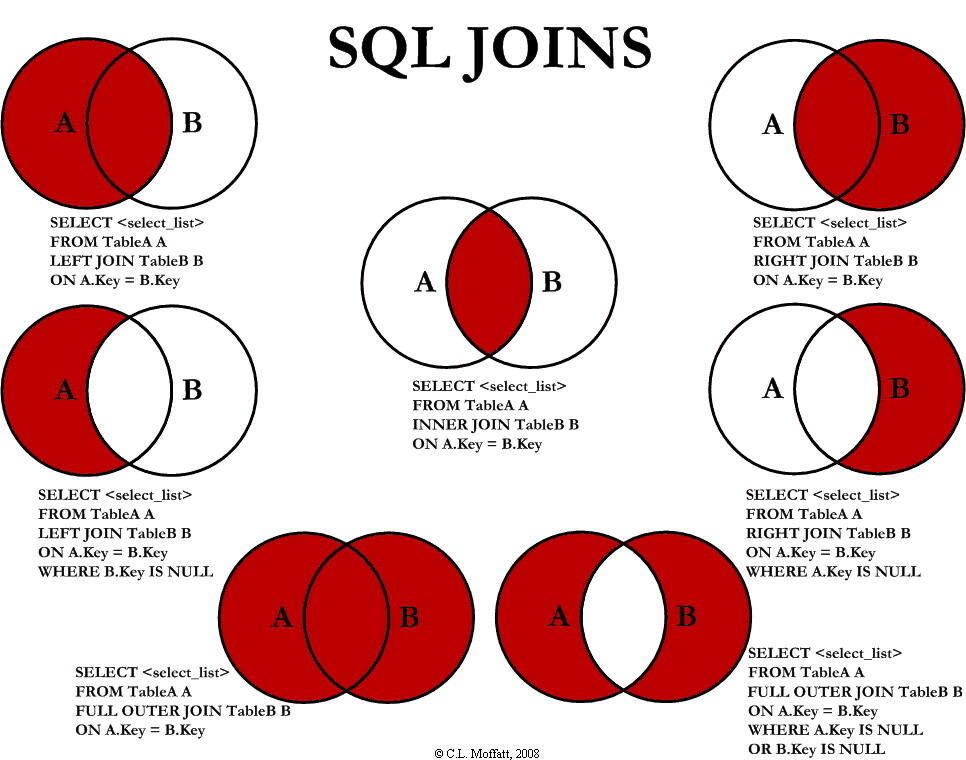
2. 那MySQL 的内连接、左连接、右连接有有什么区别?
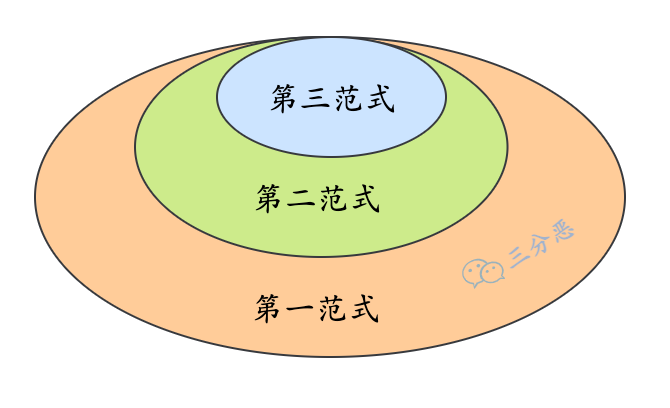
3.说一下数据库的三大范式?

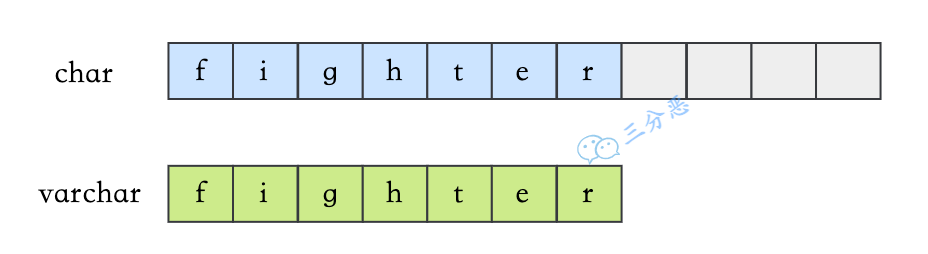
4.varchar与char的区别?
5.blob和text有什么区别?
6.DATETIME和TIMESTAMP的异同?
YYYY-MM-DD HH:MM:SS
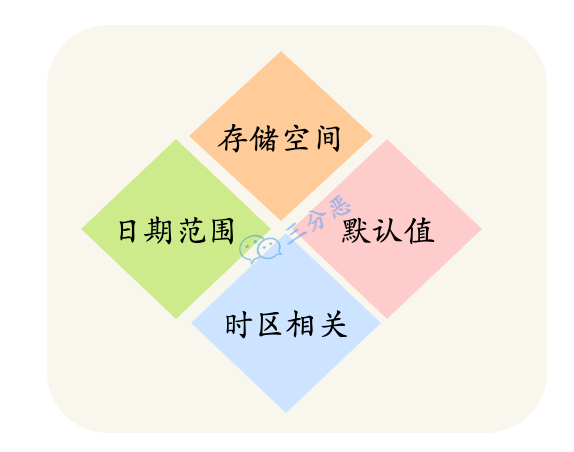
1000-01-01 00:00:00.000000 到 9999-12-31 23:59:59.999999;TIMESTAMP 的时间范围是1970-01-01 00:00:01.000000 UTC 到 ``2038-01-09 03:14:07.999999 UTC7.MySQL中 in 和 exists 的区别?
8.MySQL里记录货币用什么字段类型比较好?
9.MySQL怎么存储emoji😊?
alter table blogs modify content text CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci not null;10.drop、delete与truncate的区别?
delete
truncate
drop
类型
属于DML
属于DDL
属于DDL
回滚
可回滚
不可回滚
不可回滚
删除内容
表结构还在,删除表的全部或者一部分数据行
表结构还在,删除表中的所有数据
从数据库中删除表,所有数据行,索引和权限也会被删除
删除速度
删除速度慢,需要逐行删除
删除速度快
删除速度最快
11.UNION与UNION ALL的区别?
12.count(1)、count(*) 与 count(列名) 的区别?
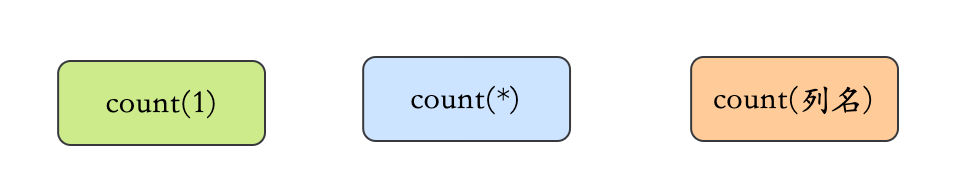
13.一条SQL查询语句的执行顺序?
